python爬蟲scrapy框架基礎(chǔ)-創(chuàng)新互聯(lián)
我使用的軟件是pychram

最近幾周也一直在學(xué)習(xí)scrapy,發(fā)現(xiàn)知識點(diǎn)比較混亂,今天來總結(jié)一下。我是按照《精通python網(wǎng)絡(luò)爬蟲核心技術(shù)框架與項(xiàng)目實(shí)戰(zhàn)》這本書來寫的。講的比較簡潔,想要詳細(xì)了解的可以看看書或者視頻。
scrapy框架運(yùn)行的原理
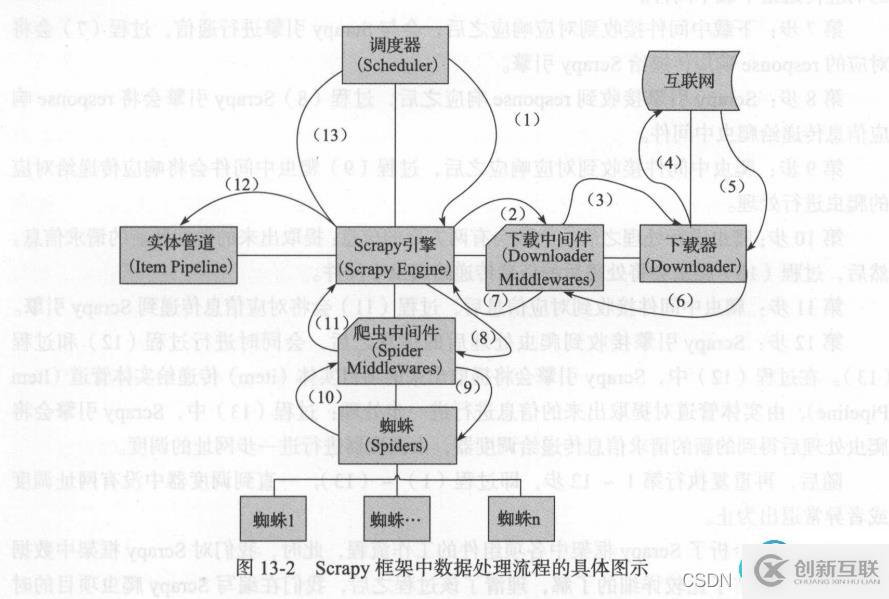
首先scrapy引擎會將蜘蛛爬蟲(spider)中設(shè)置的起始網(wǎng)址傳遞到調(diào)度器中
第一步:過程(1)是調(diào)度器(Scheduler)將要爬取的網(wǎng)址傳遞到scrapy引擎中,調(diào)度器是一個優(yōu)先隊(duì)列,根據(jù)優(yōu)先級按順序傳遞到scrapy引擎中
第二步:過程(2)是scrapy收到調(diào)度器(Scheduler)傳遞的網(wǎng)址,將網(wǎng)址傳給下載中間件(Downloader Middlewares)
第三步:過程(3)是下載中間件(Downloader Middlewares)將收到的網(wǎng)址傳遞給下載器
第四步:下載器接收到要下載的網(wǎng)址,過程(4)是下載器向互聯(lián)網(wǎng)發(fā)送request請求,進(jìn)行網(wǎng)頁的下載
第五步:互聯(lián)網(wǎng)中對應(yīng)的網(wǎng)址收到request請求之后,會有相應(yīng)的response響應(yīng),過程(5)是將response響應(yīng)傳給下載器
第六步:下載器接收到了response響應(yīng)即對網(wǎng)址進(jìn)行了下載,過程(6)將對應(yīng)的響應(yīng)傳送給下載中間件
第七步:下載中間件收到response請求后,與scrapy引擎通信,過程(7)是將response響應(yīng)傳到scrapy引擎
第八步:過程(8)是scrapy引擎將response響應(yīng)傳給爬蟲中間件
第九步:過程(9)是爬蟲中間件將response響應(yīng)傳給對應(yīng)的蜘蛛爬蟲(spider)進(jìn)行處理
第十步:蜘蛛爬蟲(spider)進(jìn)行處理response響應(yīng),一般會有兩個東西,提取出來的數(shù)據(jù)和新的請求信息,然后過程(10)將處理后的信息傳遞給爬蟲中間件
第十一步:過程(11)是爬蟲中間件將處理后的信息傳給scrapy引擎
第十二步:scrapy引擎收到爬蟲處理后的信息之后,會同時(shí)進(jìn)行過程(12)和過程(13),過程(12)將提取出來的項(xiàng)目實(shí)體item傳遞給實(shí)體管道,由實(shí)體管道(Pipeline)做進(jìn)一步的信息處理,過程(13)是將提取出來的新的請求信息傳遞給調(diào)度器,由調(diào)度器對網(wǎng)址進(jìn)一步傳遞
整個過程就是不斷的重復(fù)過程(1)到過程(13),直到調(diào)度器沒有可傳遞的網(wǎng)址為止
以下是我做的筆記
一.認(rèn)識scrapy的目錄結(jié)構(gòu)
以我自己的一個項(xiàng)目為例,使用scrapy創(chuàng)建一個爬蟲項(xiàng)目,他會同時(shí)生成一個與爬蟲項(xiàng)目名稱相同的文件夾,這里是spider1128(主文件夾后面我自己重命名了)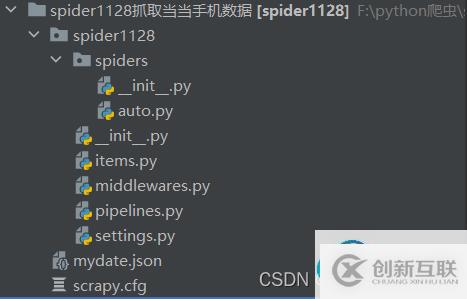
同名子文件夾放置的是項(xiàng)目的核心代碼,其中scrapy.cfg是爬蟲項(xiàng)目的配置文件,spiders文件下,除了auto.py是自己創(chuàng)建的編寫文件之外,其他都是創(chuàng)建項(xiàng)目時(shí)附帶的。后面將會詳細(xì)的講解這些配置文件的作用
二.用scrapy進(jìn)行項(xiàng)目的創(chuàng)建
1.2.創(chuàng)建項(xiàng)目命令 在軟件的終端中使用這個命令?scrapy startproject 項(xiàng)目名

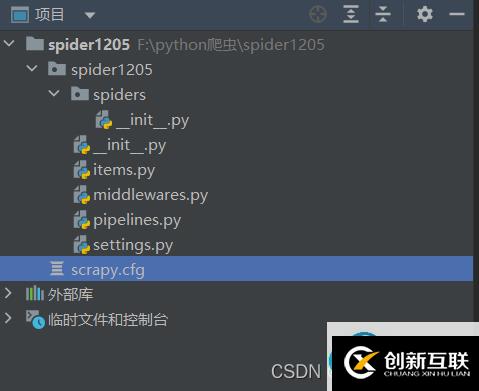
然后就可以在指定目錄中找到這個項(xiàng)目啦~~~~
2.在項(xiàng)目路徑下創(chuàng)建爬蟲文件 scrapy genspider 文件名 域名
爬蟲文件有basic crawl csvfeed xmlfeed 這幾個模板,若要指定模板可用命令 scrapy genspider -t 模板 文件名 域名 若沒有指定,則默認(rèn)basic模板
我這里創(chuàng)建了bookdate這個爬蟲文件,要爬取的域名為dangdang.com
![]()
-------------------------
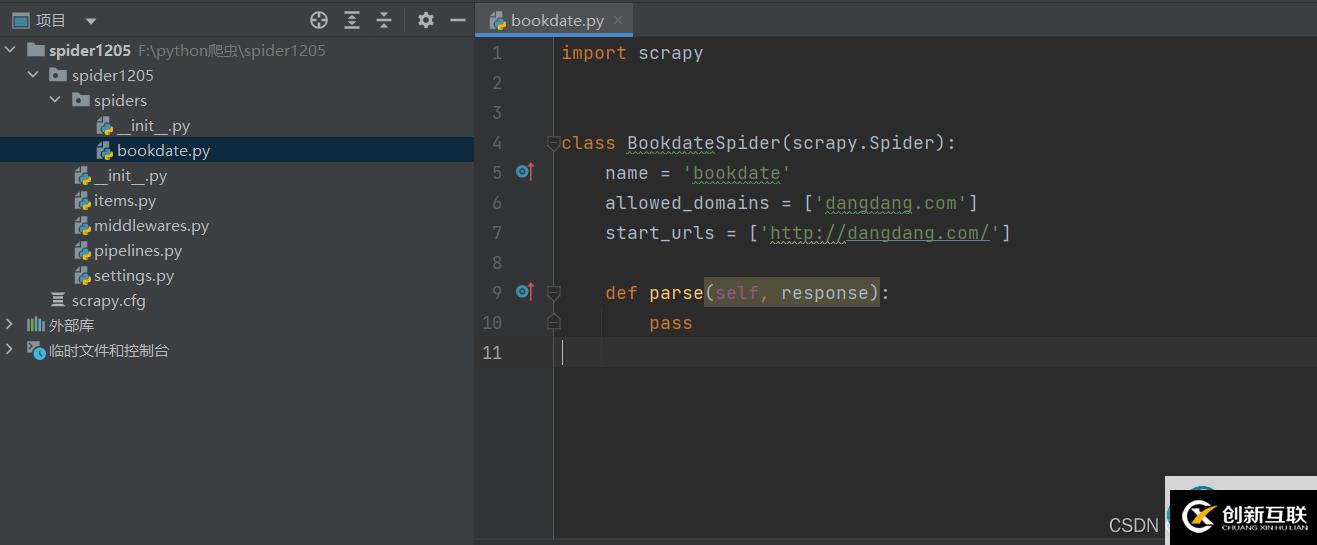
這樣整個項(xiàng)目已經(jīng)創(chuàng)建好了,剩下就是編寫代碼的
---------------------------------
三.運(yùn)行爬蟲軟件
在終端輸入命令 scrapy crawl 爬蟲名字 運(yùn)行即可
你是否還在尋找穩(wěn)定的海外服務(wù)器提供商?創(chuàng)新互聯(lián)www.cdcxhl.cn海外機(jī)房具備T級流量清洗系統(tǒng)配攻擊溯源,準(zhǔn)確流量調(diào)度確保服務(wù)器高可用性,企業(yè)級服務(wù)器適合批量采購,新人活動首月15元起,快前往官網(wǎng)查看詳情吧
網(wǎng)站名稱:python爬蟲scrapy框架基礎(chǔ)-創(chuàng)新互聯(lián)
本文網(wǎng)址:http://chinadenli.net/article46/gcghg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站制作、外貿(mào)網(wǎng)站建設(shè)、小程序開發(fā)、Google、商城網(wǎng)站、網(wǎng)站設(shè)計(jì)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 有哪些usb接口類型-創(chuàng)新互聯(lián)
- Layui事件監(jiān)聽的方法有哪些-創(chuàng)新互聯(lián)
- 好程序員Python培訓(xùn)分享Python系列之循環(huán)結(jié)構(gòu)-創(chuàng)新互聯(lián)
- HTML5中實(shí)現(xiàn)圖片拖放的方法-創(chuàng)新互聯(lián)
- 怎么使用代碼獲得HybrisCommerce里顯示的產(chǎn)品圖片-創(chuàng)新互聯(lián)
- length、lengthb與substr怎么在oracle中使用-創(chuàng)新互聯(lián)
- 淺談Python多進(jìn)程默認(rèn)不能共享全局變量的問題-創(chuàng)新互聯(lián)

- 網(wǎng)絡(luò)營銷中全網(wǎng)營銷對企業(yè)有什么幫助? 2014-08-02
- 北京全網(wǎng)營銷外包公司敘述新聞營銷的巨大價(jià)值 2015-07-11
- 全網(wǎng)營銷推廣方案 2022-12-17
- 全網(wǎng)營銷推廣對企業(yè)非常重要 2022-12-30
- 全網(wǎng)營銷推廣,讓成交變得簡單 2016-11-08
- 全網(wǎng)營銷比傳統(tǒng)營銷的優(yōu)勢體現(xiàn)在哪方面? 2014-10-19
- 你知道全網(wǎng)營銷推廣具體指的哪些方面嗎 2021-09-05
- 全網(wǎng)營銷推廣:網(wǎng)站URL優(yōu)化策略大全 2016-11-07
- 全網(wǎng)營銷比傳統(tǒng)營銷有哪些優(yōu)勢? 2015-06-23
- 網(wǎng)站建設(shè)全網(wǎng)營銷的轉(zhuǎn)型速度 2016-10-28
- 開展全網(wǎng)營銷推廣的5個步驟 2016-11-11
- 企業(yè)該如何做好全網(wǎng)營銷推廣? 2015-06-11