大數(shù)據(jù)云計(jì)算面試之HDFS架構(gòu)的示例分析
這篇文章主要介紹了大數(shù)據(jù)云計(jì)算面試之HDFS架構(gòu)的示例分析,具有一定借鑒價(jià)值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
創(chuàng)新互聯(lián)建站擁有網(wǎng)站維護(hù)技術(shù)和項(xiàng)目管理團(tuán)隊(duì),建立的售前、實(shí)施和售后服務(wù)體系,為客戶(hù)提供定制化的網(wǎng)站設(shè)計(jì)制作、網(wǎng)站建設(shè)、網(wǎng)站維護(hù)、四川電信科技城機(jī)房解決方案。為客戶(hù)網(wǎng)站安全和日常運(yùn)維提供整體管家式外包優(yōu)質(zhì)服務(wù)。我們的網(wǎng)站維護(hù)服務(wù)覆蓋集團(tuán)企業(yè)、上市公司、外企網(wǎng)站、商城網(wǎng)站建設(shè)、政府網(wǎng)站等各類(lèi)型客戶(hù)群體,為全球成百上千企業(yè)提供全方位網(wǎng)站維護(hù)、服務(wù)器維護(hù)解決方案。
HDFS架構(gòu)
可以查看官網(wǎng)的描述
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
介紹NameNode and DataNodes

結(jié)合上圖官網(wǎng) 描述可以總結(jié)
HDFS has a master/slave architecture 是一個(gè)主從的架構(gòu)
An HDFS cluster consists of a single NameNode 一個(gè)集群只有一個(gè)NameNode
there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. 有多個(gè) DataNodes 主要作用是管理manages 文件系統(tǒng)的命名空間,和管理需要訪問(wèn)文件的客戶(hù)端
HDFS exposes a file system namespace and allows user data to be stored in files. HDFS公開(kāi)了文件系統(tǒng)名稱(chēng)空間,并允許用戶(hù)數(shù)據(jù)存儲(chǔ)在文件中。
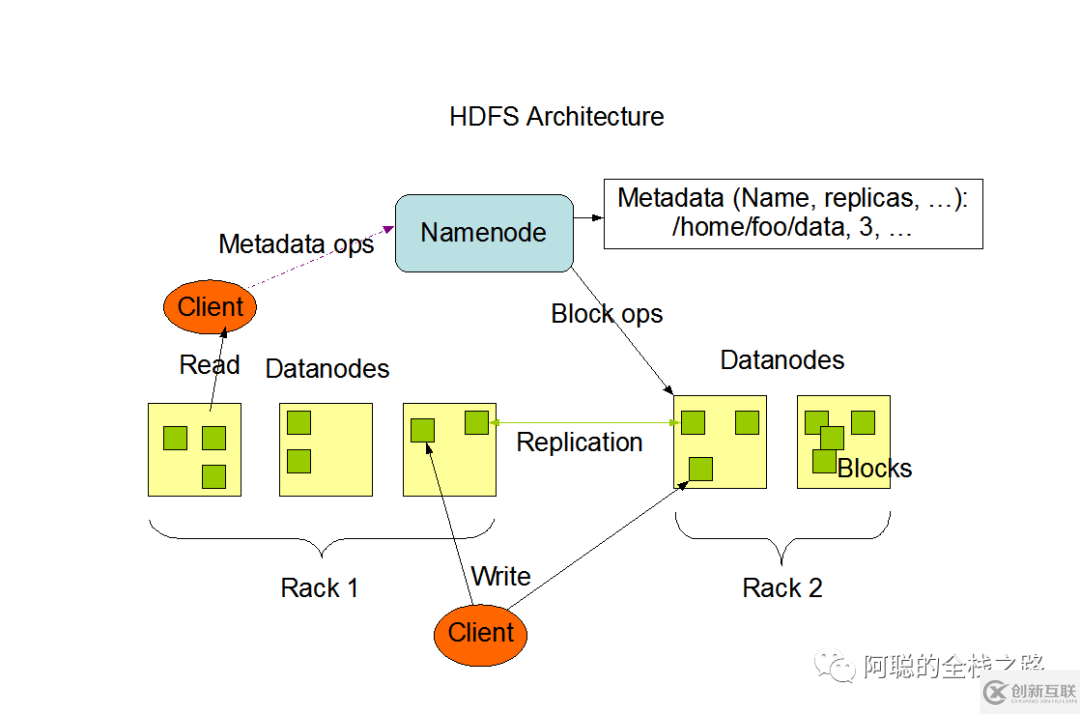
根據(jù)上圖
可以看到有這么幾個(gè)概念
Client
NameNode( 簡(jiǎn)寫(xiě)為NN)
DataNodes (簡(jiǎn)寫(xiě)為 DN)
Block
Client 用于發(fā)起HDFS請(qǐng)求,可以是用戶(hù),可以是代碼
NN 存在唯一一個(gè),所以存在SinglePoint of Failure (單點(diǎn)故障的問(wèn)題) 引出 ==》HA(heigh available)
DN 存在多個(gè)
作用:存儲(chǔ)數(shù)據(jù) 和NN 之間有心跳
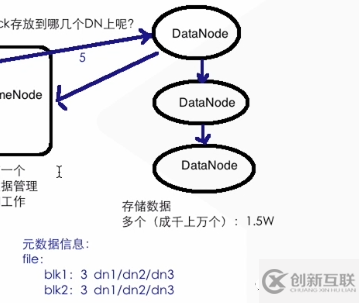
Namenode 創(chuàng)建的時(shí)候,配置有文件名字、 副本數(shù) 等
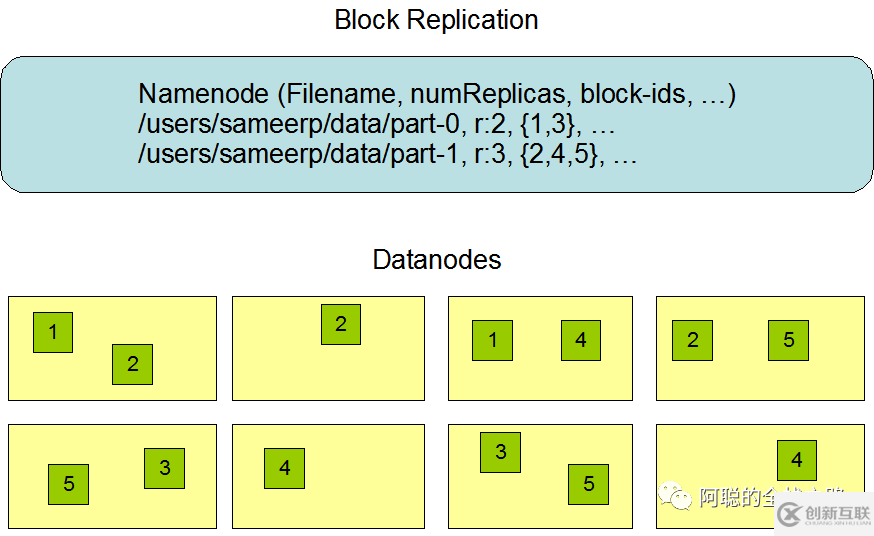
2.讀寫(xiě)流程
了解架構(gòu)后,我們來(lái)看讀寫(xiě)流程
假設(shè)我們有一個(gè)client 一個(gè)NameNode 三個(gè)DataNode,等幾個(gè)角色
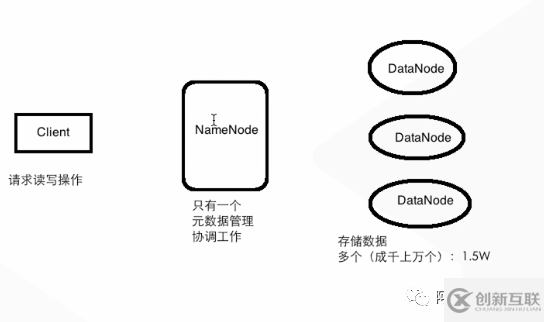
(1)寫(xiě)入流程
1.一個(gè)用戶(hù)、代碼需要寫(xiě)入文件
第一步:client 從配置文件(hdfs 的配置文件中)獲取到 1. 副本大小 2.副本數(shù)量
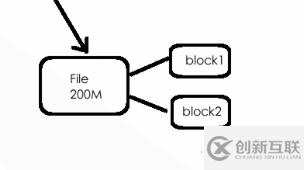
第二步:在第一步獲取的的參數(shù)中,進(jìn)行文件拆分
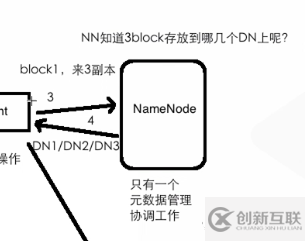
第三步:client 向 NameNode 發(fā)起請(qǐng)求,詢(xún)問(wèn)NameNode 文件應(yīng)該放在哪里
第四步: NameNode 返回文件,可以存放到的位置
第五步:client 對(duì)指定的DataNode 位置寫(xiě)入文件
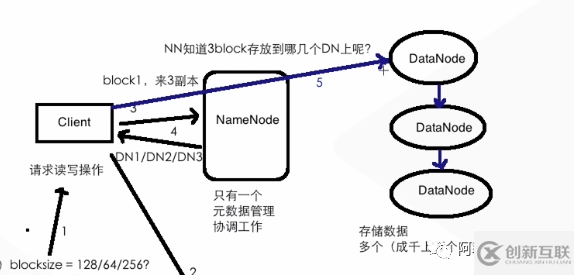
DataNode 寫(xiě)入完成進(jìn)行副本拷貝和通知NameNode
(2)讀取流程(就相對(duì)比較簡(jiǎn)單了)
第一步:客戶(hù)段請(qǐng)求NameNode 文件
第二步:NameNode 返回存放該數(shù)據(jù)的DataNode 地址
第三步:client 到DataNode 讀取數(shù)據(jù)
3.HA (高可用)架構(gòu)
在官網(wǎng)上可以看到有QJM 和NFS 架構(gòu)
QJM(https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html)
NFS(https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html)
其中見(jiàn)常見(jiàn)的HA框架如下圖所示
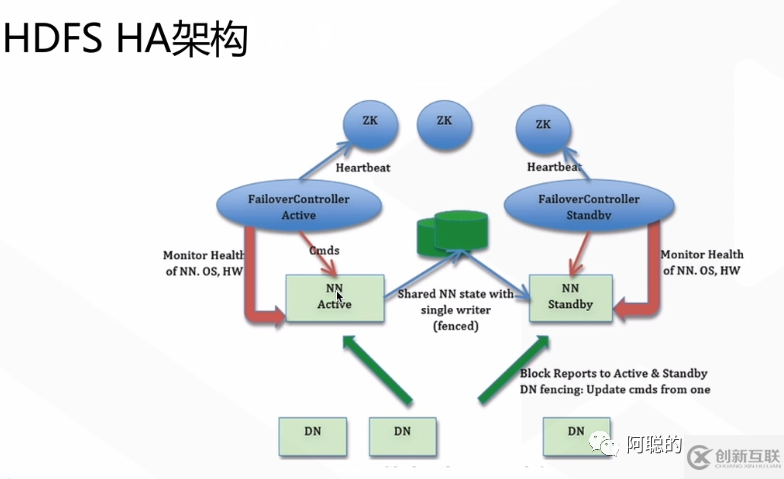
建立多個(gè)NameNode 一個(gè)Active 活動(dòng)狀態(tài), 一個(gè)Standby 備用,通過(guò)Monitor Health 監(jiān)控狀態(tài), 通過(guò)Zookeeper 協(xié)調(diào)主備切換
4.小文件是什么
小文件是指文件size小于HDFS上block大小的文件。這樣的文件會(huì)給hadoop的擴(kuò)展性和性能帶來(lái)嚴(yán)重問(wèn)題
為什么有小文件?
5.小文件帶來(lái)的瓶頸
1.磁盤(pán)IO
2.task啟動(dòng)銷(xiāo)毀的開(kāi)銷(xiāo)
3.資源有限(磁盤(pán)空間)
具體為:處理大量小文件速度遠(yuǎn)遠(yuǎn)小于處理同等大小的大文件的速度。每一個(gè)小文件要占用一個(gè)slot,而task啟動(dòng)將耗費(fèi)大量時(shí)間甚至大部分時(shí)間都耗費(fèi)在啟動(dòng)task和釋放task上。
最后小文件的解決方法:
通用處理方案:
1、Hadoop Archive
Hadoop Archive或者HAR,是一個(gè)高效地將小文件放入HDFS塊中的文件存檔工具,它能夠?qū)⒍鄠€(gè)小文件打包成一個(gè)HAR文件,這樣在減少namenode內(nèi)存使用的同時(shí),仍然允許對(duì)文件進(jìn)行透明的訪問(wèn)。
2、Sequence file
sequence file由一系列的二進(jìn)制key/value組成,如果為key小文件名,value為文件內(nèi)容,則可以將大批小文件合并成一個(gè)大文件。
底層處理方案:
HDFS-8998:
DataNode劃分小文件區(qū),專(zhuān)門(mén)存儲(chǔ)小文件。一個(gè)block塊滿(mǎn)了開(kāi)始使用下一個(gè)block。
HDFS-8286:
將元數(shù)據(jù)從namenode從內(nèi)存移到第三方k-v存儲(chǔ)系統(tǒng)中。
HDFS-7240:
Apache Hadoop Ozone,hadoop子項(xiàng)目,為擴(kuò)展hdfs而生。
感謝你能夠認(rèn)真閱讀完這篇文章,希望小編分享的“大數(shù)據(jù)云計(jì)算面試之HDFS架構(gòu)的示例分析”這篇文章對(duì)大家有幫助,同時(shí)也希望大家多多支持創(chuàng)新互聯(lián),關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道,更多相關(guān)知識(shí)等著你來(lái)學(xué)習(xí)!
本文標(biāo)題:大數(shù)據(jù)云計(jì)算面試之HDFS架構(gòu)的示例分析
本文鏈接:http://chinadenli.net/article18/jgjcgp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供外貿(mào)網(wǎng)站建設(shè)、品牌網(wǎng)站建設(shè)、動(dòng)態(tài)網(wǎng)站、移動(dòng)網(wǎng)站建設(shè)、域名注冊(cè)、企業(yè)建站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶(hù)投稿、用戶(hù)轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 企業(yè)網(wǎng)站制作為什么要做手機(jī)站自適應(yīng)網(wǎng)站又有什么優(yōu)勢(shì) 2021-08-30
- 制作自適應(yīng)網(wǎng)站時(shí)應(yīng)注意哪些問(wèn)題 2016-06-27
- 響應(yīng)式網(wǎng)站建設(shè)和自適應(yīng)網(wǎng)站建設(shè)之間的區(qū)別 2014-10-17
- 自適應(yīng)網(wǎng)站制作注意事項(xiàng) 2016-09-12
- 手機(jī)電腦一體自適應(yīng)網(wǎng)站該如何制作呢? 2016-10-28
- 自適應(yīng)網(wǎng)站建設(shè)注意要點(diǎn)有哪些 2020-12-04
- 自適應(yīng)網(wǎng)站制作在市場(chǎng)優(yōu)勢(shì)是什么 2021-10-20
- 【南充網(wǎng)站建設(shè)】什么是自適應(yīng)網(wǎng)站?自適應(yīng)網(wǎng)站價(jià)格高嗎 2014-11-28
- 如何開(kāi)發(fā)一個(gè)真正的自適應(yīng)網(wǎng)站? 2016-11-11
- 將傳統(tǒng)網(wǎng)站構(gòu)建成自適應(yīng)網(wǎng)站所使用的關(guān)鍵技術(shù) 2016-10-27
- 什么是H5自適應(yīng)網(wǎng)站? 2020-10-31
- 成都網(wǎng)站建設(shè)對(duì)你說(shuō)自適應(yīng)網(wǎng)站的設(shè)計(jì)構(gòu)思 2016-09-15