Python如何使用KNN進行驗證碼識別-創(chuàng)新互聯(lián)
這篇文章主要介紹Python如何使用KNN進行驗證碼識別,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!

分析
我們學校的驗證碼是這樣的: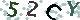 ,其實就是簡單地把字符進行旋轉(zhuǎn)然后加上一些微弱的噪點形成的。我們要識別,就得逆行之,具體思路就是,首先二值化去掉噪點,然后把單個字符分割出來,最后旋轉(zhuǎn)至標準方向,然后從這些處理好的圖片中選出模板,最后每次新來一張驗證碼就按相同方式處理,然后和這些模板進行比較,選擇判別距離最近的一個模板作為其判斷結(jié)果(亦即KNN的思想,本文取K=1)。接下來按步驟進行說明。
,其實就是簡單地把字符進行旋轉(zhuǎn)然后加上一些微弱的噪點形成的。我們要識別,就得逆行之,具體思路就是,首先二值化去掉噪點,然后把單個字符分割出來,最后旋轉(zhuǎn)至標準方向,然后從這些處理好的圖片中選出模板,最后每次新來一張驗證碼就按相同方式處理,然后和這些模板進行比較,選擇判別距離最近的一個模板作為其判斷結(jié)果(亦即KNN的思想,本文取K=1)。接下來按步驟進行說明。
獲得驗證碼
首先得有大量的驗證碼,我們通過爬蟲來實現(xiàn),代碼如下
#-*- coding:UTF-8 -*-
import urllib,urllib2,cookielib,string,Image
def getchk(number):
#創(chuàng)建cookie對象
cookie = cookielib.LWPCookieJar()
cookieSupport= urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(cookieSupport, urllib2.HTTPHandler)
urllib2.install_opener(opener)
#首次與教務(wù)系統(tǒng)鏈接獲得cookie#
#偽裝browser
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip,deflate',
'Accept-Language':'zh-CN,zh;q=0.8',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36'
}
req0 = urllib2.Request(
url ='http://mis.teach.ustc.edu.cn',
headers = headers #請求頭
)
# 捕捉http錯誤
try :
result0 = urllib2.urlopen(req0)
except urllib2.HTTPError,e:
print e.code
#提取cookie
getcookie = ['',]
for item in cookie:
getcookie.append(item.name)
getcookie.append("=")
getcookie.append(item.value)
getcookie = "".join(getcookie)
#修改headers
headers["Origin"] = "http://mis.teach.ustc.edu.cn"
headers["Referer"] = "http://mis.teach.ustc.edu.cn/userinit.do"
headers["Content-Type"] = "application/x-www-form-urlencoded"
headers["Cookie"] = getcookie
for i in range(number):
req = urllib2.Request(
url ="http://mis.teach.ustc.edu.cn/randomImage.do?date='1469451446894'",
headers = headers #請求頭
)
response = urllib2.urlopen(req)
status = response.getcode()
picData = response.read()
if status == 200:
localPic = open("./source/"+str(i)+".jpg", "wb")
localPic.write(picData)
localPic.close()
else:
print "failed to get Check Code "
if __name__ == '__main__':
getchk(500)這里下載了500張驗證碼到source目錄下面。如圖:

二值化
matlab豐富的圖像處理函數(shù)能給我們省下很多時間,,我們遍歷source文件夾,對每一張驗證碼圖片進行二值化處理,把處理過的圖片存入bw目錄下。代碼如下
mydir='./source/'; bw = './bw/'; if mydir(end)~='\' mydir=[mydir,'\']; end DIRS=dir([mydir,'*.jpg']); %擴展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = rgb2gray(img);%灰度化 img = im2bw(img);%0-1二值化 name = strcat(bw,DIRS(i).name) imwrite(img,name); end end
處理結(jié)果如圖:

分割
mydir='./bw/'; letter = './letter/'; if mydir(end)~='\' mydir=[mydir,'\']; end DIRS=dir([mydir,'*.jpg']); %擴展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = im2bw(img);%二值化 img = 1-img;%顏色反轉(zhuǎn)讓字符成為聯(lián)通域,方便去除噪點 for ii = 0:3 region = [ii*20+1,1,19,20];%把一張驗證碼分成四個20*20大小的字符圖片 subimg = imcrop(img,region); imlabel = bwlabel(subimg); % imshow(imlabel); if max(max(imlabel))>1 % 說明有噪點,要去除 % max(max(imlabel)) % imshow(subimg); stats = regionprops(imlabel,'Area'); area = cat(1,stats.Area); maxindex = find(area == max(area)); area(maxindex) = 0; secondindex = find(area == max(area)); imindex = ismember(imlabel,secondindex); subimg(imindex==1)=0;%去掉第二大連通域,噪點不可能比字符大,所以第二大的就是噪點 end name = strcat(letter,DIRS(i).name(1:length(DIRS(i).name)-4),'_',num2str(ii),'.jpg') imwrite(subimg,name); end end end
處理結(jié)果如圖:

旋轉(zhuǎn)
接下來進行旋轉(zhuǎn),哪找一個什么標準呢?據(jù)觀察,這些字符旋轉(zhuǎn)不超過60度,那么在正負60度之間,統(tǒng)一旋轉(zhuǎn)至字符寬度最小就行了。代碼如下
if mydir(end)~='\' mydir=[mydir,'\']; end DIRS=dir([mydir,'*.jpg']); %擴展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = im2bw(img); minwidth = 20; for angle = -60:60 imgr=imrotate(img,angle,'bilinear','crop');%crop 避免圖像大小變化 imlabel = bwlabel(imgr); stats = regionprops(imlabel,'Area'); area = cat(1,stats.Area); maxindex = find(area == max(area)); imindex = ismember(imlabel,maxindex);%大連通域為1 [y,x] = find(imindex==1); width = max(x)-min(x)+1; if width<minwidth minwidth = width; imgrr = imgr; end end name = strcat(rotate,DIRS(i).name) imwrite(imgrr,name); end end
處理結(jié)果如圖,一共2000個字符的圖片存在rotate文件夾中

模板選取
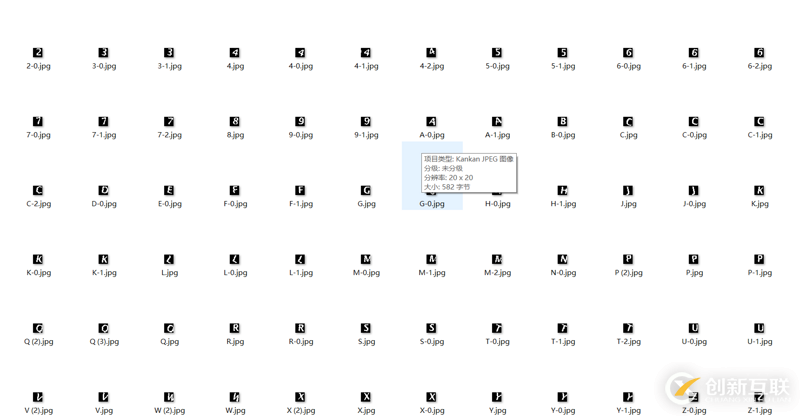
現(xiàn)在從rotate文件夾中選取一套模板,涵蓋每一個字符,一個字符可以選取多個圖片,因為即使有前面的諸多處理也不能保證一個字符的最終呈現(xiàn)形式只有一種,多選幾個才能保證覆蓋率。把選出來的模板圖片存入samples文件夾下,這個過程很耗時耗力。可以找同學幫忙~,如圖
測試
測試代碼如下:首先對測試驗證碼進行上述操作,然后和選出來的模板進行比較,采用差分值最小的模板作為測試樣本的字符選擇,代碼如下
% 具有差分最小值的圖作為答案
mydir='./test/';
samples = './samples/';
if mydir(end)~='\'
mydir=[mydir,'\'];
end
if samples(end)~='\'
samples=[samples,'\'];
end
DIRS=dir([mydir,'*.jpg']); %擴展?
DIRS1=dir([samples,'*.jpg']); %擴展名
n=length(DIRS);%驗證碼總圖數(shù)
singleerror = 0;%單個錯誤
uniterror = 0;%一張驗證碼錯誤個數(shù)
for i=1:n
if ~DIRS(i).isdir
realcodes = DIRS(i).name(1:4);
fprintf('驗證碼實際字符:%s\n',realcodes);
img = imread(strcat(mydir,DIRS(i).name ));
img = rgb2gray(img);
img = im2bw(img);
img = 1-img;%顏色反轉(zhuǎn)讓字符成為聯(lián)通域
subimgs = [];
for ii = 0:3
region = [ii*20+1,1,19,20];%奇怪,為什么這樣才能均分?
subimg = imcrop(img,region);
imlabel = bwlabel(subimg);
if max(max(imlabel))>1 % 說明有雜點
stats = regionprops(imlabel,'Area');
area = cat(1,stats.Area);
maxindex = find(area == max(area));
area(maxindex) = 0;
secondindex = find(area == max(area));
imindex = ismember(imlabel,secondindex);
subimg(imindex==1)=0;%去掉第二大連通域
end
subimgs = [subimgs;subimg];
end
codes = [];
for ii = 0:3
region = [ii*20+1,1,19,20];
subimg = imcrop(img,region);
minwidth = 20;
for angle = -60:60
imgr=imrotate(subimg,angle,'bilinear','crop');%crop 避免圖像大小變化
imlabel = bwlabel(imgr);
stats = regionprops(imlabel,'Area');
area = cat(1,stats.Area);
maxindex = find(area == max(area));
imindex = ismember(imlabel,maxindex);%大連通域為1
[y,x] = find(imindex==1);
width = max(x)-min(x)+1;
if width<minwidth
minwidth = width;
imgrr = imgr;
end
end
mindiffv = 1000000;
for jj = 1:length(DIRS1)
imgsample = imread(strcat(samples,DIRS1(jj).name ));
imgsample = im2bw(imgsample);
diffv = abs(imgsample-imgrr);
alldiffv = sum(sum(diffv));
if alldiffv<mindiffv
mindiffv = alldiffv;
code = DIRS1(jj).name;
code = code(1);
end
end
codes = [codes,code];
end
fprintf('驗證碼測試字符:%s\n',codes);
num = codes-realcodes;
num = length(find(num~=0));
singleerror = singleerror + num;
if num>0
uniterror = uniterror +1;
end
fprintf('錯誤個數(shù):%d\n',num);
end
end
fprintf('\n-----結(jié)果統(tǒng)計如下-----\n\n');
fprintf('測試驗證碼的字符數(shù)量:%d\n',n*4);
fprintf('測試驗證碼的字符錯誤數(shù)量:%d\n',singleerror);
fprintf('單個字符識別正確率:%.2f%%\n',(1-singleerror/(n*4))*100);
fprintf('測試驗證碼圖的數(shù)量:%d\n',n);
fprintf('測試驗證碼圖的錯誤數(shù)量:%d\n',uniterror);
fprintf('填對驗證碼的概率:%.2f%%\n',(1-uniterror/n)*100);結(jié)果:
驗證碼實際字符:2B4E
驗證碼測試字符:2B4F
錯誤個數(shù):1
驗證碼實際字符:4572
驗證碼測試字符:4572
錯誤個數(shù):0
驗證碼實際字符:52CY
驗證碼測試字符:52LY
錯誤個數(shù):1
驗證碼實際字符:83QG
驗證碼測試字符:85QG
錯誤個數(shù):1
驗證碼實際字符:9992
驗證碼測試字符:9992
錯誤個數(shù):0
驗證碼實際字符:A7Y7
驗證碼測試字符:A7Y7
錯誤個數(shù):0
驗證碼實際字符:D993
驗證碼測試字符:D995
錯誤個數(shù):1
驗證碼實際字符:F549
驗證碼測試字符:F5A9
錯誤個數(shù):1
驗證碼實際字符:FMC6
驗證碼測試字符:FMLF
錯誤個數(shù):2
驗證碼實際字符:R4N4
驗證碼測試字符:R4N4
錯誤個數(shù):0
-----結(jié)果統(tǒng)計如下-----
測試驗證碼的字符數(shù)量:40
測試驗證碼的字符錯誤數(shù)量:7
單個字符識別正確率:82.50%
測試驗證碼圖的數(shù)量:10
測試驗證碼圖的錯誤數(shù)量:6
填對驗證碼的概率:40.00%
可見單個字符準確率是比較高的的了,但是綜合準確率還是不行,觀察結(jié)果至,錯誤的字符就是那些易混淆字符,比如E和F,C和L,5和3,4和A等,所以我們能做的事就是增加模板中的樣本數(shù)量,以期盡量減少混淆。
增加了幾十個樣本過后再次試驗,結(jié)果:
驗證碼實際字符:2B4E
驗證碼測試字符:2B4F
錯誤個數(shù):1
驗證碼實際字符:4572
驗證碼測試字符:4572
錯誤個數(shù):0
驗證碼實際字符:52CY
驗證碼測試字符:52LY
錯誤個數(shù):1
驗證碼實際字符:83QG
驗證碼測試字符:83QG
錯誤個數(shù):0
驗證碼實際字符:9992
驗證碼測試字符:9992
錯誤個數(shù):0
驗證碼實際字符:A7Y7
驗證碼測試字符:A7Y7
錯誤個數(shù):0
驗證碼實際字符:D993
驗證碼測試字符:D993
錯誤個數(shù):0
驗證碼實際字符:F549
驗證碼測試字符:F5A9
錯誤個數(shù):1
驗證碼實際字符:FMC6
驗證碼測試字符:FMLF
錯誤個數(shù):2
驗證碼實際字符:R4N4
驗證碼測試字符:R4N4
錯誤個數(shù):0
-----結(jié)果統(tǒng)計如下-----
測試驗證碼的字符數(shù)量:40
測試驗證碼的字符錯誤數(shù)量:5
單個字符識別正確率:87.50%
測試驗證碼圖的數(shù)量:10
測試驗證碼圖的錯誤數(shù)量:4
填對驗證碼的概率:60.00%
可見無論是單個字符識別正確率還是整個驗證碼正確的概率都有了提升。能夠預見:隨著模板數(shù)量的增多,正確率會不斷地提高。
以上是“Python如何使用KNN進行驗證碼識別”這篇文章的所有內(nèi)容,感謝各位的閱讀!希望分享的內(nèi)容對大家有幫助,更多相關(guān)知識,歡迎關(guān)注創(chuàng)新互聯(lián)成都網(wǎng)站設(shè)計公司行業(yè)資訊頻道!
另外有需要云服務(wù)器可以了解下創(chuàng)新互聯(lián)scvps.cn,海內(nèi)外云服務(wù)器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務(wù)器、裸金屬服務(wù)器、高防服務(wù)器、香港服務(wù)器、美國服務(wù)器、虛擬主機、免備案服務(wù)器”等云主機租用服務(wù)以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務(wù)可用性高、性價比高”等特點與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應(yīng)用場景需求。
網(wǎng)頁題目:Python如何使用KNN進行驗證碼識別-創(chuàng)新互聯(lián)
文章分享:http://chinadenli.net/article48/eohep.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供自適應(yīng)網(wǎng)站、靜態(tài)網(wǎng)站、企業(yè)建站、網(wǎng)站改版、企業(yè)網(wǎng)站制作、域名注冊
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 談?wù)劸幊趟枷氲陌l(fā)展-創(chuàng)新互聯(lián)
- Nuxt升級2.0.0時出現(xiàn)的問題(小結(jié))-創(chuàng)新互聯(lián)
- 2、EVE-NG鏡像導入(Dynamipshe和IOL)-創(chuàng)新互聯(lián)
- 十款可以用來編輯html5的軟件-創(chuàng)新互聯(lián)
- centos7安裝iptables防火墻-創(chuàng)新互聯(lián)
- 線性表的本質(zhì)、操作及順序存儲結(jié)構(gòu)(六)-創(chuàng)新互聯(lián)
- NumPy數(shù)組怎么用-創(chuàng)新互聯(lián)

- 粉絲少的微信公眾號還能賺錢嗎? 2014-08-26
- 三四線城市微信公眾號的內(nèi)容如何運營? 2013-12-29
- 企業(yè)微信公眾號小程序制作方法 2021-04-24
- 微信公眾號運營不能忽視的五條法則是什么? 2014-05-28
- 微信公眾號的軟文寫作規(guī)范是什么? 2014-05-25
- 微信公眾號已發(fā)布文章可修改錯別字了! 2022-05-25
- 微信公眾號快速漲粉的小方法有哪些? 2014-05-17
- 如何做好微信公眾號引流? 2014-03-13
- 營銷型公眾號可以刷點擊率嗎? 2014-01-11
- 微信公眾號搜索排名的九大規(guī)則是什么? 2015-09-06
- 哪些行業(yè)適合微信公眾號小程序開發(fā)? 2020-12-25
- 微信公眾號注冊流程 2022-07-24