什么是高性能計算,涉及哪些技術(shù)和知識呢?
2022-10-04 分類: 網(wǎng)站建設(shè)
高性能計算(HPC) 指通常使用很多處理器(作為單個機(jī)器的一部分)或者某一集群中組織的幾臺計算機(jī)(作為單個計算資源操作)的計算系統(tǒng)和環(huán)境。高性能集群上運行的應(yīng)用程序一般使用并行算法,把一個大的普通問題根據(jù)一定的規(guī)則分為許多小的子問題,在集群內(nèi)的不同節(jié)點上進(jìn)行計算,而這些小問題的處理結(jié)果,經(jīng)過處理可合并為原問題的最終結(jié)果。由于這些小問題的計算一般是可以并行完成的,從而可以縮短問題的處理時間。
高性能集群在計算過程中,各節(jié)點是協(xié)同工作的,它們分別處理大問題的一部分,并在處理中根據(jù)需要進(jìn)行數(shù)據(jù)交換,各節(jié)點的處理結(jié)果都是最終結(jié)果的一部分。高性能集群的處理能力與集群的規(guī)模成正比,是集群內(nèi)各節(jié)點處理能力之和,但這種集群一般沒有高可用性。高性能計算的分類方法很多。這里從并行任務(wù)間的關(guān)系角度來對高性能計算分類。
一、高吞吐計算(High-throughput Computing)
有一類高性能計算,可以把它分成若干可以并行的子任務(wù),而且各個子任務(wù)彼此間沒有什么關(guān)聯(lián)。因為這種類型應(yīng)用的一個共同特征是在海量數(shù)據(jù)上搜索某些特定模式,所以把這類計算稱為高吞吐計算。所謂的Internet計算都屬于這一類。按照Flynn的分類,高吞吐計算屬于SIMDSingle Instruction/Multiple Data,單指令流-多數(shù)據(jù)流)的范疇。
二、分布計算(Distributed Computing)
另一類計算剛好和高吞吐計算相反,它們雖然可以給分成若干并行的子任務(wù),但是子任務(wù)間聯(lián)系很緊密,需要大量的數(shù)據(jù)交換。按照Flynn的分類,分布式的高性能計算屬于MIMD(Multiple Instruction/Multiple Data,多指令流-多數(shù)據(jù)流)的范疇。
有許多類型的HPC 系統(tǒng),其范圍從標(biāo)準(zhǔn)計算機(jī)的大型集群,到高度專用的硬件。大多數(shù)基于集群的HPC系統(tǒng)使用高性能網(wǎng)絡(luò)互連,基本的網(wǎng)絡(luò)拓?fù)浜徒M織可以使用一個簡單的總線拓?fù)洹PC系統(tǒng)由計算、存儲、網(wǎng)絡(luò)、集群軟件四部分組成。
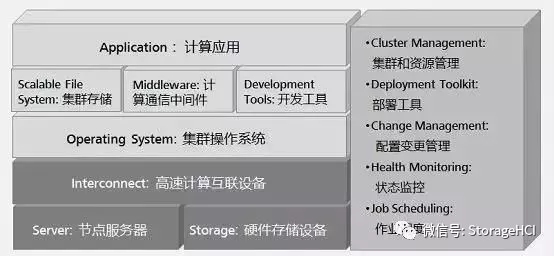
高性能計算HPC系統(tǒng)技術(shù)特點是什么?
HPC系統(tǒng)目前主流處理器是X86處理器,操作系統(tǒng)是linux 系統(tǒng)(包括Intel、AMD、NEC、Power、PowerPC、Sparc等)、構(gòu)建方式采用刀片系統(tǒng),互聯(lián)網(wǎng)絡(luò)使用IB和10GE。
高性能計算HPC集群中計算節(jié)點一般 分3種: MPI節(jié)點、胖節(jié)點、GPU加速節(jié)點。雙路節(jié)點稱為瘦節(jié)點(MPI節(jié)點),雙路以上稱為胖節(jié)點;胖節(jié)點配置大容量內(nèi)存;集群中胖節(jié)點的數(shù)量要根據(jù)實際應(yīng)用需求而定。
GPU英文全稱Graphic Processing Unit,中文翻譯為圖形處理器。 在浮點運算、并行計算等部分計算方面,GPU可以提供數(shù)十倍乃至于上百倍于CPU的性能。目前GPU廠家只有三家NVIDIA GPU、AMD GPU和Intel Xeon PHI。可選擇的GPU種類比較少。
NVIDIA 的GPU卡分圖形卡和計算卡,圖形卡有NVIDA K2000與K4000,計算卡K20X/K40M/K80 。
Intel 的GPU是Intel Xeon Phi 系列,屬于計算卡,主要產(chǎn)品有Phi 5110P 、Phi 3210P、Phi 7120P、Phi 31S1P。
AMD 的GPU是圖形和計算合一,主要產(chǎn)品有W5000、W9100、S7000、S9000、S10000。
高性能計算的性能指標(biāo)怎樣衡量?
CPU的性能計算公式: 單節(jié)點性能=處理器主頻*核數(shù)*單節(jié)點CPU數(shù)量*單周期指令數(shù)。單周期指令數(shù)=8(E5-2600/E5-2600 v2/E7-4800 v2)或16(E5-2600 v3);節(jié)點數(shù)量=峰值浮點性能需求/單節(jié)點性能。
時延( 內(nèi)存和磁盤訪問延時)是計算的另一個性能衡量指標(biāo),在HPC系統(tǒng)中,一般時延要求如下:

一個MFlops等于每秒一佰萬(=10^6)次的浮點運算;
一個GFlops等于每秒拾億(=10^9)次的浮點運算;
一個TFlops等于每秒一萬億(=10^12)次的浮點運算,(1太拉);
一個PFlops等于每秒一千萬億(=10^15)次的浮點運算;
一個EFlops等于每秒一佰京(=10^18)次的浮點運算。
測試工具—Linpack HPC是什么?
Linpack HPC 是性能測試工具。LINPACK是線性系統(tǒng)軟件包(Linear system package) 的縮寫, 主要開始于 1974 年 4 月, 美國Argonne 國家實驗室應(yīng)用數(shù)學(xué)所主任 Jim Pool, 在一系列非正式的討論會中評估,建立一套專門解線性系統(tǒng)問題之?dāng)?shù)學(xué)軟件的可能性。
業(yè)界還有其他多種測試基準(zhǔn),有的是基于實際的應(yīng)用種類如TPC-C,有的是測試系統(tǒng)的某一部分的性能,如測試硬盤吞吐能力的IOmeter,測試內(nèi)存帶寬的stream。
至目前為止, Linpack 還是廣泛地應(yīng)用于解各種數(shù)學(xué)和工程問題。也由于它高效率的運算, 使得其它幾種數(shù)學(xué)軟件例如IMSL、MatLab紛紛加以引用來處理矩陣問題,所以足見其在科學(xué)計算上有舉足輕重的地位。
Linpack現(xiàn)在在國際上已經(jīng)成為最流行的用于測試高性能計算機(jī)系統(tǒng)浮點性能的Benchmark。通過利用高性能計算機(jī),用高斯消元法求解N元一次稠密線性代數(shù)方程組的測試,評價高性能計算機(jī)的浮點性能。
雙列直插式內(nèi)存(DIMM)有幾種類型?
雙列直插式內(nèi)存(DIMM)包括UDIMM內(nèi)存、RDIMM內(nèi)存和LRDIMM內(nèi)存三種DIMM內(nèi)存可用類型。
在處理較大型工作負(fù)載時,無緩沖DIMM( UDIMM )速度快、廉價但不穩(wěn)定。
寄存器式DIMM( RDIMM )內(nèi)存穩(wěn)定、擴(kuò)展性好、昂貴,而且對內(nèi)存控制器的電氣壓力小。它們同樣在許多傳統(tǒng)服務(wù)器上使用。
降載 DIMM( LRDIMM )內(nèi)存是寄存器式內(nèi)存( RDIMM )的替代品,它們能提供高內(nèi)存速度,降低服務(wù)器內(nèi)存總線的負(fù)載,而且功耗更低。LRDIMM內(nèi)存成本比 RDIMM內(nèi)存高非常多,但在高性能計算架構(gòu)中十分常見。
非易失雙列直插式內(nèi)存NVDIMM是什么?
NVDIMM由BBU(Battery Backed Up) DIMM演變而來。BBU采用后備電池以維持普通揮發(fā)性內(nèi)存中的內(nèi)容幾小時之久。但是,電池含有重金屬,廢棄處置和對環(huán)境的污染,不符合綠色能源的要求。由超級電容作為動力源的NVDIMM應(yīng)運而生。并且NVDIMM使用非揮發(fā)性的Flash存儲介質(zhì)來保存數(shù)據(jù),數(shù)據(jù)能夠保存的時間更長。
主流高性能計算網(wǎng)絡(luò)類型有哪些?
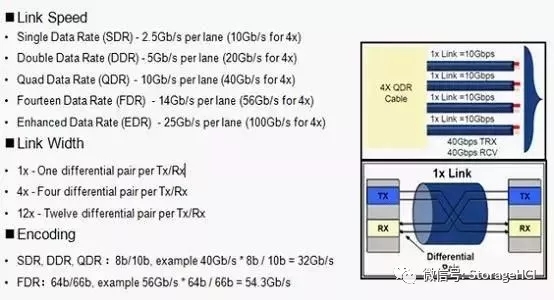
InfiniBand架構(gòu)是一種支持多并發(fā)鏈接的“轉(zhuǎn)換線纜”技術(shù),InfiniBand技術(shù)不是用于一般網(wǎng)絡(luò)連接的,它的主要設(shè)計目的是針對服務(wù)器端的連接問題的。因此,InfiniBand技術(shù)將會被應(yīng)用于服務(wù)器與服務(wù)器(比如復(fù)制,分布式工作等),服務(wù)器和存儲設(shè)備(比如SAN和直接存儲附件)以及服務(wù)器和網(wǎng)絡(luò)之間(比如LAN,WANs和互聯(lián)網(wǎng))的通信。高性能計算HPC系統(tǒng)為什么要使用IB互聯(lián)?主要原因是IB協(xié)議棧簡單,處理效率高,管理簡單,對RDMA支持好,功耗低,時延低。
目前只有Mexllaon、Intel、Qlogic提供IB產(chǎn)品,Mexllaon是主要玩家,處于主導(dǎo)地位, IB目前支持FDR和QDR、EDR。
Host Channel Adapters (HCA)是IB連接的設(shè)備終結(jié)點,提供傳輸功能和Verb接口;Target Channel Adapters (TCA)是HCA的子集,基本上用于存儲。
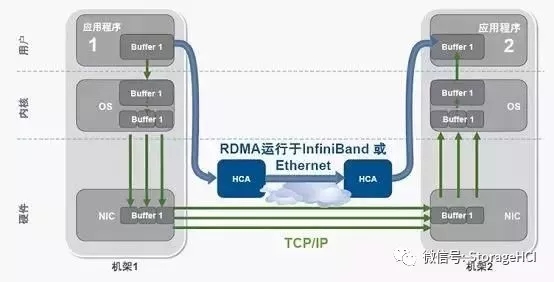
RDMA(Remote Direct Memory Access)技術(shù)全稱遠(yuǎn)程直接數(shù)據(jù)存取,就是為了解決網(wǎng)絡(luò)傳輸中服務(wù)器端數(shù)據(jù)處理的延遲而產(chǎn)生的。RDMA通過網(wǎng)絡(luò)把數(shù)據(jù)直接傳入計算機(jī)的存儲區(qū),將數(shù)據(jù)從一個系統(tǒng)快速移動到遠(yuǎn)程系統(tǒng)存儲器中,實現(xiàn)Zero Copy。
高性能計算的靈魂—并行文件系統(tǒng)
TOP500 HPC系統(tǒng)中存儲主要使用分布式文件系統(tǒng),分布式文件系統(tǒng)(Distributed File System)可以有效解決數(shù)據(jù)的存儲和管理難題: 將固定于某個地點的某個文件系統(tǒng),擴(kuò)展到任意多個地點/多個文件系統(tǒng),眾多的節(jié)點組成一個文件系統(tǒng)網(wǎng)絡(luò)。每個節(jié)點可以分布在不同的地點,通過網(wǎng)絡(luò)進(jìn)行節(jié)點間的通信和數(shù)據(jù)傳輸。人們在使用分布式文件系統(tǒng)時,無需關(guān)心數(shù)據(jù)是存儲在哪個節(jié)點上、或者是從哪個節(jié)點從獲取的,只需要像使用本地文件系統(tǒng)一樣管理和存儲文件系統(tǒng)中的數(shù)據(jù)。
分布式文件系統(tǒng)的設(shè)計基于客戶機(jī)/服務(wù)器模式。一個典型的網(wǎng)絡(luò)可能包括多個供多用戶訪問的服務(wù)器。當(dāng)前主流的分布式文件系統(tǒng)包括: Lustre、Hadoop、MogileFS、FreeNAS、FastDFS、NFS、OpenAFS、MooseFS、pNFS、以及GoogleFS等,其中Lustre、GPFS是HPC最主流的。
文章標(biāo)題:什么是高性能計算,涉及哪些技術(shù)和知識呢?
分享鏈接:http://chinadenli.net/news22/201772.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供外貿(mào)網(wǎng)站建設(shè)、手機(jī)網(wǎng)站建設(shè)、做網(wǎng)站、關(guān)鍵詞優(yōu)化、微信公眾號、移動網(wǎng)站建設(shè)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- https安全證書申請流程介紹 2022-10-04
- 香港服務(wù)器能搭建下載網(wǎng)站嗎?香港服務(wù)器搭建下載網(wǎng)站有哪些優(yōu)缺點? 2022-10-04
- 全新數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)可解決延遲和吞吐量問題 2022-10-04
- Sslerror的基本種類和解決方法 2022-10-04
- 海外服務(wù)器租用和托管哪個更有優(yōu)勢? 2022-10-04
- 如何用vps云主機(jī)分網(wǎng)站空間 2022-10-04
- 未來將從云計算過渡到霧計算嗎? 2022-10-04
- 新的勒索軟件正被部署在Log4Shell攻擊中 2022-10-04

- 云計算是物聯(lián)網(wǎng)的重要支柱 2022-10-04
- 共享主機(jī)好不好?共享主機(jī)有哪些優(yōu)勢? 2022-10-04
- 什么是Serverless? 2022-10-04
- https證書格式https證書申請流程和下載過程 2022-10-04
- 如何能租用到好的海外服務(wù)器 2022-10-04
- 國外永久服務(wù)器網(wǎng)絡(luò)延遲高是什么原因? 2022-10-04
- 多個域名能否用一個SSL證書,域名證書有什么用? 2022-10-04
- 云鎖提示服務(wù)器不在線(離線)的原因及解決辦法 2022-10-04
- 邊緣計算賦能智慧城市:機(jī)遇與挑戰(zhàn) 2022-10-04
- 如何使私有云轉(zhuǎn)向公共云消費模式 2022-10-04
- ssl證書導(dǎo)出格式怎么選ssl證書格式 2022-10-04