Java大數(shù)據(jù)開(kāi)發(fā)中Hadoop的HDFS內(nèi)部原理是什么
這篇文章將為大家詳細(xì)講解有關(guān)Java大數(shù)據(jù)開(kāi)發(fā)中Hadoop的HDFS內(nèi)部原理是什么,小編覺(jué)得挺實(shí)用的,因此分享給大家做個(gè)參考,希望大家閱讀完這篇文章后可以有所收獲。
成都創(chuàng)新互聯(lián)是一家集網(wǎng)站建設(shè),桐廬企業(yè)網(wǎng)站建設(shè),桐廬品牌網(wǎng)站建設(shè),網(wǎng)站定制,桐廬網(wǎng)站建設(shè)報(bào)價(jià),網(wǎng)絡(luò)營(yíng)銷,網(wǎng)絡(luò)優(yōu)化,桐廬網(wǎng)站推廣為一體的創(chuàng)新建站企業(yè),幫助傳統(tǒng)企業(yè)提升企業(yè)形象加強(qiáng)企業(yè)競(jìng)爭(zhēng)力。可充分滿足這一群體相比中小企業(yè)更為豐富、高端、多元的互聯(lián)網(wǎng)需求。同時(shí)我們時(shí)刻保持專業(yè)、時(shí)尚、前沿,時(shí)刻以成就客戶成長(zhǎng)自我,堅(jiān)持不斷學(xué)習(xí)、思考、沉淀、凈化自己,讓我們?yōu)楦嗟钠髽I(yè)打造出實(shí)用型網(wǎng)站。
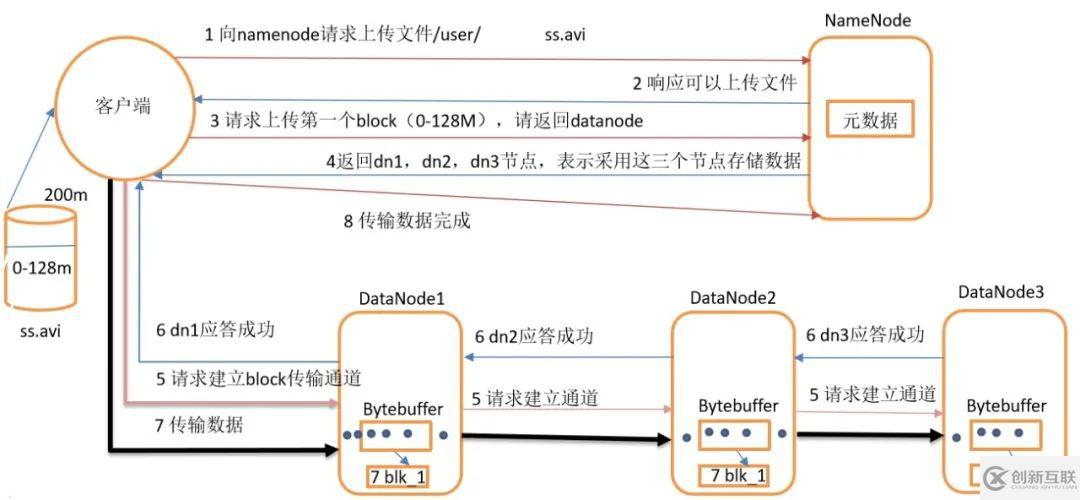
1、客戶端向NameNode請(qǐng)求上傳文件,NameNode會(huì)檢查目標(biāo)文件是否已存在,父目錄是否存在。所以NameNode起到了統(tǒng)一管理的作用。
2、NameNode返回是否可以上傳,NameNode知道每一個(gè)數(shù)據(jù)節(jié)點(diǎn)的情況。
3、客戶端請(qǐng)求第一個(gè)塊( block)上傳到集群上哪幾個(gè)DataNode服務(wù)器上。
4、NameNode返回3個(gè)DataNode節(jié)點(diǎn),分別為dn1、dn2、dn3三個(gè)節(jié)點(diǎn)。集群在啟動(dòng)的時(shí)候NameNode就已經(jīng)知道DataNode節(jié)點(diǎn)了、
5、客戶端請(qǐng)求dn1上傳數(shù)據(jù),dn1收到請(qǐng)求會(huì)繼續(xù)調(diào)用dn2,然后dn2調(diào)用dn3,將這個(gè)通信管道建立完成。
6、dn1、dn2、dn3依次逐級(jí)應(yīng)答客戶端。
7、客戶端開(kāi)始往dn1上傳第一個(gè)block(先從磁盤讀取數(shù)據(jù)放到一個(gè)本地內(nèi)存緩存),以packet為單位,dn1收到一個(gè)packet就會(huì)傳給dn2,dn2傳給dn3;dn1每傳一個(gè)packet會(huì)放入一個(gè)應(yīng)答隊(duì)列等待應(yīng)答。
8、當(dāng)一個(gè)block傳輸完成之后,客戶端再次請(qǐng)求NameNode上傳第二個(gè)block的服務(wù)器。(重復(fù)執(zhí)行3-7步)。
網(wǎng)絡(luò)拓?fù)涓拍?/strong>
在數(shù)據(jù)處理中,兩個(gè)節(jié)點(diǎn)間的帶寬作為距離的衡量標(biāo)準(zhǔn)。
節(jié)點(diǎn)距離:兩個(gè)節(jié)點(diǎn)到達(dá)最近的共同祖先的距離總和。
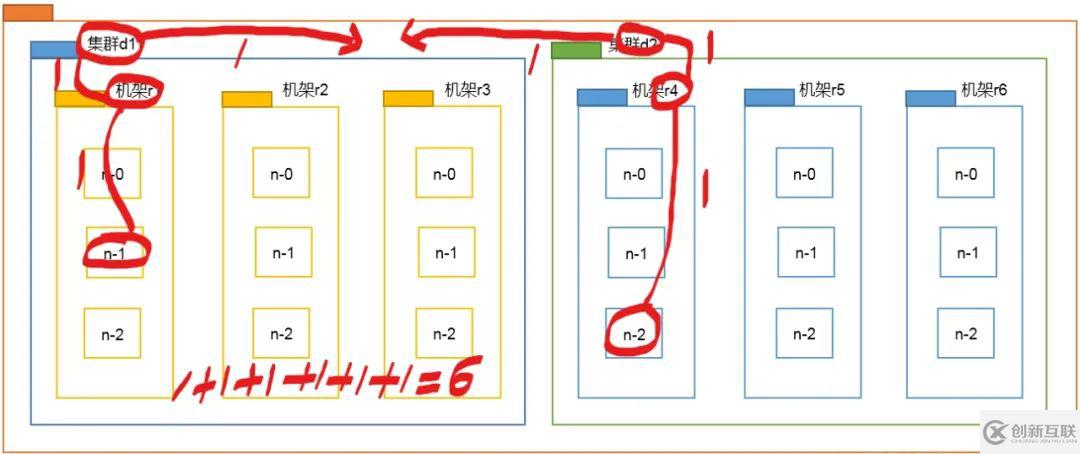
例如,假設(shè)有數(shù)據(jù)中心d1(d1為集群)機(jī)架r1中的節(jié)點(diǎn)n1。該節(jié)點(diǎn)可以表示為/d1/r1/n1。利用這種標(biāo)記,這里給出四種距離描述。
Range(/d1/r1/n1, /d1/r1/n1)=0(同一節(jié)點(diǎn)上的進(jìn)程)
Range(/d1/r1/n1, /d1/r1/n2)=2(同一機(jī)架上的不同節(jié)點(diǎn))
Range(/d1/r1/n1, /d1/r3/n2)=4(同一數(shù)據(jù)中心不同機(jī)架上的節(jié)點(diǎn))
Range(/d1/r1/n1, /d2/r4/n2)=6(不同數(shù)據(jù)中心的節(jié)點(diǎn))
注意:
對(duì)于n0 n1 n2 ,機(jī)架r1是共同祖先
對(duì)于機(jī)架r1 機(jī)架r12 機(jī)架r13,集群d1是共同祖先
依次類推......

舉例:為什么Range(/d1/r1/n1, /d2/r4/n2)=6?
副本存儲(chǔ)節(jié)點(diǎn)選擇

第一個(gè)副本在集群節(jié)點(diǎn)上,隨機(jī)選一個(gè)。
第二個(gè)副本和第一個(gè)副本位于相同機(jī)架上,但節(jié)點(diǎn)是隨機(jī)的。
第三個(gè)副本位于不同機(jī)架的隨機(jī)節(jié)點(diǎn)上。
HDFS讀數(shù)據(jù)的流程
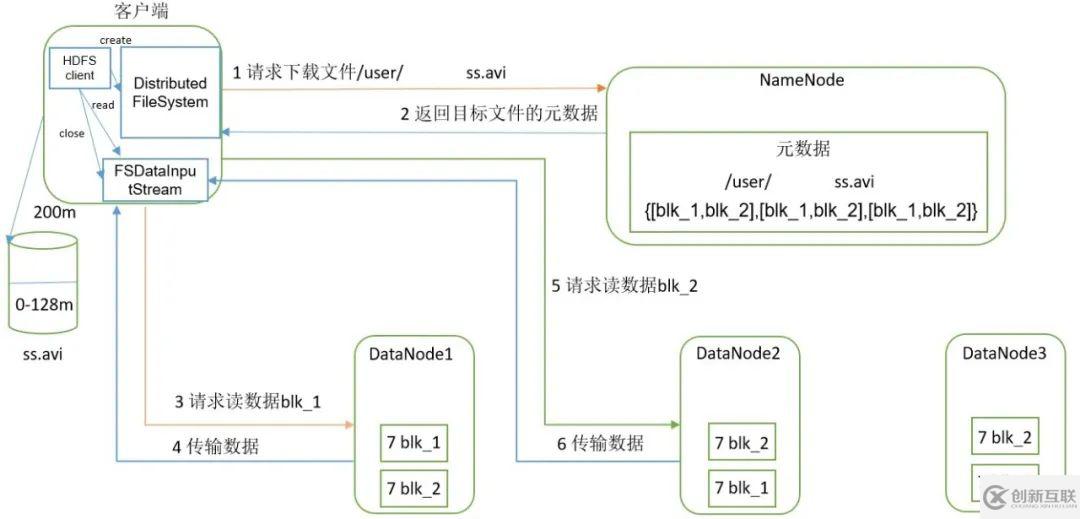
1、客戶端向NameNode請(qǐng)求下載文件,NameNode會(huì)通過(guò)查詢?cè)獢?shù)據(jù),找到DataNode地址,即文件塊所在的地址。
2、挑選一臺(tái)DataNode服務(wù)器,至于選哪一臺(tái)機(jī)器是就近原則,然后隨機(jī) ,請(qǐng)求讀取數(shù)據(jù)。
3、DataNode開(kāi)始傳輸數(shù)據(jù)給客戶端,從磁盤里面讀取數(shù)據(jù)輸入流,以packet為單位來(lái)做校驗(yàn)。
4、客戶端以packet為單位接收,先在本地緩存,然后寫(xiě)入目標(biāo)文件。
關(guān)于“Java大數(shù)據(jù)開(kāi)發(fā)中Hadoop的HDFS內(nèi)部原理是什么”這篇文章就分享到這里了,希望以上內(nèi)容可以對(duì)大家有一定的幫助,使各位可以學(xué)到更多知識(shí),如果覺(jué)得文章不錯(cuò),請(qǐng)把它分享出去讓更多的人看到。
網(wǎng)頁(yè)標(biāo)題:Java大數(shù)據(jù)開(kāi)發(fā)中Hadoop的HDFS內(nèi)部原理是什么
URL分享:http://chinadenli.net/article12/gphsgc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供微信小程序、網(wǎng)站收錄、品牌網(wǎng)站建設(shè)、搜索引擎優(yōu)化、響應(yīng)式網(wǎng)站、服務(wù)器托管
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- [成都網(wǎng)站制作]動(dòng)態(tài)網(wǎng)站開(kāi)發(fā)語(yǔ)言及平臺(tái) 2023-01-18
- 動(dòng)態(tài)頁(yè)面生成靜態(tài)HTML頁(yè)面的問(wèn)題 2017-02-28
- 企業(yè)網(wǎng)站建設(shè)使用動(dòng)態(tài)還是靜態(tài)網(wǎng)頁(yè)好? 2013-09-03
- 公司網(wǎng)站制作動(dòng)態(tài)方法與技巧 2016-08-22
- 什么是動(dòng)態(tài)網(wǎng)站建設(shè) 2016-11-04
- 什么是動(dòng)態(tài)網(wǎng)站?動(dòng)態(tài)網(wǎng)站與靜態(tài)網(wǎng)站如何區(qū)別 2022-04-26
- 網(wǎng)站推廣中行業(yè)動(dòng)態(tài)的引導(dǎo)功能重要嗎 2016-10-29
- 企業(yè)建設(shè)網(wǎng)站頁(yè)面是使用動(dòng)態(tài)好還是靜態(tài)好呢 2016-09-25
- 網(wǎng)站運(yùn)營(yíng)的能力和網(wǎng)站建設(shè)動(dòng)態(tài) 2017-03-03
- 從外觀上來(lái)說(shuō)動(dòng)態(tài)網(wǎng)站與靜態(tài)網(wǎng)站的區(qū)別 2020-07-07
- 網(wǎng)頁(yè)設(shè)計(jì)中動(dòng)態(tài)特效有哪些好處? 2016-11-12
- 創(chuàng)新互聯(lián)小編與大家分享動(dòng)態(tài)網(wǎng)站制作的幾點(diǎn)要素 2021-05-27