Python使用爬蟲爬取靜態(tài)網(wǎng)頁圖片的方法詳解-創(chuàng)新互聯(lián)
本文實(shí)例講述了Python使用爬蟲爬取靜態(tài)網(wǎng)頁圖片的方法。分享給大家供大家參考,具體如下:

爬蟲理論基礎(chǔ)
其實(shí)爬蟲沒有大家想象的那么復(fù)雜,有時(shí)候也就是幾行代碼的事兒,千萬不要把自己嚇倒了。這篇就清晰地講解一下利用Python爬蟲的理論基礎(chǔ)。
首先說明爬蟲分為三個(gè)步驟,也就需要用到三個(gè)工具。
① 利用網(wǎng)頁下載器將網(wǎng)頁的源碼等資源下載。
② 利用URL管理器管理下載下來的URL
③ 利用網(wǎng)頁解析器解析需要的URL,進(jìn)而進(jìn)行匹配。
網(wǎng)頁下載器
網(wǎng)頁下載器常用的有兩個(gè)。一個(gè)是Python自帶的urllib2模塊;另一個(gè)是第三方控件requests。選用哪個(gè)其實(shí)差異不大,下一篇將會(huì)進(jìn)行實(shí)踐操作舉例。
URL管理器
url管理器有三大類。
① 內(nèi)存:以set形式存儲(chǔ)在內(nèi)存中
② 存儲(chǔ)在關(guān)系型數(shù)據(jù)庫mysql等
③ 緩存數(shù)據(jù)庫redis中
網(wǎng)頁解析器
網(wǎng)頁解析器一共有四類:
1.正則表達(dá)式,不過對(duì)于太復(fù)雜的匹配就會(huì)有些難度,屬于模糊匹配。
2.html.parser,這是python自帶的解析工具。
3.Beautiful Soup,一種第三方控件,顧名思義,美味的湯,用起來確實(shí)很方便,很強(qiáng)大。
4.lxml(apt.xml),第三方控件。
以上的這些全部屬于結(jié)構(gòu)化解析(DOM樹)
什么式結(jié)構(gòu)化解析(DOM)?
Document Object Model(DOM)是一種樹的形式。
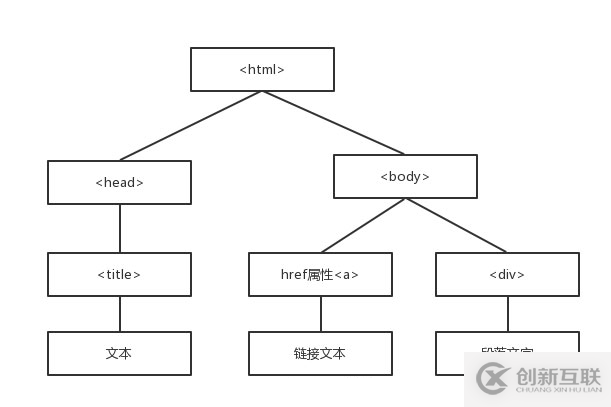
Beautiful Soup的語法
html網(wǎng)頁—>創(chuàng)建BeautifulSoup對(duì)象—>搜索節(jié)點(diǎn) find_all()/find()—>訪問節(jié)點(diǎn),名稱,屬性,文字等……
Beautiful Soup官方文檔
實(shí)現(xiàn)代碼
說過了理論基礎(chǔ),那么現(xiàn)在就來實(shí)踐一個(gè),要爬取一個(gè)靜態(tài)網(wǎng)頁的所有圖片。
這里使用的網(wǎng)頁下載器是python自帶的urllib2,然后利用正則表達(dá)式匹配,輸出結(jié)果。
以下為源碼:
//引入小需要用到的模塊
import urllib2
import re
def main():
//利用urllib2的urlopen方法,下載當(dāng)前url的網(wǎng)頁內(nèi)容
req = urllib2.urlopen('http://www.imooc.com/course/list')
//將網(wǎng)頁內(nèi)容存儲(chǔ)到buf變量中
buf = req.read()
//將buf中的所有內(nèi)容與需要匹配的url進(jìn)行比對(duì)。這里的正則表達(dá)式是根據(jù)靜態(tài)網(wǎng)頁的源碼得出的,查看靜態(tài)網(wǎng)頁源碼開啟開發(fā)者模式,按F12即可。然后確定圖片塊,查看對(duì)應(yīng)源碼內(nèi)容,找出規(guī)律,編寫正則表達(dá)式。
listurl = re.findall(r'src=.+\.jpg',buf)
i = 0
//將結(jié)果循環(huán)寫入文件
for url in listurl:
f = open(str(i)+'.jpg','w')
req = urllib2.urlopen(url[5:])
buf1 = req.read()
f.write(buf1)
i+=1
if __name__ == '__main__':
main()
另外有需要云服務(wù)器可以了解下創(chuàng)新互聯(lián)scvps.cn,海內(nèi)外云服務(wù)器15元起步,三天無理由+7*72小時(shí)售后在線,公司持有idc許可證,提供“云服務(wù)器、裸金屬服務(wù)器、高防服務(wù)器、香港服務(wù)器、美國服務(wù)器、虛擬主機(jī)、免備案服務(wù)器”等云主機(jī)租用服務(wù)以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務(wù)可用性高、性價(jià)比高”等特點(diǎn)與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應(yīng)用場景需求。
分享標(biāo)題:Python使用爬蟲爬取靜態(tài)網(wǎng)頁圖片的方法詳解-創(chuàng)新互聯(lián)
網(wǎng)頁鏈接:http://chinadenli.net/article42/eohhc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站建設(shè)、商城網(wǎng)站、小程序開發(fā)、微信公眾號(hào)、全網(wǎng)營銷推廣、python
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 淺談Layui的eleTree樹式選擇器使用方法-創(chuàng)新互聯(lián)
- 【cocos2dx進(jìn)階】開篇-創(chuàng)新互聯(lián)
- Python對(duì)XML解析的方法-創(chuàng)新互聯(lián)
- python內(nèi)置模塊~shutil-創(chuàng)新互聯(lián)
- html基本標(biāo)簽-創(chuàng)新互聯(lián)
- C之函數(shù)設(shè)計(jì)原則(四十二)-創(chuàng)新互聯(lián)
- Android使用viewpager實(shí)現(xiàn)自動(dòng)無限輪播圖-創(chuàng)新互聯(lián)

- 網(wǎng)站設(shè)計(jì)公司有哪些設(shè)計(jì)規(guī)范 2018-04-27
- 深圳網(wǎng)站設(shè)計(jì)公司 2014-05-03
- 亞洲地區(qū)的韓國和日本服務(wù)器有哪些不同 2017-02-15
- 無錫網(wǎng)站設(shè)計(jì)公司如何提升可用性? 2022-06-13
- 上海網(wǎng)站建設(shè)/上海網(wǎng)站設(shè)計(jì)公司了最關(guān)鍵的是什么? 2020-11-03
- 上海網(wǎng)站建設(shè)公司、上海網(wǎng)站設(shè)計(jì)公司網(wǎng)站建設(shè)的指導(dǎo)性意義 2020-11-07
- 網(wǎng)站設(shè)計(jì)公司:明亮配色的網(wǎng)站設(shè)計(jì)有哪些優(yōu)勢和劣勢? 2017-02-14
- 上海網(wǎng)站建設(shè)公司、上海網(wǎng)站設(shè)計(jì)公司網(wǎng)站建設(shè)好嗎 2020-11-07
- 網(wǎng)站設(shè)計(jì)公司:網(wǎng)站建設(shè)公司解析網(wǎng)站引流的秘訣 2017-02-14
- 上海網(wǎng)站建設(shè)公司、上海網(wǎng)站設(shè)計(jì)公司在小說網(wǎng)站中占據(jù)了多高的地位 2020-11-06
- 上海網(wǎng)站設(shè)計(jì)公司應(yīng)該怎樣去定位 2020-11-07
- 網(wǎng)站設(shè)計(jì)公司都有哪些設(shè)計(jì)規(guī)范 2021-09-19