python爬蟲怎么用session保持登錄?
這篇文章主要介紹了python爬蟲怎么用session保持登錄?,具有一定借鑒價值,需要的朋友可以參考下。希望大家閱讀完這篇文章后大有收獲。下面讓小編帶著大家一起了解一下。
站在用戶的角度思考問題,與客戶深入溝通,找到恩平網(wǎng)站設(shè)計與恩平網(wǎng)站推廣的解決方案,憑借多年的經(jīng)驗,讓設(shè)計與互聯(lián)網(wǎng)技術(shù)結(jié)合,創(chuàng)造個性化、用戶體驗好的作品,建站類型包括:網(wǎng)站建設(shè)、做網(wǎng)站、企業(yè)官網(wǎng)、英文網(wǎng)站、手機(jī)端網(wǎng)站、網(wǎng)站推廣、申請域名、網(wǎng)頁空間、企業(yè)郵箱。業(yè)務(wù)覆蓋恩平地區(qū)。
有很多python的方法可以實現(xiàn)登陸網(wǎng)頁,但是如果需要保持登陸條件下使用網(wǎng)頁的某些功能,則一般需要利用cookie。在所有的實現(xiàn)方法中,Request包是一種相對比較簡潔的方法。
import request
找到目標(biāo)網(wǎng)頁的登陸頁面,在瀏覽器中用右鍵點擊用戶名和密碼區(qū)域“查看網(wǎng)頁源代碼”。在高亮的代碼中找name對應(yīng)的值,通常是"username", "password"。在這個例子中是"email-login" 和"password-login"。
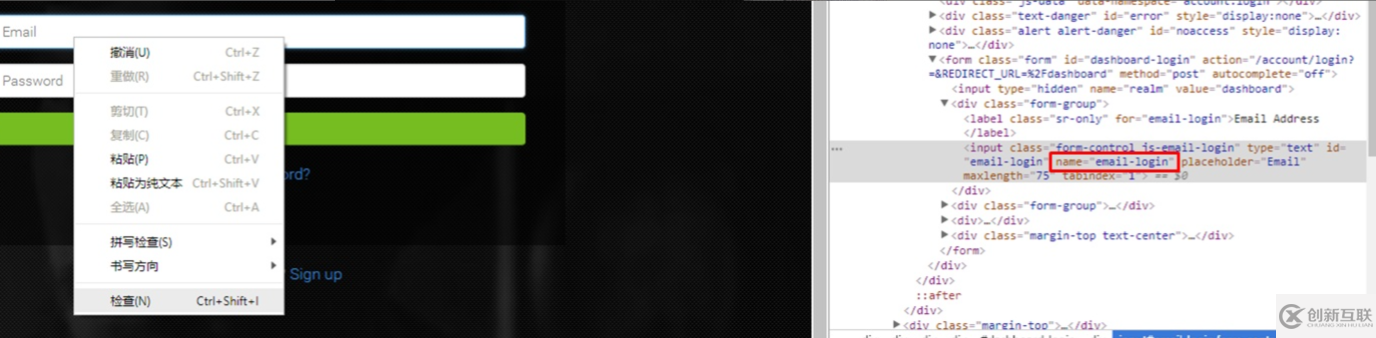
接下來的在代碼中建立一個session,保持登陸狀態(tài)。
s = Session()
s = session.post("登陸頁面的url",
'email-login': “用戶名”,
'password': “密碼”,
#'Token': "某些網(wǎng)站需要token,可以在這里添加"
}之后可以繼續(xù)利用s 這個session來爬取網(wǎng)頁內(nèi)容或者利用api下載文檔。
只要確保完成session的建立,我們的賬戶就會一直處于登陸狀態(tài),當(dāng)然爬蟲也可以繼續(xù)收集數(shù)據(jù)啦。有很多數(shù)據(jù)想要采集,但苦惱于賬號不能一直保持登錄的可以
感謝你能夠認(rèn)真閱讀完這篇文章,希望小編分享python爬蟲怎么用session保持登錄?內(nèi)容對大家有幫助,同時也希望大家多多支持創(chuàng)新互聯(lián),關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道,遇到問題就找創(chuàng)新互聯(lián),詳細(xì)的解決方法等著你來學(xué)習(xí)!
當(dāng)前題目:python爬蟲怎么用session保持登錄?
URL鏈接:http://chinadenli.net/article30/jgpcpo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供微信公眾號、域名注冊、標(biāo)簽優(yōu)化、服務(wù)器托管、網(wǎng)站設(shè)計公司、微信小程序
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 整站優(yōu)化與關(guān)鍵詞優(yōu)化有什么本質(zhì)區(qū)別 2014-10-02
- 同行網(wǎng)站排名始終靠前的重要原因 2016-10-04
- 手機(jī)網(wǎng)站該怎么做優(yōu)化,方法是什么? 2015-09-28
- 網(wǎng)站建設(shè)怎么得到用戶的喜歡?用戶體驗很重要 2013-12-22
- 談?wù)劸W(wǎng)站SEO搜索引擎優(yōu)化以后發(fā)展趨勢 2016-05-16
- 如何在seo優(yōu)化中有效增加網(wǎng)站收錄? 2015-08-07
- 移動端手機(jī)網(wǎng)站SEO優(yōu)化 技巧與注意事項 2016-09-19
- 模板網(wǎng)站和定制網(wǎng)站有什么區(qū)別 2014-12-01
- B2B網(wǎng)站營銷的小技巧 2014-04-26
- 網(wǎng)站搜索引擎優(yōu)化從業(yè)人員的SEO技巧! 2015-12-25
- 停止SEO優(yōu)化工作,網(wǎng)站排名會下滑嗎? 2015-06-22
- 網(wǎng)站排名推廣可用性方法 2013-12-27