AWS數(shù)據(jù)分析服務(十)
Amazon Kinesis
概念
- 處理AWS上大量流數(shù)據(jù)的數(shù)據(jù)平臺
- Kinesis Streams 用于搜集數(shù)據(jù),Client Library 用于分析后的展示
- 構建用于處理或分析流數(shù)據(jù)的自定義應用程序
- 可以支持從數(shù)十萬中來源捕獲和存儲TB級的數(shù)據(jù),如網(wǎng)站點擊流、財務交易、媒體饋送、IT日志等
- 使用IAM限制用戶和角色對Kinesis的訪問,使用角色的臨時安全憑證可以提高安全性
- Kiesis只能使用SSL加密進行訪問
Kinesis組件
Kinesis Data Firehose
- 加載大量流數(shù)據(jù)到AWS服務中
- 數(shù)據(jù)默認被存儲在S3中,從S3還可以再被進一步轉存到Redshift
- 數(shù)據(jù)也可以被寫入到ElaticSearch中,并且同時備份到S3
Kinesis Data Streams:
- 自定義構建應用程序,實時分析流數(shù)據(jù)
- 利用AWS開發(fā)工具包,可以實現(xiàn)數(shù)據(jù)在流中移動時仍然能被處理,從而接近實時
- 為了接近實時,處理的復雜度通常較輕
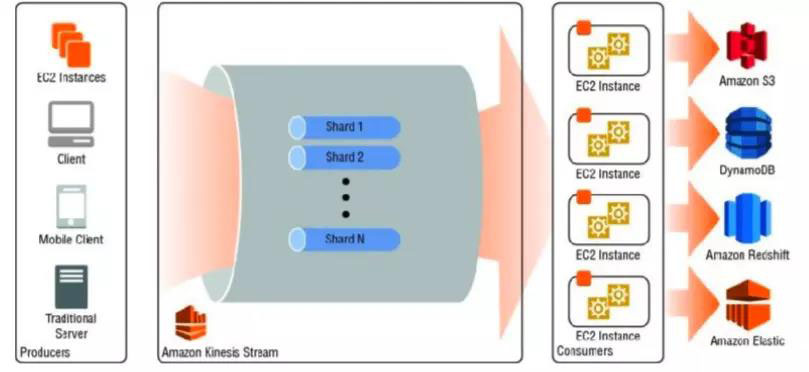
- 創(chuàng)建者 Producer 持續(xù)將數(shù)據(jù)推送進Data Streams
- 數(shù)據(jù)在DataStream 由一組組分片(Shards)組成,每個分片就是一條記錄,通過不斷分片實現(xiàn)幾乎無限的擴展能力
- 使用者 Comsumer 會實時對Data Steams的內容進行處理,并且將結果推送到不同的AWS服務
- 數(shù)據(jù)在Stream中是臨時的,默認存儲24小時,最大可以設置為7天
創(chuàng)新互聯(lián)專注于朝陽縣企業(yè)網(wǎng)站建設,響應式網(wǎng)站建設,購物商城網(wǎng)站建設。朝陽縣網(wǎng)站建設公司,為朝陽縣等地區(qū)提供建站服務。全流程按需定制制作,專業(yè)設計,全程項目跟蹤,創(chuàng)新互聯(lián)專業(yè)和態(tài)度為您提供的服務
Kinesis Data Analytics
- 使用標準SQL實時分析流數(shù)據(jù)
Kinesis Video Streams
- 捕獲、處理并存儲視頻流用于分析和機器學習
適用場景
- 大量的數(shù)據(jù)攝取
- 海量流數(shù)據(jù)的實時處理
Elastic MapReduce ( EMR)
概念
- 提供完全托管的按需 Hadoop 框架
- 啟動EMR集群的必選項
- 集群節(jié)點的實例類型
- 集群中的節(jié)點數(shù)量
- 希望運行的Hadoop版本
- Hadoop集群選擇存儲類型至關重要,主要因素是集群是持久的還是瞬態(tài)的
- 需要持續(xù)運行并分析數(shù)據(jù)的集群是持久集群
- 按需啟動并在完成后立即停止的集群為瞬時集群
- 默認不限制EMR集群數(shù)量,但限制用于EMR節(jié)點總數(shù)為20個,可申請擴展
- 可以從S3以及其他任何位置攝取數(shù)據(jù)
- Hadoop 日志文件默認存儲在S3中,且不支持壓縮
- EMR支持競價實例
- EMR需要在一個可用區(qū)部署,不支持跨可用區(qū)部署,通常建議選擇數(shù)據(jù)所在的區(qū)域
- 集群啟動通常在15分鐘內可以開始進行數(shù)據(jù)處理
- EMR允許使用磁性、SSD和 PIOPS SSD三種EBS卷。
- 適用場景
- 日志處理,點擊流分析,基因學和生命科學
文件系統(tǒng)
HDFS
- Hadoop標準文件系統(tǒng)
- 所有數(shù)據(jù)都在多個實例中被復制保證持久性
- HDFS可以利用EBS存儲確保在關閉集群時不丟失數(shù)據(jù)
- 非常適合于持久的集群
EMRFS
- HDFS在AWS S3上的實現(xiàn),將數(shù)據(jù)保存在S3中
- 可以使用所有Hadoop生態(tài)的工具系統(tǒng)
- 非常適合于瞬時集群
EMR NoteBooks
- EMR Notebooks 提供基于 Jupyter Notebook 的托管環(huán)境,可供數(shù)據(jù)科學家、分析員和開發(fā)人員準備數(shù)據(jù)并使其可視化、與同伴協(xié)作、構建應用程序,并使用 EMR 群集執(zhí)行交互分析。
- 您可以使用 EMR Notebooks 構建 Apache Spark 應用程序,并且輕而易舉地在 EMR 群集上運行交互查詢。多個用戶可以直接從控制臺創(chuàng)建無服務器筆記本、將其掛載到現(xiàn)有的共享 EMR 群集,或直接從控制臺提供至少 1 個節(jié)點的并立即開始使用 Spark 進行實驗。
安全設置
- EMR默認將設置兩個EC2安全組: 主節(jié)點和從屬節(jié)點
- 主安全組
- 定義一個端口用于與服務的通信
- 打開的SSH端口,允許啟動時指定的SSH密鑰進入實例
- 默認不允許被外部實例訪問,但可設置
- 從屬安全組
- 只允許與主實例進行交互
- 主安全組
- 默認使用SSL向S3傳送數(shù)據(jù)
- 可以支持對集群進行標記,最多10個標記,但不支持基于標記的IAM許可。
- 使用IAM權限和角色控制對EMR的訪問和控制
- 可以設置允許非Hadoop用戶將作業(yè)提交至集群的權限
- 可以將EMR放入到私有VPC中實現(xiàn)額外的保護
AWS Data Pipeline
概念
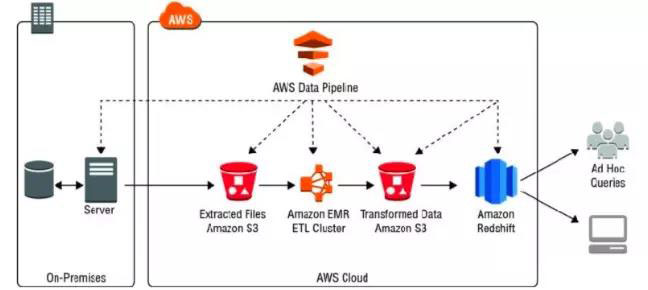
- 實現(xiàn)在指定時間間隔,在AWS資源和本地數(shù)據(jù)之間可靠地處理和移動數(shù)據(jù)
- 您可以快速輕松地部署管道,無需分心管理日常數(shù)據(jù)操作,從而讓您能夠集中精力從該數(shù)據(jù)獲取所需的信息。您只需為您的數(shù)據(jù)管道指定所需數(shù)據(jù)源、時間表和處理活動即可。
- 與SWF相比,Data Pipeline 專門設計用于簡化大多數(shù)數(shù)據(jù)驅動工作流程中常見的特定步驟。例如:在輸入數(shù)據(jù)符合特定準備就緒標準后執(zhí)行活動,輕松在不同數(shù)據(jù)存儲之間復制數(shù)據(jù),以及調度鏈接的轉換。這種高度具體的側重點意味著 Data Pipeline 工作流定義可以快速創(chuàng)建,并且無需代碼或編程知識。
- 定期訪問存儲數(shù)據(jù),并對數(shù)據(jù)進行大規(guī)模處理,并且將結果轉換為AWS服務
- 利用Pipeline的定義安排和運行任務,可以每15分鐘,每天,每周運行等
- 數(shù)據(jù)節(jié)點是pipeline流水線讀取和寫入數(shù)據(jù)的位置,可以是S3,MySQL,Redshift等AWS或本地存儲
- Pipeline通常需要配合其他服務執(zhí)行預定義的任務,如EMR,EC2等,并在執(zhí)行完成后自動關閉該服務
- Pipeline在編排的過程支持條件語句
- 若某項活動失敗,默認會不斷重試,所以需要配置限制重試次數(shù)或未成功時采取的行動
- 每個賬戶默認支持100個管道,單一管道中可以擁有100個對象,可以申請擴展
屬性
- 管道
- 即 AWS Data Pipeline 資源,其中包含由執(zhí)行業(yè)務邏輯所需的數(shù)據(jù)源、目的地和預定義或自定義數(shù)據(jù)處理活動所組成的關聯(lián)數(shù)據(jù)鏈的定義。
- 數(shù)據(jù)節(jié)點
- 數(shù)據(jù)節(jié)點代表您的業(yè)務數(shù)據(jù)。例如,數(shù)據(jù)節(jié)點可以表示特定的 Amazon S3 路徑。AWS Data Pipeline 支持表達式語言,使其更容易引用常態(tài)生成的數(shù)據(jù)。
- 活動
- 是 AWS Data Pipeline 代表您啟動的操作,它是管道的一部分。示例活動包括 EMR 或 Hive 作業(yè)、復制、SQL 查詢或命令行腳本。
- 前提條件
- 前提條件是指成熟度檢查,可選擇性地將其關聯(lián)到數(shù)據(jù)源或活動。如果數(shù)據(jù)源具有前提條件檢查,那么必須先成功完成檢查,然后才能啟動任何需要用到該數(shù)據(jù)源的活動。如果活動具有前提條件,那么必須先成功完成檢查,然后才能運行活動。
- 時間表
- 定義管道活動運行的時間和服務預計的可使用數(shù)據(jù)的頻率。可以選擇時間表結束日期,在此時間后,AWS Data Pipeline 服務不執(zhí)行任何活動。
- 當您將時間表與活動關聯(lián)起來后,活動就會按時間表運行。當您將時間表與數(shù)據(jù)源關聯(lián)起來,就表示您告訴 AWS Data Pipeline 服務,您期望數(shù)據(jù)會按照該時間表更新。
適用場景
- 非常適用于常規(guī)批處理的ETL流程,而不是連續(xù)數(shù)據(jù)流
Amazon Elastic Transcoder
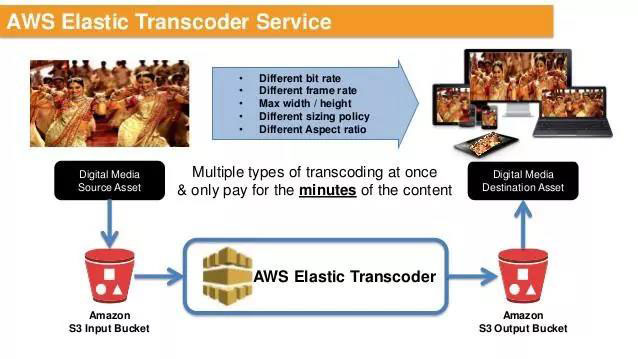
- 一種在線媒體轉碼的工具
- 將視頻從源格式轉換到其他的格式和分辨率,以便在手機、平板、PC等設備上播放
- 一般來說,將需要轉碼的媒體文件放在AWS S3的存儲桶上,創(chuàng)建相應的管道和任務將文件轉碼為特定的格式,最后將文件輸出到另一個S3的存儲桶上面去。
- 也可以使用一些預設的模板來轉換媒體格式。
- 可以配合Lambda函數(shù),在有新的文件上傳到S3后觸發(fā)函數(shù)代碼,執(zhí)行Elastic Transcoder并自動進行媒體文件的轉碼。
Amazon Athena
- Amazon Athena 是一種交互式查詢服務,讓您能夠輕松使用標準 SQL 分析 Amazon S3 中的數(shù)據(jù)。Athena 沒有服務器,因此您無需管理任何基礎設施,且只需為您運行的查詢付費。
- Athena 簡單易用。只需指向您存儲在 Amazon S3 中的數(shù)據(jù),定義架構并使用標準 SQL 開始查詢就可在數(shù)秒內獲取最多的結果。
- 使用 Athena,無需執(zhí)行復雜的 ETL 作業(yè)來為數(shù)據(jù)分析做準備。這樣一來,具備 SQL 技能的任何人都可以輕松快速地分析大規(guī)模數(shù)據(jù)集。
- 支持的數(shù)據(jù)格式包括 JSON,Apache Parquet, Apache ORC
Amazon Elasticsearch Service
- Amazon Elasticsearch Service 是一項完全托管的服務,方便您部署、保護和運行大量 Elasticsearch 操作,且不用停機。
- 該服務提供開源 Elasticsearch API、受托管的 Kibana 以及與 Logstash 和其他 AWS 服務的集成,支持您安全獲取任何來源的數(shù)據(jù),并開展實時搜索、分析和可視化。
- 使用 Amazon Elasticsearch Service 時,您只需按實際用量付費,沒有預付成本或使用要求。有了 Amazon Elasticsearch Service,您無需承擔運營開銷,便可獲得所需的 ELK 堆棧。
AWS X-Ray
- AWS X-Ray 可以幫助開發(fā)人員分析與調試分布式生產應用程序,例如使用微服務架構構建的應用程序。
- 借助 X-Ray,您可以了解應用程序及其底層服務的執(zhí)行方式,從而識別和排查導致性能問題和錯誤的根本原因。
- X-Ray 可在請求通過應用程序時提供請求的端到端視圖,并展示應用程序底層組件的映射。
- 您可以使用 X-Ray 分析開發(fā)和生產中的應用程序,從簡單的三層應用程序到包含上千種服務的復雜微服務應用程序。
分享文章:AWS數(shù)據(jù)分析服務(十)
網(wǎng)頁URL:http://chinadenli.net/article8/gjoeip.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供軟件開發(fā)、全網(wǎng)營銷推廣、響應式網(wǎng)站、網(wǎng)站導航、定制開發(fā)、企業(yè)網(wǎng)站制作
聲明:本網(wǎng)站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經(jīng)允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)

- 面包屑導航優(yōu)化原則都有什么? 2022-06-14
- 雖不是主欄目面包屑導航在網(wǎng)站中的重要性仍舊毋庸置疑 2022-05-22
- 網(wǎng)站可用性面包屑導航的設計 2022-06-19
- 網(wǎng)站建設面包屑導航需好好規(guī)劃 2016-10-25
- 詳細介紹下頁面中面包屑導航的作用 2023-03-02
- 網(wǎng)站優(yōu)化先行官:面包屑導航 2021-10-13
- 優(yōu)秀網(wǎng)站建設面包屑導航運用不可忽視 2023-02-23
- 網(wǎng)站優(yōu)化先行官面包屑導航 2021-10-18
- 什么是面包屑導航和它的作用是什么 2021-09-21
- 做seo我們要避免做這些對我們的網(wǎng)站 2022-06-20
- 網(wǎng)站建設中面包屑導航有哪些作用? 2022-10-01
- 設置面包屑導航,能提升蜘蛛抓取么? 2023-04-04