MYSQL(四)查詢性能優(yōu)化
優(yōu)化數(shù)據(jù)訪問
吳興網(wǎng)站制作公司哪家好,找創(chuàng)新互聯(lián)!從網(wǎng)頁設(shè)計、網(wǎng)站建設(shè)、微信開發(fā)、APP開發(fā)、響應(yīng)式網(wǎng)站建設(shè)等網(wǎng)站項目制作,到程序開發(fā),運營維護。創(chuàng)新互聯(lián)公司2013年成立到現(xiàn)在10年的時間,我們擁有了豐富的建站經(jīng)驗和運維經(jīng)驗,來保證我們的工作的順利進行。專注于網(wǎng)站建設(shè)就選創(chuàng)新互聯(lián)。
1.是否向數(shù)據(jù)庫請求了不需要的數(shù)據(jù)
解決方式:
A. 查詢后加limit
B. Select后寫需要的列而不是*
2. 是否掃描了額外的數(shù)據(jù)
數(shù)據(jù)庫的訪問方式速度由慢到快:全表掃描,索引掃描,范圍掃描,唯一索引查詢,常數(shù)引用
MySQL Explain命令 的type(數(shù)據(jù)庫引擎訪問表的方式):Const > ref > range > index > all
1. const 常數(shù)引用
如果是根據(jù)主鍵查詢,將會將查詢轉(zhuǎn)化為一個常數(shù),只取出確定的一行數(shù)據(jù)。是最快的一種。
2. Ref
查找條件列使用了索引而且不為主鍵和unique(值允許重復(fù)),只取出確定值的數(shù)據(jù),可能多行。
3. ref_eq 唯一索引查詢
ref_eq 與 ref相比,這種類型的查找結(jié)果集只有一個
4. range 范圍掃描
索引或主鍵,在某個范圍內(nèi)時
4. index 索引掃描
僅僅只有索引被掃描
5. all 全表掃描
一般mysql應(yīng)用where條件的方式由好到壞:
1. 在索引中使用where條件過濾,這是在存儲引擎層完成;
2. 使用索引覆蓋掃描,直接從索引中過濾不需要的數(shù)據(jù)并返回結(jié)果,這是在mysql服務(wù)器層完成,無需再回表查詢(在extra中出現(xiàn)using index)
3. 從數(shù)據(jù)表中返回數(shù)據(jù),然后過濾不滿足條件的數(shù)據(jù),在服務(wù)器層完成,mysql需要先從數(shù)據(jù)表讀出記錄然后過濾(在extra中出現(xiàn)using where)
好的索引可以讓查詢使用合適的訪問類型,減少掃描的數(shù)據(jù)行數(shù)。
執(zhí)行查詢的基礎(chǔ):
1. 客戶端發(fā)送一條查詢給服務(wù)器
2. 服務(wù)器先檢查緩存,如果命中緩存,立刻返回結(jié)果
3. 服務(wù)器進行sql解析,預(yù)處理,再由優(yōu)化器生成對應(yīng)執(zhí)行計劃
4. Mysql根據(jù)優(yōu)化器生成的執(zhí)行計劃,調(diào)用存儲引擎API執(zhí)行查詢計劃
5. 將結(jié)果返回給客戶端
第一步(客戶端發(fā)送一條查詢給服務(wù)器):
Mysql客戶端與服務(wù)器之間的通信是半雙工的,要么由服務(wù)器向客戶端發(fā)送數(shù)據(jù),要么由客戶端向服務(wù)器發(fā)送數(shù)據(jù),不能同時進行;
所以為了進行流量控制,客戶端發(fā)送查詢語句過長時,超過max_allowed_packet參數(shù),服務(wù)器會拋出相應(yīng)錯誤。
客戶端從服務(wù)器獲取數(shù)據(jù)時,多數(shù)連接mysql的庫函數(shù)都可以獲得全部結(jié)果集并緩存到內(nèi)存里,mysql需要等所有數(shù)據(jù)都發(fā)給客戶端才能釋放這條查詢所占用的資源;
第三步(服務(wù)器進行sql解析、預(yù)處理、查詢優(yōu)化):
首先,通過關(guān)鍵字將sql語句進行解析,生成一顆“解析樹”;
解析器驗證語法規(guī)則;
預(yù)處理器檢查解析樹是否合法,驗證權(quán)限;
查詢優(yōu)化器使用優(yōu)化策略生成一個最優(yōu)的執(zhí)行計劃:
1. 重新定義關(guān)聯(lián)表的順序
2. 將外連接轉(zhuǎn)化為內(nèi)連接
3. 優(yōu)化count(),min(),max()(根據(jù)b-tree只讀取第一條或最后一條數(shù)據(jù))
4. 預(yù)估并轉(zhuǎn)化為常數(shù)表達式
5. 提前終止查詢
6. 列表in()的比較(將in列表的數(shù)據(jù)先排序,通過二分查找確定值是否滿足條件)
生成一個執(zhí)行計劃——指令樹:因為mysql的關(guān)聯(lián)從一張表開始嵌套,所以執(zhí)行計劃是一顆左側(cè)深度優(yōu)先的樹。
第四步(調(diào)用存儲引擎API執(zhí)行查詢計劃)
查詢優(yōu)化器在服務(wù)器層,而統(tǒng)計信息(每個表或索引有多少頁,每個表的每個索引的基數(shù)是多少,數(shù)據(jù)行和索引長度,索引的分布信息等)在存儲引擎層;
MYSQL執(zhí)行關(guān)聯(lián)查詢方式:
Mysql認(rèn)為任何一次查詢都是一次關(guān)聯(lián),并不僅僅一次查詢關(guān)系到兩張表時。
在MySQL 中,只有一種 Join 算法,就是 Nested Loop Join嵌套迭代。
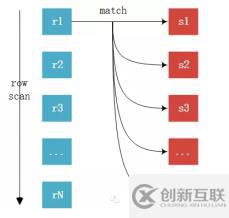
Simple Nested-Loop Join簡單嵌套循環(huán):從驅(qū)動表中取出R1匹配S表所有列,然后R2,R3,直到將R表中的所有數(shù)據(jù)匹配完,然后合并數(shù)據(jù),可以看到這種算法要對S表進行RN次訪問,雖然簡單,但是相對來說開銷還是太大了。
Index Nested-Loop Join索引嵌套循環(huán):由于非驅(qū)動表上有索引,所以比較的時候不再需要一條條記錄進行比較,而可以通過索引來減少比較,從而加速查詢。
優(yōu)化:
選擇記錄數(shù)少的作為驅(qū)動表;
優(yōu)先優(yōu)化NestedLoop的內(nèi)層循環(huán);
保證被驅(qū)動表上Join條件字段已經(jīng)被索引
Mysql查詢優(yōu)化器的局限性
1.關(guān)聯(lián)子查詢
使用in加子查詢,性能非常糟糕
//未完
2. 最大值和最小值
對于max()和min()查詢,mysql的優(yōu)化并不好,如:
Select min(actor_id) from sakila.actor where first_name = “pene”;
因為first_name字段上沒有索引,所以mysql會進行一次全表掃描;
一個優(yōu)化辦法是:(使mysql進行主鍵掃描)
select actor_id from sakila.actor use index(primary) where first_name = “pene” limit 1;
用主建索引查詢,因為b-tree是按照主鍵順序排序,所以limit 1 = min(actor_id),查找索引直到復(fù)合where條件的第一條數(shù)據(jù)
當(dāng)前名稱:MYSQL(四)查詢性能優(yōu)化
文章鏈接:http://chinadenli.net/article48/ihogep.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供手機網(wǎng)站建設(shè)、微信小程序、ChatGPT、面包屑導(dǎo)航、服務(wù)器托管、網(wǎng)站建設(shè)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 作為四年的軟件開發(fā)人員,五個重要經(jīng)驗教訓(xùn) 2021-05-22
- 上海APP軟件開發(fā)之手游陪玩 2023-02-12
- 傳統(tǒng)軟件開發(fā)架構(gòu)向基于云平臺轉(zhuǎn)型之路 2016-08-02
- 搬家APP軟件開發(fā)詳細(xì)優(yōu)勢分析 2022-05-26
- 成都現(xiàn)代化家居APP軟件開發(fā),成都現(xiàn)代化家居APP軟件制作 2022-06-24
- 哈爾濱app軟件開發(fā)趨勢如何把握 2020-12-30
- 虛擬試衣間軟件開發(fā)可以帶來哪些收益 2022-06-05
- 手機APP軟件開發(fā)情景式消費,打造健康社交平臺 2022-06-27
- 成都在線答題APP軟件開發(fā),成都在線答題APP軟件制作 2022-06-20
- 軟件開發(fā)者必備的軟技能有哪些? 2021-06-13
- 選擇軟件開發(fā)的時容易犯的錯誤 2017-01-05
- APP軟件開發(fā)需要什么技術(shù)? 2023-01-04