python出現(xiàn)nan的解決方法-創(chuàng)新互聯(lián)
創(chuàng)新互聯(lián)www.cdcxhl.cn八線動態(tài)BGP香港云服務(wù)器提供商,新人活動買多久送多久,劃算不套路!
小編給大家分享一下python出現(xiàn)nan的解決方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討方法吧!
很多數(shù)據(jù)不可避免的會遺失掉,或者采集的時候采集對象不愿意透露,這就造成了很多NaN(Not a Number)的出現(xiàn)。這些NaN會造成大部分模型運行出錯,所以對NaN的處理很有必要。
解決方法:
1、簡單粗暴地去掉
1)有如下dataframe,先用df.isnull().sum()檢查下哪一列有多少NaN:
import pandas as pd
df = pd.DataFrame({'a':[None,1,2,3],'b':[4,None,None,6],'c':[1,2,1,2],'d':[7,7,9,2]})
print (df)
print (df.isnull().sum())輸出:

2)將含有NaN的列(columns)去掉:
data_without_NaN =df.dropna(axis=1) print (data_without_NaN)
輸出:

2、遺失值插補(bǔ)法
很多時候直接刪掉列會損失很多有價值的數(shù)據(jù),不利于模型的訓(xùn)練。
所以可以考慮將NaN替換成某些數(shù),顯然不能隨隨便便替換,有人喜歡替換成0,往往會畫蛇添足。
譬如調(diào)查工資收入與學(xué)歷高低的關(guān)系,有的人不想透露工資水平,但如果給這些NaN設(shè)置為0很顯然會失真。所以Python有個Imputation(插補(bǔ))的方法。代碼如下:
from sklearn.preprocessing import Imputer my_imputer = Imputer() data_imputed = my_imputer.fit_transform(df) print (type(data_imputed)) # array轉(zhuǎn)換成df df_data_imputed = pd.DataFrame(data_imputed,columns=df.columns) print (df_data_imputed)
輸出:
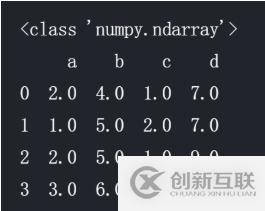
可以看出,這里大概是用平均值進(jìn)行了替換。
看完了這篇文章,相信你對python出現(xiàn)nan的解決方法有了一定的了解,想了解更多相關(guān)知識,歡迎關(guān)注創(chuàng)新互聯(lián)-成都網(wǎng)站建設(shè)公司行業(yè)資訊頻道,感謝各位的閱讀!
分享題目:python出現(xiàn)nan的解決方法-創(chuàng)新互聯(lián)
網(wǎng)站鏈接:http://chinadenli.net/article44/dphjhe.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站維護(hù)、小程序開發(fā)、網(wǎng)站設(shè)計、動態(tài)網(wǎng)站、自適應(yīng)網(wǎng)站、網(wǎng)站內(nèi)鏈
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 成都手機(jī)網(wǎng)站建設(shè)不可忽略的問題 2017-11-25
- 你的手機(jī)網(wǎng)站應(yīng)該這樣做嗎 2016-08-07
- 盧氏手機(jī)網(wǎng)站建設(shè)核心內(nèi)容要注重哪些 2020-12-21
- SSL證書:都聽我的,放不下手機(jī)的你必須知道 2016-09-14
- 網(wǎng)站制作中 電腦網(wǎng)站與手機(jī)網(wǎng)站有哪些區(qū)別 2016-09-04
- 手機(jī)網(wǎng)站建設(shè)如何才能美觀大方 2022-05-02
- 手機(jī)移動網(wǎng)站建設(shè)價格的其他因素有哪些? 2016-01-05
- 淺談手機(jī)網(wǎng)站建設(shè) 2016-10-02
- 移動手機(jī)網(wǎng)站如何優(yōu)化?簡單 2016-10-02
- 創(chuàng)新互聯(lián)網(wǎng)為您解答手機(jī)網(wǎng)站建設(shè)的三大注意點 2022-06-13
- 網(wǎng)站推廣中手機(jī)端的搜索優(yōu)化也很重要 2016-10-29
- 手機(jī)網(wǎng)站建設(shè)3點細(xì)節(jié)問題 2016-10-24