python中如何實(shí)現(xiàn)基于隨機(jī)梯度下降的矩陣分解推薦算法-創(chuàng)新互聯(lián)
這篇文章主要介紹python中如何實(shí)現(xiàn)基于隨機(jī)梯度下降的矩陣分解推薦算法,文中介紹的非常詳細(xì),具有一定的參考價(jià)值,感興趣的小伙伴們一定要看完!
雷山ssl適用于網(wǎng)站、小程序/APP、API接口等需要進(jìn)行數(shù)據(jù)傳輸應(yīng)用場(chǎng)景,ssl證書未來市場(chǎng)廣闊!成為創(chuàng)新互聯(lián)公司的ssl證書銷售渠道,可以享受市場(chǎng)價(jià)格4-6折優(yōu)惠!如果有意向歡迎電話聯(lián)系或者加微信:18980820575(備注:SSL證書合作)期待與您的合作!SVD是矩陣分解常用的方法,其原理為:矩陣M可以寫成矩陣A、B與C相乘得到,而B可以與A或者C合并,就變成了兩個(gè)元素M1與M2的矩陣相乘可以得到M。
矩陣分解推薦的思想就是基于此,將每個(gè)user和item的內(nèi)在feature構(gòu)成的矩陣分別表示為M1與M2,則內(nèi)在feature的乘積得到M;因此我們可以利用已有數(shù)據(jù)(user對(duì)item的打分)通過隨機(jī)梯度下降的方法計(jì)算出現(xiàn)有user和item最可能的feature對(duì)應(yīng)到的M1與M2(相當(dāng)于得到每個(gè)user和每個(gè)item的內(nèi)在屬性),這樣就可以得到通過feature之間的內(nèi)積得到user沒有打過分的item的分?jǐn)?shù)。
本文所采用的數(shù)據(jù)是movielens中的數(shù)據(jù),且自行切割成了train和test,但是由于數(shù)據(jù)量較大,沒有用到全部數(shù)據(jù)。
代碼如下:
# -*- coding: utf-8 -*-
"""
Created on Mon Oct 9 19:33:00 2017
@author: wjw
"""
import pandas as pd
import numpy as np
import os
def difference(left,right,on): #求兩個(gè)dataframe的差集
df = pd.merge(left,right,how='left',on=on) #參數(shù)on指的是用于連接的列索引名稱
left_columns = left.columns
col_y = df.columns[-1] # 得到最后一列
df = df[df[col_y].isnull()]#得到boolean的list
df = df.iloc[:,0:left_columns.size]#得到的數(shù)據(jù)里面還有其他同列名的column
df.columns = left_columns # 重新定義columns
return df
def readfile(filepath): #讀取文件,同時(shí)得到訓(xùn)練集和測(cè)試集
pwd = os.getcwd()#返回當(dāng)前工程的工作目錄
os.chdir(os.path.dirname(filepath))
#os.path.dirname()獲得filepath文件的目錄;chdir()切換到filepath目錄下
initialData = pd.read_csv(os.path.basename(filepath))
#basename()獲取指定目錄的相對(duì)路徑
os.chdir(pwd)#回到先前工作目錄下
predData = initialData.iloc[:,0:3] #將最后一列數(shù)據(jù)去掉
newIndexData = predData.drop_duplicates()
trainData = newIndexData.sample(axis=0,frac = 0.1) #90%的數(shù)據(jù)作為訓(xùn)練集
testData = difference(newIndexData,trainData,['userId','movieId']).sample(axis=0,frac=0.1)
return trainData,testData
def getmodel(train):
slowRate = 0.99
preRmse = 10000000.0
max_iter = 100
features = 3
lamda = 0.2
gama = 0.01 #隨機(jī)梯度下降中加入,防止更新過度
user = pd.DataFrame(train.userId.drop_duplicates(),columns=['userId']).reset_index(drop=True) #把在原來dataFrame中的索引重新設(shè)置,drop=True并拋棄
movie = pd.DataFrame(train.movieId.drop_duplicates(),columns=['movieId']).reset_index(drop=True)
userNum = user.count().loc['userId'] #671
movieNum = movie.count().loc['movieId']
userFeatures = np.random.rand(userNum,features) #構(gòu)造user和movie的特征向量集合
movieFeatures = np.random.rand(movieNum,features)
#假設(shè)每個(gè)user和每個(gè)movie有3個(gè)feature
userFeaturesFrame =user.join(pd.DataFrame(userFeatures,columns = ['f1','f2','f3']))
movieFeaturesFrame =movie.join(pd.DataFrame(movieFeatures,columns= ['f1','f2','f3']))
userFeaturesFrame = userFeaturesFrame.set_index('userId')
movieFeaturesFrame = movieFeaturesFrame.set_index('movieId') #重新設(shè)置index
for i in range(max_iter):
rmse = 0
n = 0
for index,row in user.iterrows():
uId = row.userId
userFeature = userFeaturesFrame.loc[uId] #得到userFeatureFrame中對(duì)應(yīng)uId的feature
u_m = train[train['userId'] == uId] #找到在train中userId點(diǎn)評(píng)過的movieId的data
for index,row in u_m.iterrows():
u_mId = int(row.movieId)
realRating = row.rating
movieFeature = movieFeaturesFrame.loc[u_mId]
eui = realRating-np.dot(userFeature,movieFeature)
rmse += pow(eui,2)
n += 1
userFeaturesFrame.loc[uId] += gama * (eui*movieFeature-lamda*userFeature)
movieFeaturesFrame.loc[u_mId] += gama*(eui*userFeature-lamda*movieFeature)
nowRmse = np.sqrt(rmse*1.0/n)
print('step:%f,rmse:%f'%((i+1),nowRmse))
if nowRmse<preRmse:
preRmse = nowRmse
elif nowRmse<0.5:
break
elif nowRmse-preRmse<=0.001:
break
gama*=slowRate
return userFeaturesFrame,movieFeaturesFrame
def evaluate(userFeaturesFrame,movieFeaturesFrame,test):
test['predictRating']='NAN' # 新增一列
for index,row in test.iterrows():
print(index)
userId = row.userId
movieId = row.movieId
if userId not in userFeaturesFrame.index or movieId not in movieFeaturesFrame.index:
continue
userFeature = userFeaturesFrame.loc[userId]
movieFeature = movieFeaturesFrame.loc[movieId]
test.loc[index,'predictRating'] = np.dot(userFeature,movieFeature) #不定位到不能修改值
return test
if __name__ == "__main__":
filepath = r"E:\學(xué)習(xí)\研究生\推薦系統(tǒng)\ml-latest-small\ratings.csv"
train,test = readfile(filepath)
userFeaturesFrame,movieFeaturesFrame = getmodel(train)
result = evaluate(userFeaturesFrame,movieFeaturesFrame,test)在test中得到的結(jié)果為:
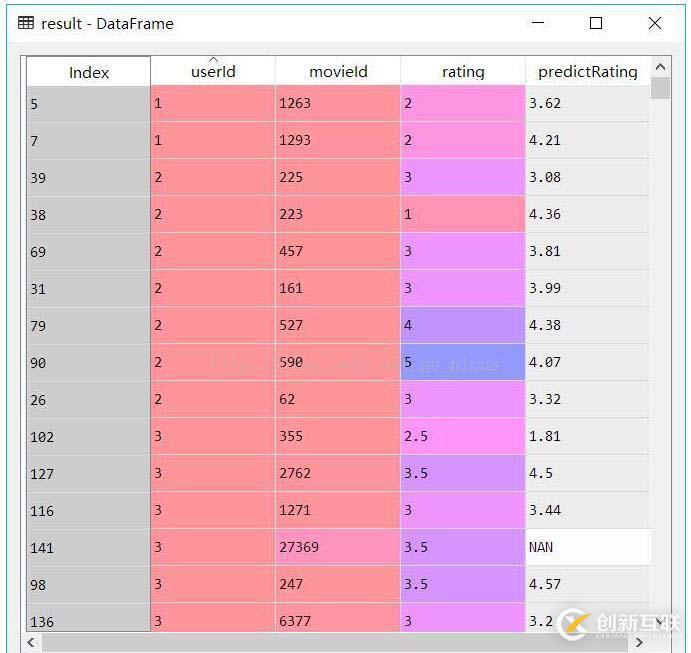
NAN則是訓(xùn)練集中沒有的數(shù)據(jù)
以上是“python中如何實(shí)現(xiàn)基于隨機(jī)梯度下降的矩陣分解推薦算法”這篇文章的所有內(nèi)容,感謝各位的閱讀!希望分享的內(nèi)容對(duì)大家有幫助,更多相關(guān)知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道!
當(dāng)前名稱:python中如何實(shí)現(xiàn)基于隨機(jī)梯度下降的矩陣分解推薦算法-創(chuàng)新互聯(lián)
本文網(wǎng)址:http://chinadenli.net/article44/ccjjhe.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供電子商務(wù)、移動(dòng)網(wǎng)站建設(shè)、App開發(fā)、靜態(tài)網(wǎng)站、網(wǎng)站營(yíng)銷、全網(wǎng)營(yíng)銷推廣
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- Java中BigDecimal的加減乘除、比較大小與使用注意事項(xiàng)-創(chuàng)新互聯(lián)
- jsp常用指令有哪些Java面試題目網(wǎng)站有哪些?-創(chuàng)新互聯(lián)
- php實(shí)現(xiàn)99乘法表的方法-創(chuàng)新互聯(lián)
- JavaScript中split()的用法介紹-創(chuàng)新互聯(lián)
- Vue中怎么根據(jù)條件添加click事件-創(chuàng)新互聯(lián)
- 怎么在Linux系統(tǒng)上檢查所安裝的SSH的版本-創(chuàng)新互聯(lián)
- JS運(yùn)動(dòng)特效之鏈?zhǔn)竭\(yùn)動(dòng)的示例分析-創(chuàng)新互聯(lián)

- 服務(wù)器托管前要做的幾個(gè)必要工作 2022-10-10
- 服務(wù)器托管一定要避免的9種機(jī)房現(xiàn)狀 2021-03-12
- 為什么企業(yè)進(jìn)行服務(wù)器托管更好? 2022-10-03
- 香港服務(wù)器托管費(fèi)用貴嗎?香港服務(wù)器托管有哪些優(yōu)勢(shì)? 2022-10-12
- 杭州服務(wù)器托管公司有哪些? 2021-03-17
- 企業(yè)要選服務(wù)器托管的原因是什么 2022-10-03
- 服務(wù)器托管的好處和優(yōu)勢(shì) 2022-10-13
- 什么是服務(wù)器?服務(wù)器托管與租用有什么不同? 2022-10-03
- 服務(wù)器托管的收費(fèi)標(biāo)準(zhǔn)通常是怎樣制定的? 2016-10-05
- 企業(yè)服務(wù)器托管有什么技巧?企業(yè)服務(wù)器托管該注意哪些問題? 2022-10-02
- 服務(wù)器托管與租用的區(qū)別 2021-03-01
- 海外服務(wù)器托管要留意這些方面 2022-10-05