mysql架構的原理是什么
本篇內(nèi)容主要講解“MySQL架構的原理是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“mysql架構的原理是什么”吧!
成都創(chuàng)新互聯(lián)主營蒼梧網(wǎng)站建設的網(wǎng)絡公司,主營網(wǎng)站建設方案,App定制開發(fā),蒼梧h5微信小程序開發(fā)搭建,蒼梧網(wǎng)站營銷推廣歡迎蒼梧等地區(qū)企業(yè)咨詢

Mysql 架構原理
1、Mysql體系架構
MySQL Server架構自頂向下大致可以分網(wǎng)絡連接層、服務層、存儲引擎層和系統(tǒng)文件層。
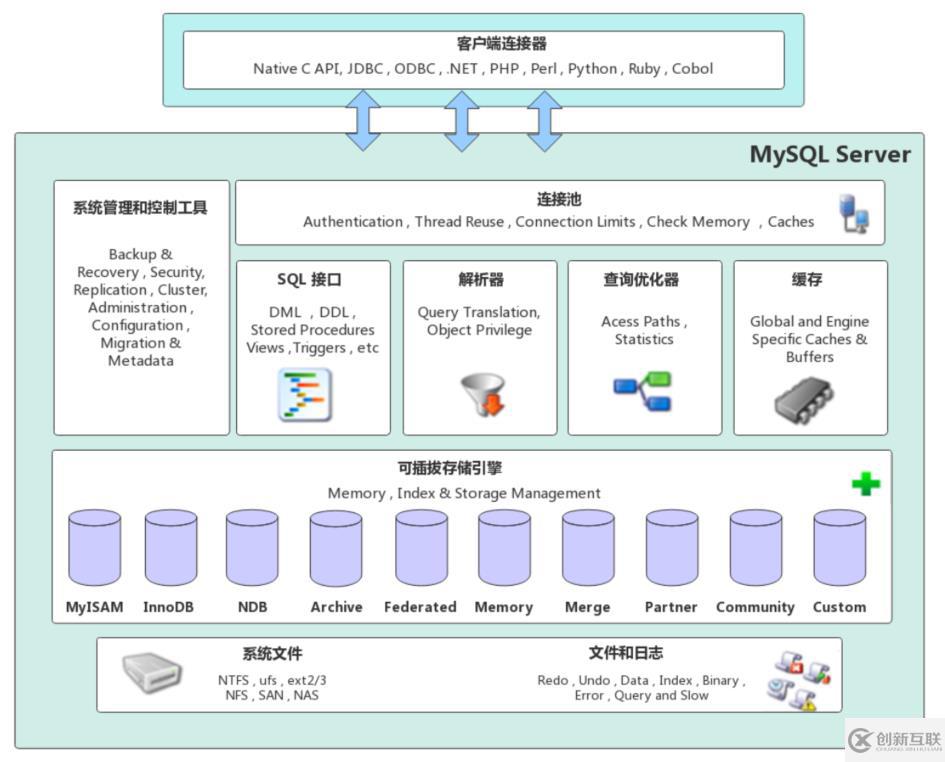
網(wǎng)絡連接層
客戶端連接器(Client Connectors):提供與MySQL服務器建立的支持。目前幾乎支持所有主流的服務端編程技術,例如常見的 Java、C、Python、.NET等,它們通過各自API技術與MySQL建立連接。
服務層(MySQL Server)
服務層是MySQL Server的核心,主要包含系統(tǒng)管理和控制工具、連接池、SQL接口、解析器、查詢優(yōu)化器和緩存六個部分。
連接池(Connection Pool):負責存儲和管理客戶端與數(shù)據(jù)庫的連接,一個線程負責管理一個連接。
系統(tǒng)管理和控制工具(Management Services & Utilities):例如備份恢復、安全管理、集群管理等
SQL接口(SQL Interface):用于接受客戶端發(fā)送的各種SQL命令,并且返回用戶需要查詢的結果。比如DML、DDL、存儲過程、視圖、觸發(fā)器等。
解析器(Parser):負責將請求的SQL解析生成一個"解析樹"。然后根據(jù)一些MySQL規(guī)則進一步檢查解析樹是否合法。
查詢優(yōu)化器(Optimizer):當"解析樹"通過解析器語法檢查后,將交由優(yōu)化器將其轉化成執(zhí)行計劃,然后與存儲引擎交互。
select uid, name from user where gender = 1;
選取 --》投影 --》聯(lián)接 策略
select先根據(jù)where語句進行選取,并不是查詢出全部數(shù)據(jù)再過濾;
select查詢根據(jù)uid和name進行屬性投影,并不是取出所有字段;
將前面選取和投影聯(lián)接起來最終生成查詢結果;
緩存(Cache&Buffer): 緩存機制是由一系列小緩存組成的。比如表緩存,記錄緩存,權限緩存,引擎緩存等。如果查詢緩存有命中的查詢結果,查詢語句就可以直接去查詢緩存中取數(shù)據(jù)。
存儲引擎層(Pluggable Storage Engines)
存儲引擎負責MySQL中數(shù)據(jù)的存儲與提取,與底層系統(tǒng)文件進行交互。MySQL存儲引擎是插件式的,服務器中的查詢執(zhí)行引擎通過接口與存儲引擎進行通信,接口屏蔽了不同存儲引擎之間的差異 。現(xiàn)在有很多種存儲引擎,各有各的特點,最常見的是MyISAM和InnoDB。
系統(tǒng)文件層(File System)
該層負責將數(shù)據(jù)庫的數(shù)據(jù)和日志存儲在文件系統(tǒng)之上,并完成與存儲引擎的交互,是文件的物理存儲層。主要包含日志文件,數(shù)據(jù)文件,配置文件,pid 文件,socket 文件等。
日志文件
記錄所有執(zhí)行時間超時的查詢SQL,默認是10秒。
show variables like ‘%slow_query%’; //是否開啟
show variables like ‘%long_query_time%’; //時長
記錄了對MySQL數(shù)據(jù)庫執(zhí)行的更改操作,并且記錄了語句的發(fā)生時間、執(zhí)行時長;但是它不記錄select、show等不修改數(shù)據(jù)庫的SQL。主要用于數(shù)據(jù)庫恢復和主從復制。
show variables like ‘%log_bin%’; //是否開啟
show variables like ‘%binlog%’; //參數(shù)查看
show binary logs;//查看日志文件
記錄一般查詢語句,show variables like ‘%general%’;
默認開啟,show variables like ‘%log_error%’;
錯誤日志(Error log)
通用查詢?nèi)罩荆℅eneral query log)
二進制日志(binary log)
慢查詢?nèi)罩荆⊿low query log)
配置文件
用于存放MySQL所有的配置信息文件,比如my.cnf、my.ini等。
數(shù)據(jù)文件
db.opt 文件:記錄這個庫的默認使用的字符集和校驗規(guī)則。
frm 文件:存儲與表相關的元數(shù)據(jù)(meta)信息,包括表結構的定義信息等,每一張表都會有一個frm 文件。
MYD 文件:MyISAM 存儲引擎專用,存放 MyISAM 表的數(shù)據(jù)(data),每一張表都會有一個.MYD 文件。
MYI 文件:MyISAM 存儲引擎專用,存放 MyISAM 表的索引相關信息,每一張 MyISAM 表對應一個 .MYI文件。
ibd文件和 IBDATA 文件:存放 InnoDB 的數(shù)據(jù)文件(包括索引)。InnoDB 存儲引擎有兩種表空間方式:獨享表空間和共享表空間。獨享表空間使用 .ibd 文件來存放數(shù)據(jù),且每一張InnoDB 表對應一個 .ibd 文件。共享表空間使用 .ibdata 文件,所有表共同使用一個(或多個,自行配置).ibdata 文件。
ibdata1 文件:系統(tǒng)表空間數(shù)據(jù)文件,存儲表元數(shù)據(jù)、Undo日志等 。
ib_logfile0、ib_logfile1 文件:Redo log 日志文件。
pid 文件
pid 文件是 mysqld 應用程序在 Unix/Linux 環(huán)境下的一個進程文件,和許多其他 Unix/Linux 服務端程序一樣,它存放著自己的進程 id。
socket 文件
socket 文件也是在 Unix/Linux 環(huán)境下才有的,用戶在 Unix/Linux 環(huán)境下客戶端連接可以不通過TCP/IP 網(wǎng)絡而直接使用 Unix Socket 來連接 MySQL。
2、MySQL運行機制
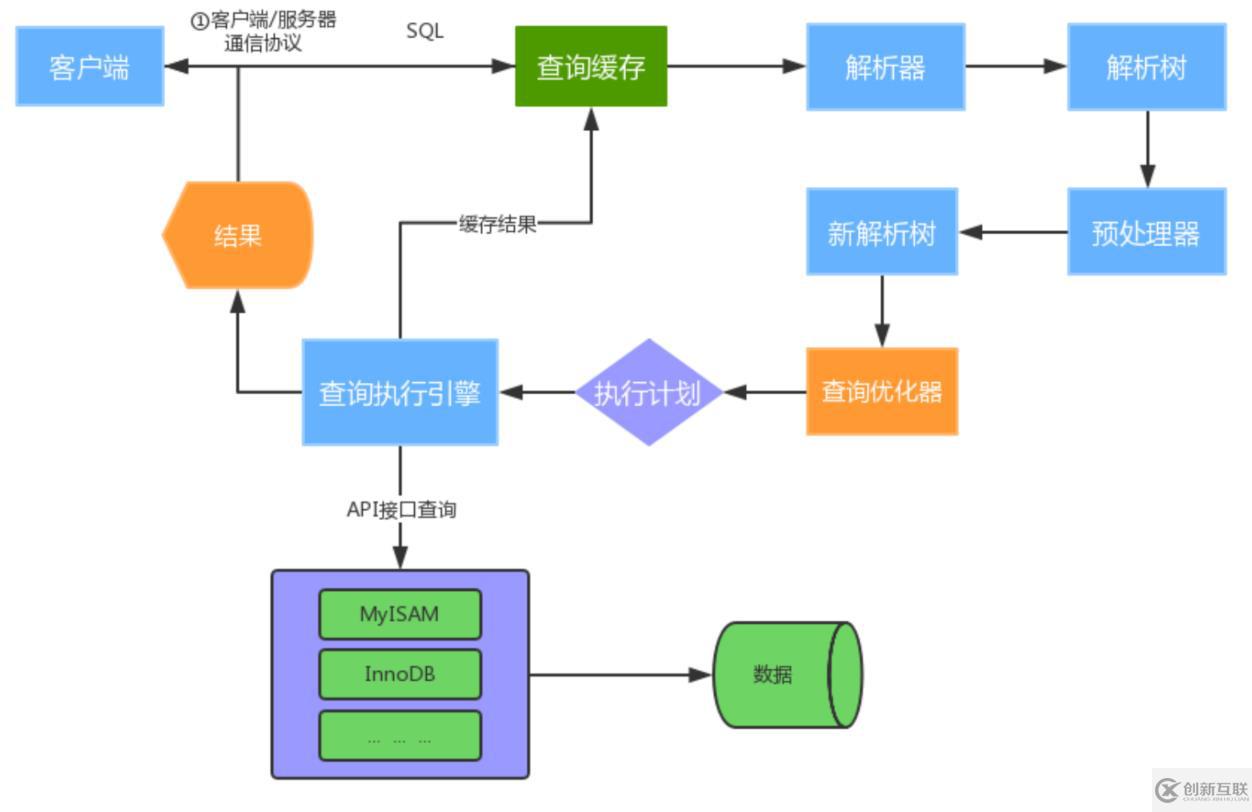
建立連接(Connectors&Connection Pool),通過客戶端/服務器通信協(xié)議與MySQL建立連接。MySQL 客戶端與服務端的通信方式是 “ 半雙工 ”。對于每一個 MySQL 的連接,時刻都有一個線程狀態(tài)來標識這個連接正在做什么。
id:線程ID,可以使用kill xx;
user:啟動這個線程的用戶
Host:發(fā)送請求的客戶端的IP和端口號
db:當前命令在哪個庫執(zhí)行
Command:該線程正在執(zhí)行的操作命令
Time:表示該線程處于當前狀態(tài)的時間,單位是秒
State:線程狀態(tài)
Info:一般記錄線程執(zhí)行的語句,默認顯示前100個字符。想查看完整的使用show full processlist;
Create DB:正在創(chuàng)建庫操作
Drop DB:正在刪除庫操作
Execute:正在執(zhí)行一個PreparedStatement
Close Stmt:正在關閉一個PreparedStatement
Query:正在執(zhí)行一個語句
Sleep:正在等待客戶端發(fā)送語句
Quit:正在退出
Shutdown:正在關閉服務器
Updating:正在搜索匹配記錄,進行修改
Sleeping:正在等待客戶端發(fā)送新請求
Starting:正在執(zhí)行請求處理
Checking table:正在檢查數(shù)據(jù)表
Closing table : 正在將表中數(shù)據(jù)刷新到磁盤中
Locked:被其他查詢鎖住了記錄
Sending Data:正在處理Select查詢,同時將結果發(fā)送給客戶端
全雙工:能同時發(fā)送和接收數(shù)據(jù),例如平時打電話。
半雙工:指的某一時刻,要么發(fā)送數(shù)據(jù),要么接收數(shù)據(jù),不能同時。例如早期對講機
單工:只能發(fā)送數(shù)據(jù)或只能接收數(shù)據(jù)。例如單行道;
通訊機制:
線程狀態(tài):show processlist; //查看用戶正在運行的線程信息,root用戶能查看所有線程,其他用戶只能看自己的;
查詢緩存(Cache&Buffer),這是MySQL的一個可優(yōu)化查詢的地方,如果開啟了查詢緩存且在查詢緩存過程中查詢到完全相同的SQL語句,則將查詢結果直接返回給客戶端;如果沒有開啟查詢緩存或者沒有查詢到完全相同的 SQL 語句則會由解析器進行語法語義解析,并生成“解析樹”。
查詢語句使用SQL_NO_CACHE
查詢的結果大于query_cache_limit設置
查詢中有一些不確定的參數(shù),比如now()
緩存Select查詢的結果和SQL語句;
執(zhí)行Select查詢時,先查詢緩存,判斷是否存在可用的記錄集,要求是否完全相同(包括參數(shù)值),這樣才會匹配緩存數(shù)據(jù)命中;
即使開啟查詢緩存,以下SQL也不能緩存:
show variables like ‘%query_cache%’; //查看查詢緩存是否啟用,空間大小,限制等
show status like ‘Qcache%’; //查看更詳細的緩存參數(shù),可用緩存空間,緩存塊,緩存多少等
解析器(Parser)將客戶端發(fā)送的SQL進行語法解析,生成"解析樹"。預處理器根據(jù)一些MySQL規(guī)則進一步檢查“解析樹”是否合法,例如這里將檢查數(shù)據(jù)表和數(shù)據(jù)列是否存在,還會解析名字和別名,看看它們是否有歧義,最后生成新的“解析樹”。
查詢優(yōu)化器(Optimizer)根據(jù)“解析樹”生成最優(yōu)的執(zhí)行計劃。MySQL使用很多優(yōu)化策略生成最優(yōu)的執(zhí)行計劃,可以分為兩類:靜態(tài)優(yōu)化(編譯時優(yōu)化)、動態(tài)優(yōu)化(運行時優(yōu)化)。
MySQL對 in 查詢,會先進行排序,再采用二分法查找數(shù)據(jù)。比如where id in (2,1,3),變成 in (1,2,3);
使用了limit查詢,獲取limit所需的數(shù)據(jù),就不在繼續(xù)遍歷后面數(shù)據(jù)
InnoDB引擎min函數(shù)只需要找索引最左邊
InnoDB引擎max函數(shù)只需要找索引最右邊
MyISAM引擎count(*),不需要計算,直接返回
5=5 and a>5 改成 a > 5
a < b and a=5 改成b>5 and a=5
基于聯(lián)合索引,調(diào)整條件位置等
等價變換策略
優(yōu)化count、min、max等函數(shù)
提前終止查詢
in的優(yōu)化
查詢執(zhí)行引擎負責執(zhí)行 SQL 語句,此時查詢執(zhí)行引擎會根據(jù) SQL 語句中表的存儲引擎類型,以及對應的API接口與底層存儲引擎緩存或者物理文件的交互,得到查詢結果并返回給客戶端。若開啟用查詢緩存,這時會將SQL 語句和結果完整地保存到查詢緩存(Cache&Buffffer)中,以后若有相同的 SQL 語句執(zhí)行則直接返回結果。
select * from test where age > 10;
調(diào)用 InnoDB 引擎接口取這個表的第一行,判斷 age 值是不是 10,如果不是則跳過,如果是則將這行存在結果集中;
調(diào)用引擎接口取“下一行”,重復相同的判斷邏輯,直到取到這個表的最后一行。
執(zhí)行器將上述遍歷過程中所有滿足條件的行組成的記錄集作為結果集返回給客戶端。
如果開啟了查詢緩存,先將查詢結果做緩存操作
返回結果過多,采用增量模式返回
開始執(zhí)行的時候,要先判斷一下你對這個表 T 有沒有執(zhí)行查詢的權限,如果沒有,就會返回沒有權限的錯誤,(如果命中查詢緩存,會在查詢緩存返回結果的時候,做權限驗證。查詢也會在優(yōu)化器之前調(diào)用 precheck 驗證權限)。
如果有權限,就打開表繼續(xù)執(zhí)行。打開表的時候,執(zhí)行器就會根據(jù)表的引擎定義,去使用這個引擎提供的接口。執(zhí)行器的執(zhí)行流程是這樣的:
3、Mysql存儲引擎
存儲引擎在MySQL的體系架構中位于第三層,負責MySQL中的數(shù)據(jù)的存儲和提取,是與文件打交道的子系統(tǒng),它是根據(jù)MySQL提供的文件訪問層抽象接口定制的一種文件訪問機制,這種機制就叫作存儲引擎。
使用show engines命令,就可以查看當前數(shù)據(jù)庫支持的引擎信息。
在5.5版本之前默認采用MyISAM存儲引擎,從5.5開始采用InnoDB存儲引擎。
InnoDB:支持事務,具有提交,回滾和崩潰恢復能力,事務安全;
MyISAM:不支持事務和外鍵,訪問速度快;
Memory:利用內(nèi)存創(chuàng)建表,訪問速度非常快,因為數(shù)據(jù)在內(nèi)存,而且默認使用Hash索引,但是一旦關閉,數(shù)據(jù)就會丟失;
Archive:歸檔類型引擎,僅能支持insert和select語句;
Csv:以CSV文件進行數(shù)據(jù)存儲,由于文件限制,所有列必須強制指定not null,另外CSV引擎也不支持索引和分區(qū),適合做數(shù)據(jù)交換的中間表;
BlackHole: 黑洞,只進不出,進來消失,所有插入數(shù)據(jù)都不會保存;
Federated:可以訪問遠端MySQL數(shù)據(jù)庫中的表。一個本地表,不保存數(shù)據(jù),訪問遠程表內(nèi)容。
MRG_MyISAM:一組MyISAM表的組合,這些MyISAM表必須結構相同,Merge表本身沒有數(shù)據(jù),對Merge操作可以對一組MyISAM表進行操作;
InnoDB和MyISAM對比
事務和外鍵
InnoDB支持事務和外鍵,具有安全性和完整性,適合大量insert或update操作
MyISAM不支持事務和外鍵,它提供高速存儲和檢索,適合大量的select查詢操作
鎖機制
InnoDB支持行級鎖,鎖定指定記錄。基于索引來加鎖實現(xiàn)。
MyISAM支持表級鎖,鎖定整張表。
索引結構
InnoDB使用聚集索引(聚簇索引),索引和記錄在一起存儲,既緩存索引,也緩存記錄。
MyISAM使用非聚集索引(非聚簇索引),索引和記錄分開。
并發(fā)處理能力
MyISAM使用表鎖,會導致寫操作并發(fā)率低,讀之間并不阻塞,讀寫阻塞。
InnoDB讀寫阻塞可以與隔離級別有關,可以采用多版本并發(fā)控制(MVCC)來支持高并發(fā)
存儲文件
InnoDB表對應兩個文件,一個.frm表結構文件,一個.ibd數(shù)據(jù)文件。InnoDB表最大支持64TB;
MyISAM表對應三個文件,一個.frm表結構文件,一個MYD表數(shù)據(jù)文件,一個.MYI索引文件。從
MySQL5.0開始默認限制是256TB。適用場景
需要事務支持(具有較好的事務特性)
行級鎖定對高并發(fā)有很好的適應能力
數(shù)據(jù)更新較為頻繁的場景
數(shù)據(jù)一致性要求較高
硬件設備內(nèi)存較大,可以利用InnoDB較好的緩存能力來提高內(nèi)存利用率,減少磁盤IO
不需要事務支持(不支持)
并發(fā)相對較低(鎖定機制問題)
數(shù)據(jù)修改相對較少,以讀為主
數(shù)據(jù)一致性要求不高
MyISAM
InnoDB
總結
是否需要事務?有,InnoDB
是否存在并發(fā)修改?有,InnoDB
是否追求快速查詢,且數(shù)據(jù)修改少?是,MyISAM
在絕大多數(shù)情況下,推薦使用InnoDB
兩種引擎該如何選擇?
InnoDB存儲結構
從MySQL 5.5版本開始默認使用InnoDB作為引擎,它擅長處理事務,具有自動崩潰恢復的特性。下面是官方的InnoDB引擎架構圖,主要分為內(nèi)存結構和磁盤結構兩大部分。
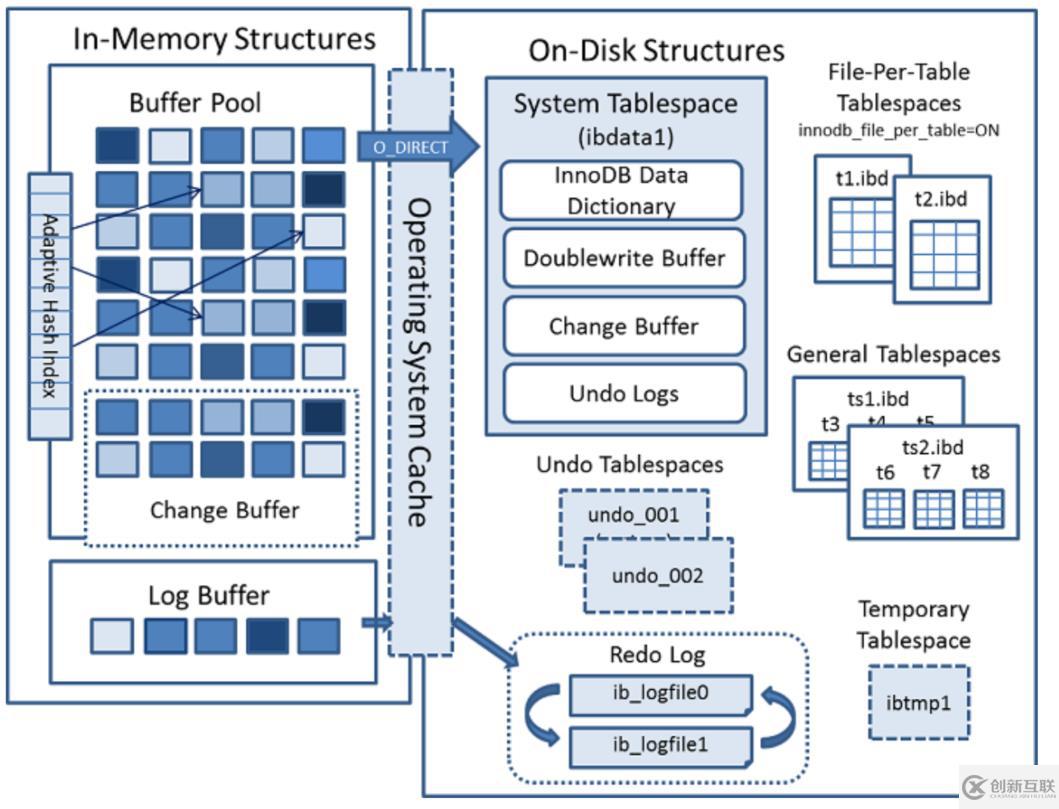
InnoDB內(nèi)存結構
內(nèi)存結構主要包括Buffer Pool、Change Buffer、Adaptive Hash Index和Log Buffer四大組件。
Buffer Pool:緩沖池,簡稱BP。BP以Page頁為單位,默認大小16K,BP的底層采用鏈表數(shù)據(jù)結構管理Page。在InnoDB訪問表記錄和索引時會在Page頁中緩存,以后使用可以減少磁盤IO操作,提升效率。
show variables like ‘%innodb_page_size%’; //查看page頁大小
show variables like ‘%innodb_old%’; //查看lru list中old列表參數(shù)
show variables like ‘%innodb_buffer%’; //查看buffffer pool參數(shù)
建議:將innodb_buffer_pool_size設置為總內(nèi)存大小的60%-80%,innodb_buffer_pool_instances可以設置為多個,這樣可以避免緩存爭奪。
普通LRU:末尾淘汰法,新數(shù)據(jù)從鏈表頭部加入,釋放空間時從末尾淘汰
改性LRU:鏈表分為new和old兩個部分,加入元素時并不是從表頭插入,而是從中間midpoint位置插入,如果數(shù)據(jù)很快被訪問,那么page就會向new列表頭部移動,如果數(shù)據(jù)沒有被訪問,會逐步向old尾部移動,等待淘汰。
每當有新的page數(shù)據(jù)讀取到buffer pool時,InnoDb引擎會判斷是否有空閑頁,是否足夠,如果有就將free page從free list列表刪除,放入到LRU列表中。沒有空閑頁,就會根據(jù)LRU算法淘汰LRU鏈表默認的頁,將內(nèi)存空間釋放分配給新的頁。
Page根據(jù)狀態(tài)可以分為三種類型:
針對上述三種page類型,InnoDB通過三種鏈表結構來維護和管理:
Page管理機制
改進型LRU算法維護
Buffer Pool配置參數(shù)
free page : 空閑page,未被使用
clean page:被使用page,數(shù)據(jù)沒有被修改過
dirty page:臟頁,被使用page,數(shù)據(jù)被修改過,頁中數(shù)據(jù)和磁盤的數(shù)據(jù)產(chǎn)生了不一致
free list :表示空閑緩沖區(qū),管理free page
flush list:表示需要刷新到磁盤的緩沖區(qū),管理dirty page,內(nèi)部page按修改時間排序。臟頁即存在于flush鏈表,也在LRU鏈表中,但是兩種互不影響,LRU鏈表負責管理page的可用性和放,而flush鏈表負責管理臟頁的刷盤操作。
lru list:表示正在使用的緩沖區(qū),管理clean page和dirty page,緩沖區(qū)以midpoint為基點,前面鏈表稱為new列表區(qū),存放經(jīng)常訪問的數(shù)據(jù),占63%;后面的鏈表稱為old列表區(qū),存放使用較少數(shù)據(jù),占37%。
Change Buffer:寫緩沖區(qū),簡稱CB。在進行DML操作時,如果BP沒有其相應的Page數(shù)據(jù),并不會立刻將磁盤頁加載到緩沖池,而是在CB記錄緩沖變更,等未來數(shù)據(jù)被讀取時,再將數(shù)據(jù)合并恢復到BP中。
ChangeBuffer占用BufferPool空間,默認占25%,最大允許占50%,可以根據(jù)讀寫業(yè)務量來進行調(diào)整。參數(shù)innodb_change_buffer_max_size;
當更新一條記錄時,該記錄在BufferPool存在,直接在BufferPool修改,一次內(nèi)存操作。如果該記錄在BufferPool不存在(沒有命中),會直接在ChangeBuffer進行一次內(nèi)存操作,不用再去磁盤查詢數(shù)據(jù),避免一次磁盤IO。當下次查詢記錄時,會先進性磁盤讀取,然后再從ChangeBuffer中讀取信息合并,最終載入BufferPool中。
寫緩沖區(qū),僅適用于非唯一普通索引頁
如果在索引設置唯一性,在進行修改時,InnoDB必須要做唯一性校驗,因此必須查詢磁盤,做一次IO操作。會直接將記錄查詢到BufferPool中,然后在緩沖池修改,不會在ChangeBuffer操作。
Adaptive Hash Index:自適應哈希索引,用于優(yōu)化對BP數(shù)據(jù)的查詢。InnoDB存儲引擎會監(jiān)控對表索引的查找,如果觀察到建立哈希索引可以帶來速度的提升,則建立哈希索引,所以稱之為自適應。InnoDB存儲引擎會自動根據(jù)訪問的頻率和模式來為某些頁建立哈希索引。
Log Buffer:日志緩沖區(qū),用來保存要寫入磁盤上log文件(Redo/Undo)的數(shù)據(jù),日志緩沖區(qū)的內(nèi)容定期刷新到磁盤log文件中。日志緩沖區(qū)滿時會自動將其刷新到磁盤,當遇到BLOB或多行更新的大事務操作時,增加日志緩沖區(qū)可以節(jié)省磁盤I/O。
0 : 每隔1秒寫日志文件和刷盤操作(寫日志文件LogBuffer --> OS cache,刷盤OScache --> 磁盤文件),最多丟失1秒數(shù)據(jù)
1:事務提交,立刻寫日志文件和刷盤,數(shù)據(jù)不丟失,但是會頻繁IO操作
2:事務提交,立刻寫日志文件,每隔1秒鐘進行刷盤操作
LogBuffer主要是用于記錄InnoDB引擎日志,在DML操作時會產(chǎn)生Redo和Undo日志;
LogBuffer空間滿了,會自動寫入磁盤。可以通過將innodb_log_buffer_size參數(shù)調(diào)大,減少磁盤IO頻率;
innodb_flush_log_at_trx_commit參數(shù)控制日志刷新行為,默認為1
InnoDB磁盤結構
InnoDB磁盤主要包含Tablespaces,InnoDB Data Dictionary,Doublewrite Buffer、Redo Log和Undo Logs。
表空間(Tablespaces):用于存儲表結構和數(shù)據(jù)。表空間又分為系統(tǒng)表空間、獨立表空間、通用表空間、臨時表空間、Undo表空間等多種類型;
分為session temporary tablespaces 和global temporary tablespace兩種:
撤銷表空間由一個或多個包含Undo日志文件組成。在MySQL 5.7版本之前Undo占用的是System Tablespace共享區(qū),從5.7開始將Undo從System Tablespace分離了出來。
InnoDB使用的undo表空間由innodb_undo_tablespaces配置選項控制,默認為0。參數(shù)值為0表示使用系統(tǒng)表空間ibdata1;大于0表示使用undo表空間undo_001、undo_002等。
通用表空間為通過create tablespace語法創(chuàng)建的共享表空間。通用表空間可以創(chuàng)建于mysql數(shù)據(jù)目錄外的其他表空間,其可以容納多張表,且其支持所有的行格式。
默認開啟,獨立表空間是一個單表表空間,該表創(chuàng)建于自己的數(shù)據(jù)文件中,而非創(chuàng)建于系統(tǒng)表空間中。當innodb_file_per_table選項開啟時,表將被創(chuàng)建于表空間中。否則,innodb將被創(chuàng)建于系統(tǒng)表空間中。每個表文件表空間由一個.ibd數(shù)據(jù)文件代表,該文件默認被創(chuàng)建于數(shù)據(jù)庫目錄中。表空間的表文件支持動態(tài)(dynamic)和壓縮(commpressed)行格式。
包含InnoDB數(shù)據(jù)字典,Doublewrite Buffer,Change Buffer,Undo Logs的存儲區(qū)域。系統(tǒng)表空間也默認包含任何用戶在系統(tǒng)表空間創(chuàng)建的表數(shù)據(jù)和索引數(shù)據(jù)。系統(tǒng)表空間是一個共享的表空間因為它是被多個表共享的。該空間的數(shù)據(jù)文件通過參數(shù)innodb_data_file_path控制,默認值是ibdata1:12M:autoextend(文件名為ibdata1、12MB、自動擴展)。
CREATE TABLESPACE ts1 ADD DATAFILE ts1.ibd Engine=InnoDB; //創(chuàng)建表空 間ts1 CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1; //將表添加到ts1 表空間
系統(tǒng)表空間(The System Tablespace)
獨立表空間(File-Per-Table Tablespaces)
通用表空間(General Tablespaces)
撤銷表空間(Undo Tablespaces)
臨時表空間(Temporary Tablespaces)
session temporary tablespaces 存儲的是用戶創(chuàng)建的臨時表和磁盤內(nèi)部的臨時表。
global temporary tablespace儲存用戶臨時表的回滾段(rollback segments )。mysql服務器正常關閉或異常終止時,臨時表空間將被移除,每次啟動時會被重新創(chuàng)建。
數(shù)據(jù)字典(InnoDB Data Dictionary)
InnoDB數(shù)據(jù)字典由內(nèi)部系統(tǒng)表組成,這些表包含用于查找表、索引和表字段等對象的元數(shù)據(jù)。元數(shù)據(jù)物理上位于InnoDB系統(tǒng)表空間中。由于歷史原因,數(shù)據(jù)字典元數(shù)據(jù)在一定程度上與InnoDB表元數(shù)據(jù)文件(.frm文件)中存儲的信息重疊。
雙寫緩沖區(qū)(Doublewrite Buffer)
MySQL的innodb_flush_method這個參數(shù)控制著innodb數(shù)據(jù)文件及redo log的打開、刷寫模式。有三個值:fdatasync(默認),O_DSYNC,O_DIRECT。設置O_DIRECT表示數(shù)據(jù)文件寫入操作會通知操作系統(tǒng)不要緩存數(shù)據(jù),也不要用預讀,直接從InnodbBuffer寫到磁盤文件。
默認的fdatasync意思是先寫入操作系統(tǒng)緩存,然后再調(diào)用fsync()函數(shù)去異步刷數(shù)據(jù)文件與redo log的緩存信息。
位于系統(tǒng)表空間,是一個存儲區(qū)域。在BufferPage的page頁刷新到磁盤真正的位置前,會先將數(shù)據(jù)存在Doublewrite 緩沖區(qū)。如果在page頁寫入過程中出現(xiàn)操作系統(tǒng)、存儲子系統(tǒng)或mysqld進程崩潰,InnoDB可以在崩潰恢復期間從Doublewrite 緩沖區(qū)中找到頁面的一個好備份。在大多數(shù)情況下,默認情況下啟用雙寫緩沖區(qū),要禁用Doublewrite 緩沖區(qū),可以將innodb_doublewrite設置為0。使用Doublewrite 緩沖區(qū)時建議將innodb_flush_method設置為O_DIRECT。
重做日志(Redo Log)
重做日志是一種基于磁盤的數(shù)據(jù)結構,用于在崩潰恢復期間更正不完整事務寫入的數(shù)據(jù)。MySQL以循環(huán)方式寫入重做日志文件,記錄InnoDB中所有對Buffer Pool修改的日志。當出現(xiàn)實例故障(像斷電),導致數(shù)據(jù)未能更新到數(shù)據(jù)文件,則數(shù)據(jù)庫重啟時須redo,重新把數(shù)據(jù)更新到數(shù)據(jù)文件。讀寫事務在執(zhí)行的過程中,都會不斷的產(chǎn)生redo log。默認情況下,重做日志在磁盤上由兩個名為ib_logfile0和ib_logfile1的文件物理表示。
撤銷日志(Undo Logs)
撤消日志是在事務開始之前保存的被修改數(shù)據(jù)的備份,用于例外情況時回滾事務。撤消日志屬于邏輯日志,根據(jù)每行記錄進行記錄。撤消日志存在于系統(tǒng)表空間、撤消表空間和臨時表空間中。
新版本結構演變

MySQL 5.7 版本
將 Undo日志表空間從共享表空間 ibdata 文件中分離出來,可以在安裝 MySQL 時由用戶自行指定文件大小和數(shù)量。
增加了 temporary 臨時表空間,里面存儲著臨時表或臨時查詢結果集的數(shù)據(jù)。
Buffer Pool 大小可以動態(tài)修改,無需重啟數(shù)據(jù)庫實例。
MySQL 8.0 版本
將InnoDB表的數(shù)據(jù)字典和Undo都從共享表空間ibdata中徹底分離出來了,以前需要ibdata中數(shù)據(jù)字典與獨立表空間ibd文件中數(shù)據(jù)字典一致才行,8.0版本就不需要了。
temporary 臨時表空間也可以配置多個物理文件,而且均為 InnoDB 存儲引擎并能創(chuàng)建索引,這樣加快了處理的速度。
用戶可以像 Oracle 數(shù)據(jù)庫那樣設置一些表空間,每個表空間對應多個物理文件,每個表空間可以給多個表使用,但一個表只能存儲在一個表空間中。
將Doublewrite Buffer從共享表空間ibdata中也分離出來了。
InnoDB線程模型

IO Thread
read thread : 負責讀取操作,將數(shù)據(jù)從磁盤加載到緩存page頁。4個
write thread:負責寫操作,將緩存臟頁刷新到磁盤。4個
log thread:負責將日志緩沖區(qū)內(nèi)容刷新到磁盤。1個
insert buffer thread :負責將寫緩沖內(nèi)容刷新到磁盤。1個
在InnoDB中使用了大量的AIO(Async IO)來做讀寫處理,這樣可以極大提高數(shù)據(jù)庫的性能。在
InnoDB共有10個IO Thread,分別是4個write,4個read,1個insert buffer和 1個log thread。Purge Thread
事務提交之后,其使用的undo日志將不再需要,因此需要Purge Thread回收已經(jīng)分配的undo頁。
show variables like ‘%innodb_purge_threads%’;
Page Cleaner Thread
作用是將臟數(shù)據(jù)刷新到磁盤,臟數(shù)據(jù)刷盤后相應的redo log也就可以覆蓋,即可以同步數(shù)據(jù),又能
達到redo log循環(huán)使用的目的。會調(diào)用write thread線程處理。show variables like ‘%innodb_page_cleaners%’;
Master Thread
刷新臟頁數(shù)據(jù)到磁盤
合并寫緩沖區(qū)數(shù)據(jù)
刷新日志緩沖區(qū)
刪除無用的undo頁
刷新日志緩沖區(qū),刷到磁盤
合并寫緩沖區(qū)數(shù)據(jù),根據(jù)IO讀寫壓力來決定是否操作
刷新臟頁數(shù)據(jù)到磁盤,根據(jù)臟頁比例達到75%才操作(innodb_max_dirty_pages_pct,
innodb_io_capacity)Master thread是InnoDB的主線程,負責調(diào)度其他各線程,優(yōu)先級最高。作用是將緩沖池中的數(shù)據(jù)異步刷新到磁盤 ,保證數(shù)據(jù)的一致性。包含:臟頁的刷新(page cleaner thread)、undo頁回收(purge thread)、redo日志刷新(log thread)、合并寫緩沖等。內(nèi)部有兩個主處理,分別是每隔1秒和10秒處理。
每1秒的操作:
每10秒的操作:
InnoDB數(shù)據(jù)文件
InnoDB文件存儲結構

InnoDB數(shù)據(jù)文件存儲結構
Tablesapce表空間,用于存儲多個ibd數(shù)據(jù)文件,用于存儲表的記錄和索引。一個文件包含多個段。
Segment段,用于管理多個Extent,分為數(shù)據(jù)段(Leaf node segment)、索引段(Non-leaf node
segment)、回滾段(Rollback segment)。一個表至少會有兩個segment,一個管理數(shù)據(jù),一個管理索引。每多創(chuàng)建一個索引,會多兩個segment。Extent區(qū),一個區(qū)固定包含64個連續(xù)的頁,大小為1M。當表空間不足,需要分配新的頁資源,不會
一頁一頁分,直接分配一個區(qū)。Page頁,用于存儲多個Row行記錄,大小為16K。包含很多種頁類型,比如數(shù)據(jù)頁,undo頁,系統(tǒng)頁,事務數(shù)據(jù)頁,大的BLOB對象頁。
Row行,包含了記錄的字段值,事務ID(Trx id)、滾動指針(Roll pointer)、字段指針(Field
pointers)等信息。分為 ibd數(shù)據(jù)文件 --> Segment(段)–>Extent(區(qū))–> Page(頁)–>Row(行)
Page是文件最基本的單位,無論何種類型的page,都是由page header,page trailer和page body組成。如下圖所示

InnoDB文件存儲格式
一般情況下,如果row_format為REDUNDANT、COMPACT,文件格式為Antelope;如果row_format為DYNAMIC和COMPRESSED,文件格式為Barracuda。
通過information_schema查看指定表的文件格式
select * from information_schema.innodb_sys_tables;
通過 SHOW TABLE STATUS 命令 查看
File文件格式(File-Format)
Antelope: 先前未命名的,最原始的InnoDB文件格式,它支持兩種行格式:COMPACT和REDUNDANT,MySQL 5.6及其以前版本默認格式為Antelope。
Barracuda: 新的文件格式。它支持InnoDB的所有行格式,包括新的行格式:COMPRESSED和 DYNAMIC。
在早期的InnoDB版本中,文件格式只有一種,隨著InnoDB引擎的發(fā)展,出現(xiàn)了新文件格式,用于支持新的功能。目前InnoDB只支持兩種文件格式:Antelope 和 Barracuda。
通過innodb_file_format 配置參數(shù)可以設置InnoDB文件格式,之前默認值為Antelope,5.7版本開始改為Barracuda。
Row行格式(Row_format)

表的行格式?jīng)Q定了它的行是如何物理存儲的,這反過來又會影響查詢和DML操作的性能。如果在單個page頁中容納更多行,查詢和索引查找可以更快地工作,緩沖池中所需的內(nèi)存更少,寫入更新時所需的I/O更少。
InnoDB存儲引擎支持四種行格式:REDUNDANT、COMPACT、DYNAMIC和COMPRESSED。
DYNAMIC和COMPRESSED新格式引入的功能有:數(shù)據(jù)壓縮、增強型長列數(shù)據(jù)的頁外存儲和大索引前綴。
每個表的數(shù)據(jù)分成若干頁來存儲,每個頁中采用B樹結構存儲;
如果某些字段信息過長,無法存儲在B樹節(jié)點中,這時候會被單獨分配空間,此時被稱為溢出頁,該字段被稱為頁外列。
COMPRESSED行格式提供與DYNAMIC行格式相同的存儲特性和功能,但增加了對表和索引
數(shù)據(jù)壓縮的支持。使用DYNAMIC行格式,InnoDB會將表中長可變長度的列值完全存儲在頁外,而索引記錄只包含指向溢出頁的20字節(jié)指針。大于或等于768字節(jié)的固定長度字段編碼為可變長度字段。DYNAMIC行格式支持大索引前綴,最多可以為3072字節(jié),可通過innodb_large_prefix參數(shù)控制。
與REDUNDANT行格式相比,COMPACT行格式減少了約20%的行存儲空間,但代價是增加了
某些操作的CPU使用量。如果系統(tǒng)負載是受緩存命中率和磁盤速度限制,那么COMPACT格式
可能更快。如果系統(tǒng)負載受到CPU速度的限制,那么COMPACT格式可能會慢一些。使用REDUNDANT行格式,表會將變長列值的前768字節(jié)存儲在B樹節(jié)點的索引記錄中,其余
的存儲在溢出頁上。對于大于等于786字節(jié)的固定長度字段InnoDB會轉換為變長字段,以便
能夠在頁外存儲。REDUNDANT 行格式
COMPACT 行格式
DYNAMIC 行格式
COMPRESSED 行格式
在創(chuàng)建表和索引時,文件格式都被用于每個InnoDB表數(shù)據(jù)文件(其名稱與*.ibd匹配)。修改文件格式的方法是重新創(chuàng)建表及其索引,最簡單方法是對要修改的每個表使用以下命令:
ALTER TABLE 表名 ROW_FORMAT=格式類型;
Undo Log
Undo Log介紹
Undo:意為撤銷或取消,以撤銷操作為目的,返回指定某個狀態(tài)的操作。
Undo Log:數(shù)據(jù)庫事務開始之前,會將要修改的記錄存放到 Undo 日志里,當事務回滾時或者數(shù)據(jù)庫崩潰時,可以利用 Undo 日志,撤銷未提交事務對數(shù)據(jù)庫產(chǎn)生的影響。
Undo Log產(chǎn)生和銷毀:Undo Log在事務開始前產(chǎn)生;事務在提交時,并不會立刻刪除undo log,innodb會將該事務對應的undo log放入到刪除列表中,后面會通過后臺線程purge thread進行回收處理。Undo Log屬于邏輯日志,記錄一個變化過程。例如執(zhí)行一個delete,undolog會記錄一個insert;執(zhí)行一個update,undolog會記錄一個相反的update。
Undo Log存儲:undo log采用段的方式管理和記錄。在innodb數(shù)據(jù)文件中包含一種rollback segment回滾段,內(nèi)部包含1024個undo log segment。可以通過下面一組參數(shù)來控制Undo log存儲。
#相關參數(shù)命令 show variables like '%innodb_undo%';
Undo Log作用
實現(xiàn)事務的原子性
Undo Log 是為了實現(xiàn)事務的原子性而出現(xiàn)的產(chǎn)物。事務處理過程中,如果出現(xiàn)了錯誤或者用戶執(zhí)行了 ROLLBACK 語句,MySQL 可以利用 Undo Log 中的備份將數(shù)據(jù)恢復到事務開始之前的狀態(tài)。
實現(xiàn)多版本并發(fā)控制(MVCC)
Undo Log 在 MySQL InnoDB 存儲引擎中用來實現(xiàn)多版本并發(fā)控制。事務未提交之前,Undo Log保存了未提交之前的版本數(shù)據(jù),Undo Log 中的數(shù)據(jù)可作為數(shù)據(jù)舊版本快照供其他并發(fā)事務進行快照讀。
.jpg)
事務A手動開啟事務,執(zhí)行更新操作,首先會把更新命中的數(shù)據(jù)備份到 Undo Buffer 中;
事務B手動開啟事務,執(zhí)行查詢操作,會讀取 Undo 日志數(shù)據(jù)返回,進行快照讀;
Redo Log 和 Binlog
Redo Log 日志
Redo Log 介紹
Redo:顧名思義就是重做。以恢復操作為目的,在數(shù)據(jù)庫發(fā)生意外時重現(xiàn)操作。
Redo Log:指事務中修改的任何數(shù)據(jù),將最新的數(shù)據(jù)備份存儲的位置(Redo Log),被稱為重做日志。
Redo Log 的生成和釋放:隨著事務操作的執(zhí)行,就會生成Redo Log,在事務提交時會將產(chǎn)生Redo Log寫入Log Buffer,并不是隨著事務的提交就立刻寫入磁盤文件。等事務操作的臟頁寫入到磁盤之后,Redo Log 的使命也就完成了,Redo Log占用的空間就可以重用(被覆蓋寫入)。
Redo Log工作原理
.jpg)
Redo Log 是為了實現(xiàn)事務的持久性而出現(xiàn)的產(chǎn)物。防止在發(fā)生故障的時間點,尚有臟頁未寫入表
的 IBD 文件中,在重啟 MySQL 服務的時候,根據(jù) Redo Log 進行重做,從而達到事務的未入磁盤
數(shù)據(jù)進行持久化這一特性。
Redo Log寫入機制
Redo Log 文件內(nèi)容是以順序循環(huán)的方式寫入文件,寫滿時則回溯到第一個文件,進行覆蓋寫。
.jpg)
write pos 是當前記錄的位置,一邊寫一邊后移,寫到最后一個文件末尾后就回到 0 號文件開頭;
checkpoint 是當前要擦除的位置,也是往后推移并且循環(huán)的,擦除記錄前要把記錄更新到數(shù)據(jù)文件;
write pos 和 checkpoint 之間還空著的部分,可以用來記錄新的操作。如果 write pos 追上checkpoint,表示寫滿,這時候不能再執(zhí)行新的更新,得停下來先擦掉一些記錄,把 checkpoint推進一下。
Redo Log相關配置參數(shù)
show variables like '%innodb_log%';
每個InnoDB存儲引擎至少有1個重做日志文件組(group),每個文件組至少有2個重做日志文件,默認為ib_logfile0和ib_logfile1。可以通過下面一組參數(shù)控制Redo Log存儲:
Redo Buffer 持久化到 Redo Log 的策略,可通過 Innodb_flush_log_at_trx_commit 設置:
.jpg)
0:每秒提交 Redo buffer ->OS cache -> flush cache to disk,可能丟失一秒內(nèi)的事務數(shù)據(jù)。由后臺Master線程每隔 1秒執(zhí)行一次操作。
1(默認值):每次事務提交執(zhí)行 Redo Buffer -> OS cache -> flush cache to disk,最安全,性能最差的方式。
2:每次事務提交執(zhí)行 Redo Buffer -> OS cache,然后由后臺Master線程再每隔1秒執(zhí)行OS cache -> flush cache to disk 的操作。
一般建議選擇取值2,因為 MySQL 掛了數(shù)據(jù)沒有損失,整個服務器掛了才會損失1秒的事務提交數(shù)
據(jù)。
Binlog日志
Binlog 記錄模式
ROW(row-based replication, RBR):日志中會記錄每一行數(shù)據(jù)被修改的情況,然后在slave端對相同的數(shù)據(jù)進行修改。
STATMENT(statement-based replication, SBR):每一條被修改數(shù)據(jù)的SQL都會記錄到master的Binlog中,slave在復制的時候SQL進程會解析成和原來master端執(zhí)行過的相同的SQL再次執(zhí)行。簡稱SQL語句復制。
MIXED(mixed-based replication, MBR):以上兩種模式的混合使用,一般會使用STATEMENT模式保存binlog,對于STATEMENT模式無法復制的操作使用ROW模式保存binlog,MySQL會根據(jù)執(zhí)行的SQL語句選擇寫入模式。
優(yōu)點:能清楚記錄每一個行數(shù)據(jù)的修改細節(jié),能完全實現(xiàn)主從數(shù)據(jù)同步和數(shù)據(jù)的恢復。
缺點:批量操作,會產(chǎn)生大量的日志,尤其是alter table會讓日志暴漲。
優(yōu)點:日志量小,減少磁盤IO,提升存儲和恢復速度
缺點:在某些情況下會導致主從數(shù)據(jù)不一致,比如last_insert_id()、now()等函數(shù)。
主從復制:在主庫中開啟Binlog功能,這樣主庫就可以把Binlog傳遞給從庫,從庫拿到Binlog后實現(xiàn)數(shù)據(jù)恢復達到主從數(shù)據(jù)一致性。
數(shù)據(jù)恢復:通過mysqlbinlog工具來恢復數(shù)據(jù)。
Redo Log 是屬于InnoDB引擎所特有的日志,而MySQL Server也有自己的日志,即 Binary log(二進制日志),簡稱Binlog。Binlog是記錄所有數(shù)據(jù)庫表結構變更以及表數(shù)據(jù)修改的二進制日志,不會記錄SELECT和SHOW這類操作。Binlog日志是以事件形式記錄,還包含語句所執(zhí)行的消耗時間。開啟Binlog日志有以下兩個最重要的使用場景。
Binlog文件名默認為“主機名_binlog-序列號”格式,例如oak_binlog-000001,也可以在配置文件中指定名稱。文件記錄模式有STATEMENT、ROW和MIXED三種,具體含義如下。
Binlog 文件結構
MySQL的binlog文件中記錄的是對數(shù)據(jù)庫的各種修改操作,用來表示修改操作的數(shù)據(jù)結構是Log event。不同的修改操作對應的不同的log event。比較常用的log event有:Query event、Row event、Xid event等。binlog文件的內(nèi)容就是各種Log event的集合。
Binlog文件中Log event結構如下圖所示:
.jpg)
Binlog寫入機制
根據(jù)記錄模式和操作觸發(fā)event事件生成log event(事件觸發(fā)執(zhí)行機制)
將事務執(zhí)行過程中產(chǎn)生log event寫入緩沖區(qū),每個事務線程都有一個緩沖區(qū)Log Event保存在一個binlog_cache_mngr數(shù)據(jù)結構中,在該結構中有兩個緩沖區(qū),一個是stmt_cache,用于存放不支持事務的信息;另一個是trx_cache,用于存放支持事務的信息。
事務在提交階段會將產(chǎn)生的log event寫入到外部binlog文件中。
不同事務以串行方式將log event寫入binlog文件中,所以一個事務包含的log event信息在binlog文件中是連續(xù)的,中間不會插入其他事務的log event。
Binlog文件操作
根據(jù)記錄模式和操作觸發(fā)event事件生成log event(事件觸發(fā)執(zhí)行機制)
將事務執(zhí)行過程中產(chǎn)生log event寫入緩沖區(qū),每個事務線程都有一個緩沖區(qū)
Log Event保存在一個binlog_cache_mngr數(shù)據(jù)結構中,在該結構中有兩個緩沖區(qū),一個是stmt_cache,用于存放不支持事務的信息;另一個是trx_cache,用于存放支持事務的信息。
事務在提交階段會將產(chǎn)生的log event寫入到外部binlog文件中。
不同事務以串行方式將log event寫入binlog文件中,所以一個事務包含的log event信息在
binlog文件中是連續(xù)的,中間不會插入其他事務的log event。Binlog文件操作
purge binary logs to 'mysqlbinlog.000001'; //刪除指定文件 purge binary logs before '2020-04-28 00:00:00'; //刪除指定時間之前的文件 reset master; //清除所有文件
可以通過設置expire_logs_days參數(shù)來啟動自動清理功能。默認值為0表示沒啟用。設置為1表示超出1天binlog文件會自動刪除掉。
//按指定時間恢復 mysqlbinlog --start-datetime="2020-04-25 18:00:00" --stop- datetime="2020-04-26 00:00:00" mysqlbinlog.000002 | mysql -uroot -p1234 //按事件位置號恢復 mysqlbinlog --start-position=154 --stop-position=957 mysqlbinlog.000002 | mysql -uroot -p1234
mysqldump:定期全部備份數(shù)據(jù)庫數(shù)據(jù)。mysqlbinlog可以做增量備份和恢復操作。
mysqlbinlog "文件名" mysqlbinlog "文件名" > "test.sql"
show binary logs; //等價于show master logs; show master status; show binlog events; show binlog events in 'mysqlbinlog.000001';
set global log_bin = mysqllogbin; ERROR 1238 (HY000): Variable 'log_bin' is a read only variable
需要修改my.cnf或my.ini配置文件,在[mysqld]下面增加log_bin=mysql_bin_log,重啟MySQL服務。
#log-bin=ON #log-bin-basename=mysqlbinlog binlog-format=ROW log-bin=mysqlbinlog
show variables like 'log_bin';
Binlog狀態(tài)查看
開啟Binlog功能
使用show binlog events命令
使用 mysqlbinlog 命令
使用 binlog 恢復數(shù)據(jù)
刪除Binlog文件
Redo Log和 Binlog區(qū)別
Redo Log是屬于InnoDB引擎功能,Binlog是屬于MySQL Server自帶功能,并且是以二進制文件記錄。
Redo Log屬于物理日志,記錄該數(shù)據(jù)頁更新狀態(tài)內(nèi)容,Binlog是邏輯日志,記錄更新過程。
Redo Log日志是循環(huán)寫,日志空間大小是固定,Binlog是追加寫入,寫完一個寫下一個,不會覆蓋使用。
Redo Log作為服務器異常宕機后事務數(shù)據(jù)自動恢復使用,Binlog可以作為主從復制和數(shù)據(jù)恢復使用。Binlog沒有自動crash-safe能力。
到此,相信大家對“mysql架構的原理是什么”有了更深的了解,不妨來實際操作一番吧!這里是創(chuàng)新互聯(lián)網(wǎng)站,更多相關內(nèi)容可以進入相關頻道進行查詢,關注我們,繼續(xù)學習!
網(wǎng)站名稱:mysql架構的原理是什么
網(wǎng)站網(wǎng)址:http://chinadenli.net/article28/ipsdcp.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供外貿(mào)網(wǎng)站建設、定制網(wǎng)站、域名注冊、搜索引擎優(yōu)化、企業(yè)建站、品牌網(wǎng)站建設
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉載內(nèi)容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)
