Python如何爬取微信公眾號(hào)文章
本篇內(nèi)容介紹了“Python如何爬取微信公眾號(hào)文章”的有關(guān)知識(shí),在實(shí)際案例的操作過(guò)程中,不少人都會(huì)遇到這樣的困境,接下來(lái)就讓小編帶領(lǐng)大家學(xué)習(xí)一下如何處理這些情況吧!希望大家仔細(xì)閱讀,能夠?qū)W有所成!
創(chuàng)新互聯(lián)建站專(zhuān)注于企業(yè)成都全網(wǎng)營(yíng)銷(xiāo)、網(wǎng)站重做改版、夏河網(wǎng)站定制設(shè)計(jì)、自適應(yīng)品牌網(wǎng)站建設(shè)、HTML5、成都做商城網(wǎng)站、集團(tuán)公司官網(wǎng)建設(shè)、外貿(mào)營(yíng)銷(xiāo)網(wǎng)站建設(shè)、高端網(wǎng)站制作、響應(yīng)式網(wǎng)頁(yè)設(shè)計(jì)等建站業(yè)務(wù),價(jià)格優(yōu)惠性?xún)r(jià)比高,為夏河等各大城市提供網(wǎng)站開(kāi)發(fā)制作服務(wù)。
為了實(shí)現(xiàn)該爬蟲(chóng)我們需要用到如下工具
Chrome瀏覽器
Python 3 語(yǔ)法知識(shí)
Python的Requests庫(kù)
此外,這個(gè)爬取程序利用的是微信公眾號(hào)后臺(tái)編輯素材界面。原理是,當(dāng)我們?cè)诓迦氤溄訒r(shí),微信會(huì)調(diào)用專(zhuān)門(mén)的API(見(jiàn)下圖),以獲取指定公眾號(hào)的文章列表。因此,我們還需要有一個(gè)公眾號(hào)。

正式開(kāi)始
我們需要登錄微信公眾號(hào),點(diǎn)擊素材管理,點(diǎn)擊新建圖文消息,然后點(diǎn)擊上方的超鏈接。
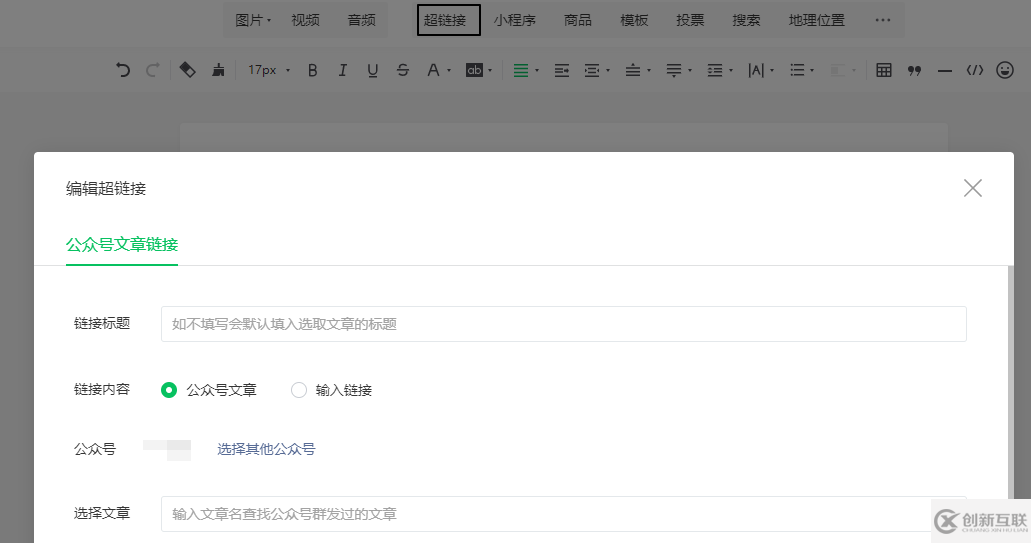
接著,按F12,打開(kāi)Chrome的開(kāi)發(fā)者工具,選擇Network
此時(shí)在之前的超鏈接界面中,點(diǎn)擊「選擇其他公眾號(hào)」,輸入你需要爬取的公眾號(hào)(例如中國(guó)移動(dòng))
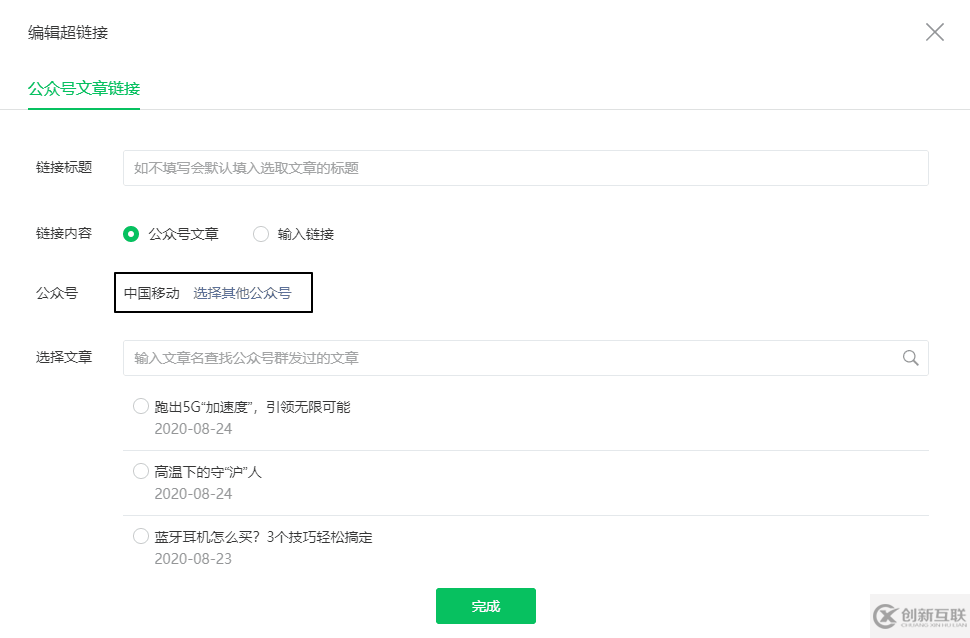
此時(shí)之前的Network就會(huì)刷新出一些鏈接,其中以"appmsg"開(kāi)頭的便是我們需要分析的內(nèi)容
我們解析請(qǐng)求的URL
https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MzI1MjU5MjMzNA==&type=9&query=&token=143406284&lang=zh_CN&f=json&ajax=1
它分為三個(gè)部分
https://mp.weixin.qq.com/cgi-bin/appmsg: 請(qǐng)求的基礎(chǔ)部分
?action=list_ex: 常用于動(dòng)態(tài)網(wǎng)站,實(shí)現(xiàn)不同的參數(shù)值而生成不同的頁(yè)面或者返回不同的結(jié)果
&begin=0&count=5&fakeid: 用于設(shè)置?里的參數(shù),即begin=0, count=5
通過(guò)不斷的瀏覽下一頁(yè),我們發(fā)現(xiàn)每次只有begin會(huì)發(fā)生變動(dòng),每次增加5,也就是count的值。
接著,我們通過(guò)Python來(lái)獲取同樣的資源,但直接運(yùn)行如下代碼是無(wú)法獲取資源的
import requests
url = "https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MzI1MjU5MjMzNA==&type=9&query=&token=1957521839&lang=zh_CN&f=json&ajax=1"
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}我們之所以能在瀏覽器上獲取資源,是因?yàn)槲覀兊卿浟宋⑿殴娞?hào)后端。而Python并沒(méi)有我們的登錄信息,所以請(qǐng)求是無(wú)效的。我們需要在requests中設(shè)置headers參數(shù),在其中傳入Cookie和User-Agent,來(lái)模擬登陸
由于每次頭信息內(nèi)容都會(huì)變動(dòng),因此我將這些內(nèi)容放入在單獨(dú)的文件中,即"wechat.yaml",信息如下
cookie: ua_id=wuzWM9FKE14... user_agent: Mozilla/5.0...
之后只需要讀取即可
# 讀取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
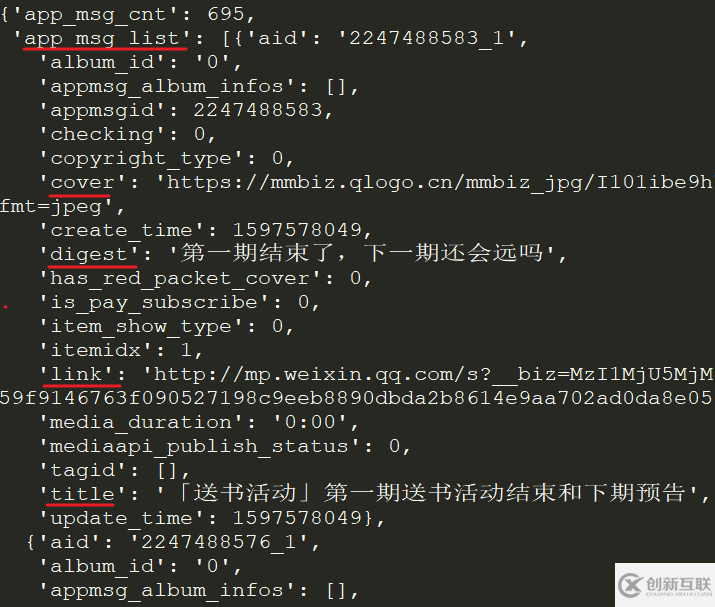
requests.get(url, headers=headers, verify=False).json()在返回的JSON中,我們就看到了每個(gè)文章的標(biāo)題(title), 摘要(digest), 鏈接(link), 推送時(shí)間(update_time)和封面地址(cover)等信息。
appmsgid是每一次推送的唯一標(biāo)識(shí)符,aid則是每篇推文的唯一標(biāo)識(shí)符。
實(shí)際上,除了Cookie外,URL中的token參數(shù)也會(huì)用來(lái)限制爬蟲(chóng),因此上述代碼很有可能輸出會(huì)是{'base_resp': {'ret': 200040, 'err_msg': 'invalid csrf token'}}
接著我們寫(xiě)一個(gè)循環(huán),獲取所有文章的JSON,并進(jìn)行保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 請(qǐng)求參數(shù)
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放結(jié)果
app_msg_list = []
# 在不知道公眾號(hào)有多少文章的情況下,使用while語(yǔ)句
# 也方便重新運(yùn)行時(shí)設(shè)置頁(yè)數(shù)
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 隨機(jī)暫停幾秒,避免過(guò)快的請(qǐng)求導(dǎo)致過(guò)快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的內(nèi)容中為空則結(jié)束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻頁(yè)
i += 1在上面代碼中,我將fakeid和token也存放在了"wechat.yaml"文件中,這是因?yàn)閒akeid是每個(gè)公眾號(hào)都特有的標(biāo)識(shí)符,而token則會(huì)經(jīng)常性變動(dòng),該信息既可以通過(guò)解析URL獲取,也可以從開(kāi)發(fā)者工具中查看
在爬取一段時(shí)間后,就會(huì)遇到如下的問(wèn)題
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}此時(shí)你在公眾號(hào)后臺(tái)嘗試插入超鏈接時(shí)就能遇到如下這個(gè)提示

這是公眾號(hào)的流量限制,通常需要等上30-60分鐘才能繼續(xù)。為了完美處理這個(gè)問(wèn)題,你可能需要申請(qǐng)多個(gè)公眾號(hào),可能需要和微信公眾號(hào)的登錄系統(tǒng)斗智斗勇,或許還需要設(shè)置代理池。
但是我并不需要一個(gè)工業(yè)級(jí)別的爬蟲(chóng),只想爬取自己公眾號(hào)的信息,因此等個(gè)一小時(shí),重新登錄公眾號(hào),獲取cookie和token,然后運(yùn)行即可。我可不想用自己的興趣挑戰(zhàn)別人的飯碗。
最后將結(jié)果以JSON格式保存。
# 保存結(jié)果為JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))或者提取文章標(biāo)識(shí)符,標(biāo)題,URL,發(fā)布時(shí)間這四列信息,保存成CSV。
info_list = [] for msg in app_msg_list: if "app_msg_list">
最終代碼如下(代碼可能有bug,謹(jǐn)慎使用),使用方法為python wechat_parser.py wechat.yaml
import json
import requests
import time
import random
import os
import yaml
import sys
if len(sys.argv) < 2:
print("too few arguments")
sys.exit(1)
yaml_file = sys.argv[1]
if not os.path.exists(yaml_file):
print("yaml_file is not exists")
sys.exit(1)
with open(yaml_file, "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 請(qǐng)求參數(shù)
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放結(jié)果
if os.path.exists("mp_data.json"):
with open("mp_data.json", "r") as file:
app_msg_list = json.load(file)
else:
app_msg_list = []
# 在不知道公眾號(hào)有多少文章的情況下,使用while語(yǔ)句
# 也方便重新運(yùn)行時(shí)設(shè)置頁(yè)數(shù)
i = len(app_msg_list)
while True:
begin = i * 5
params["begin"] = str(begin)
# 隨機(jī)暫停幾秒,避免過(guò)快的請(qǐng)求導(dǎo)致過(guò)快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的內(nèi)容中為空則結(jié)束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻頁(yè)
i += 1
# 保存結(jié)果為JSON
json_name = "mp_data.json"
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))“Python如何爬取微信公眾號(hào)文章”的內(nèi)容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業(yè)相關(guān)的知識(shí)可以關(guān)注創(chuàng)新互聯(lián)網(wǎng)站,小編將為大家輸出更多高質(zhì)量的實(shí)用文章!
當(dāng)前標(biāo)題:Python如何爬取微信公眾號(hào)文章
網(wǎng)站網(wǎng)址:http://chinadenli.net/article44/jiishe.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供做網(wǎng)站、網(wǎng)站排名、品牌網(wǎng)站制作、標(biāo)簽優(yōu)化、網(wǎng)站設(shè)計(jì)、網(wǎng)站建設(shè)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶(hù)投稿、用戶(hù)轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話(huà):028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 國(guó)際域名注冊(cè)要實(shí)名認(rèn)證了? 2014-02-21
- 域名注冊(cè)哪家強(qiáng)? 2022-07-05
- 互聯(lián)網(wǎng)域名注冊(cè)那些事兒 2021-03-07
- .top域名注冊(cè)量躍居全球新頂級(jí)域名首位! 2021-02-28
- 域名注冊(cè)-企業(yè)注冊(cè)域名需要注意哪些問(wèn)題? 2016-11-10
- 注冊(cè)域名需要考慮什么? 2016-08-27
- 如何查找域名注冊(cè)商及空間注冊(cè)商 2018-08-01
- 用域名注冊(cè)量來(lái)畫(huà)地圖,你見(jiàn)過(guò)嗎? 2021-03-05
- 什么是域名注冊(cè)?什么樣的會(huì)是好域名? 2016-11-15
- 什么是域名注冊(cè)什么樣的會(huì)是好域名 2021-10-17
- 關(guān)于網(wǎng)站域名注冊(cè)和國(guó)際國(guó)內(nèi)域名的問(wèn)題解答 2022-08-15
- 域名注冊(cè)商 godaddy被指在托管網(wǎng)站頁(yè)面植入腳本 2021-04-02