6、MapReduce自定義分區(qū)實(shí)現(xiàn)-創(chuàng)新互聯(lián)
MapReduce自帶的分區(qū)器是HashPartitioner
原理:先對(duì)map輸出的key求hash值,再模上reduce task個(gè)數(shù),根據(jù)結(jié)果,決定此輸出kv對(duì),被匹配的reduce任務(wù)取走。
自定義分分區(qū)需要繼承Partitioner,復(fù)寫getpariton()方法
自定義分區(qū)類:
注意:map的輸出是<K,V>鍵值對(duì)
其中int partitionIndex = dict.get(text.toString()),partitionIndex是獲取K的值

附:被計(jì)算的的文本
Dear Dear Bear Bear River Car Dear Dear Bear Rive
Dear Dear Bear Bear River Car Dear Dear Bear Rive需要在main函數(shù)中設(shè)置,指定自定義分區(qū)類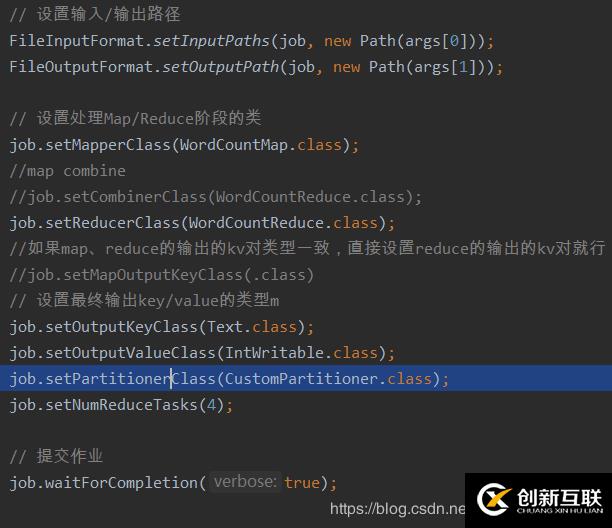
自定義分區(qū)類:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
public static HashMap<String, Integer> dict = new HashMap<String, Integer>();
//Text代表著map階段輸出的key,IntWritable代表著輸出的值
static{
dict.put("Dear", 0);
dict.put("Bear", 1);
dict.put("River", 2);
dict.put("Car", 3);
}
public int getPartition(Text text, IntWritable intWritable, int i) {
//
int partitionIndex = dict.get(text.toString());
return partitionIndex;
}
}注意:map的輸出結(jié)果是鍵值對(duì)<K,V>,int partitionIndex = dict.get(text.toString());中的partitionIndex是map輸出鍵值對(duì)中的鍵的值,也就是K的值。
Maper類:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
// 每個(gè)單詞出現(xiàn)1次,作為中間結(jié)果輸出
context.write(new Text(word), new IntWritable(1));
}
}
}Reducer類:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
// 每個(gè)單詞出現(xiàn)1次,作為中間結(jié)果輸出
context.write(new Text(word), new IntWritable(1));
}
}
}main函數(shù):
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMain {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
if (args.length != 2 || args == null) {
System.out.println("please input Path!");
System.exit(0);
}
Configuration configuration = new Configuration();
configuration.set("mapreduce.job.jar","/home/bruce/project/kkbhdp01/target/com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
Job job = Job.getInstance(configuration, WordCountMain.class.getSimpleName());
// 打jar包
job.setJarByClass(WordCountMain.class);
// 通過job設(shè)置輸入/輸出格式
//job.setInputFormatClass(TextInputFormat.class);
//job.setOutputFormatClass(TextOutputFormat.class);
// 設(shè)置輸入/輸出路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 設(shè)置處理Map/Reduce階段的類
job.setMapperClass(WordCountMap.class);
//map combine
//job.setCombinerClass(WordCountReduce.class);
job.setReducerClass(WordCountReduce.class);
//如果map、reduce的輸出的kv對(duì)類型一致,直接設(shè)置reduce的輸出的kv對(duì)就行;如果不一樣,需要分別設(shè)置map, reduce的輸出的kv類型
//job.setMapOutputKeyClass(.class)
// 設(shè)置最終輸出key/value的類型m
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(CustomPartitioner.class);
job.setNumReduceTasks(4);
// 提交作業(yè)
job.waitForCompletion(true);
}
}main函數(shù)參數(shù)設(shè)置: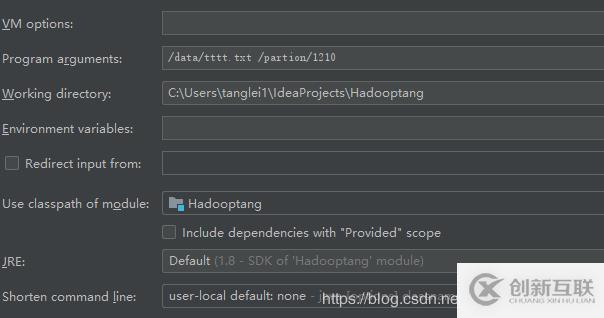
分享題目:6、MapReduce自定義分區(qū)實(shí)現(xiàn)-創(chuàng)新互聯(lián)
瀏覽地址:http://chinadenli.net/article40/gceeo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站導(dǎo)航、手機(jī)網(wǎng)站建設(shè)、標(biāo)簽優(yōu)化、品牌網(wǎng)站制作、微信公眾號(hào)、網(wǎng)站收錄
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- python腳本字符串變量強(qiáng)制不轉(zhuǎn)義win地址不轉(zhuǎn)-創(chuàng)新互聯(lián)
- 學(xué)習(xí)UI設(shè)計(jì)要懂哪些內(nèi)容?最新UI學(xué)習(xí)路線圖告訴你-創(chuàng)新互聯(lián)
- Androidstyle的繼承-創(chuàng)新互聯(lián)
- linux下實(shí)現(xiàn)mysql自動(dòng)備份的腳本-創(chuàng)新互聯(lián)
- ASP.NETWebAPI單元測(cè)試-WebAPI簡(jiǎn)單介紹-創(chuàng)新互聯(lián)
- centos7鏡像來創(chuàng)建一個(gè)容器-創(chuàng)新互聯(lián)
- maven-profile-創(chuàng)新互聯(lián)

- 為什么做網(wǎng)站制作可以給企業(yè)帶來效益? 2022-12-11
- 自己做網(wǎng)站有哪些原則 2022-10-30
- 深圳做網(wǎng)站流程 2021-11-04
- 第一次獨(dú)立做網(wǎng)站seo優(yōu)化時(shí)應(yīng)避免的誤區(qū) 2013-11-22
- 網(wǎng)站建設(shè)公司告訴你企業(yè)做網(wǎng)站有什么作用和好處 2022-04-19
- 做網(wǎng)站不同階段的責(zé)任有哪些 2023-02-21
- 做網(wǎng)站需要花多少錢 2016-08-05
- 上海做網(wǎng)站:什么是網(wǎng)站的正面目標(biāo)和負(fù)面目標(biāo)? 2016-09-05
- 企業(yè)做網(wǎng)站優(yōu)化需要用到那些輔助工具? 2022-12-22
- 新手做網(wǎng)站推廣常見的幾個(gè)難題總結(jié) 2022-09-12
- 怎么做網(wǎng)站建設(shè)-網(wǎng)站建設(shè)的三種形式 2016-11-09
- 做網(wǎng)站需要掌握哪些專業(yè)技術(shù)? 2016-08-28