Python如何爬取新聞資訊
這篇文章主要為大家展示了“Python如何爬取新聞資訊”,內(nèi)容簡(jiǎn)而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領(lǐng)大家一起研究并學(xué)習(xí)一下“Python如何爬取新聞資訊”這篇文章吧。
創(chuàng)新互聯(lián)建站公司2013年成立,先為瓊結(jié)等服務(wù)建站,瓊結(jié)等地企業(yè),進(jìn)行企業(yè)商務(wù)咨詢服務(wù)。為瓊結(jié)企業(yè)網(wǎng)站制作PC+手機(jī)+微官網(wǎng)三網(wǎng)同步一站式服務(wù)解決您的所有建站問(wèn)題。
前言
一個(gè)簡(jiǎn)單的Python資訊采集案例,列表頁(yè)到詳情頁(yè),到數(shù)據(jù)保存,保存為txt文檔,網(wǎng)站網(wǎng)頁(yè)結(jié)構(gòu)算是比較規(guī)整,簡(jiǎn)單清晰明了,資訊新聞內(nèi)容的采集和保存!
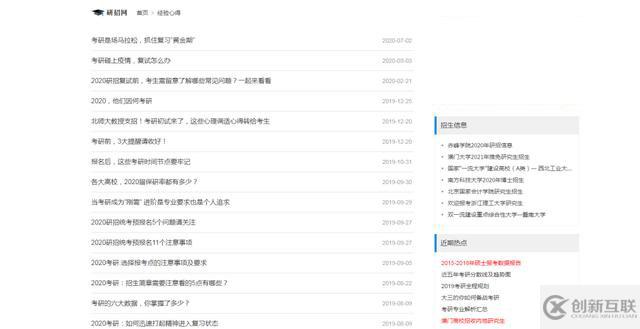
資料就放在群文件里等你來(lái)拿
應(yīng)用到的庫(kù)
requests,time,re,UserAgent,etree
import requests,time,re from fake_useragent import UserAgent from lxml import etree
列表頁(yè),鏈接xpath解析
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')詳情頁(yè)
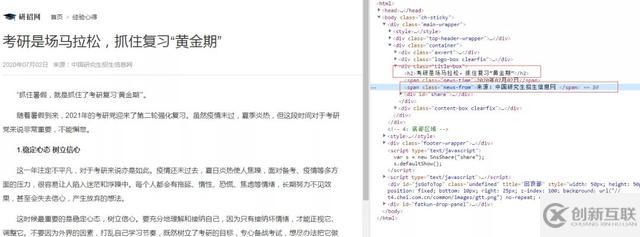
內(nèi)容xpath解析
h3=req.xpath('//div[@class="title-box"]/h3/text()')[0]
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')內(nèi)容格式化處理
detail='\n'.join(details)
標(biāo)題格式化處理,替換非法字符
pattern = r"[\/\\\:\*\?\"\<\>\|]" new_title = re.sub(pattern, "_", title) # 替換為下劃線
保存數(shù)據(jù),保存為txt文本
def save(self,h3, author, detail):
with open(f'{h3}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h3,'\n',detail,'\n',author))
print(f"保存{h3}.txt文本成功!")遍歷數(shù)據(jù)采集,yield處理
def get_tasks(self): data_list = self.parse_home_list(self.url) for item in data_list: yield item
程序運(yùn)行效果

附源碼參考:
#研招網(wǎng)考研資訊采集
#20200710 by微信:huguo00289
# -*- coding: UTF-8 -*-
import requests,time,re
from fake_useragent import UserAgent
from lxml import etree
class RandomHeaders(object):
ua=UserAgent()
@property
def random_headers(self):
return {
'User-Agent': self.ua.random,
}
class Spider(RandomHeaders):
def __init__(self,url):
self.url=url
def parse_home_list(self,url):
response=requests.get(url,headers=self.random_headers).content.decode('utf-8')
req=etree.HTML(response)
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')
print(href_list)
for href in href_list:
item = self.parse_detail(f'https://yz.chsi.com.cn{href}')
yield item
def parse_detail(self,url):
print(f">>正在爬取{url}")
try:
response = requests.get(url, headers=self.random_headers).content.decode('utf-8')
time.sleep(2)
except Exception as e:
print(e.args)
self.parse_detail(url)
else:
req = etree.HTML(response)
try:
h3=req.xpath('//div[@class="title-box"]/h3/text()')[0]
h3=self.validate_title(h3)
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')
detail='\n'.join(details)
print(h3, author, detail)
self.save(h3, author, detail)
return h3, author, detail
except IndexError:
print(">>>采集出錯(cuò)需延時(shí),5s后重試..")
time.sleep(5)
self.parse_detail(url)
@staticmethod
def validate_title(title):
pattern = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, "_", title) # 替換為下劃線
return new_title
def save(self,h3, author, detail):
with open(f'{h3}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h3,'\n',detail,'\n',author))
print(f"保存{h3}.txt文本成功!")
def get_tasks(self):
data_list = self.parse_home_list(self.url)
for item in data_list:
yield item
if __name__=="__main__":
url="https://yz.chsi.com.cn/kyzx/jyxd/"
spider=Spider(url)
for data in spider.get_tasks():
print(data)以上是“Python如何爬取新聞資訊”這篇文章的所有內(nèi)容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內(nèi)容對(duì)大家有所幫助,如果還想學(xué)習(xí)更多知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道!
文章題目:Python如何爬取新聞資訊
文章位置:http://chinadenli.net/article4/jgjiie.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站改版、網(wǎng)站設(shè)計(jì)、響應(yīng)式網(wǎng)站、App開(kāi)發(fā)、定制開(kāi)發(fā)、品牌網(wǎng)站設(shè)計(jì)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 行業(yè)動(dòng)態(tài)網(wǎng)站色彩 2022-01-08
- 新聞動(dòng)態(tài)網(wǎng)頁(yè)布局設(shè)計(jì)的內(nèi)涵與追求-茂名網(wǎng)站建設(shè) 2016-08-31
- 日照網(wǎng)站制作關(guān)于靜態(tài)網(wǎng)站優(yōu)于動(dòng)態(tài)網(wǎng)站做seo優(yōu)化的正確解釋 2023-01-09
- 動(dòng)態(tài)網(wǎng)站跟靜態(tài)網(wǎng)站的區(qū)別? 2021-07-31
- 靜態(tài)路徑和動(dòng)態(tài)路徑有何區(qū)別,如何進(jìn)行SEO優(yōu)化? 2016-10-29
- 武漢網(wǎng)頁(yè)制作中如何更好地把握客戶動(dòng)態(tài)需求? 2015-06-26
- 從外觀上來(lái)說(shuō)動(dòng)態(tài)網(wǎng)站與靜態(tài)網(wǎng)站的區(qū)別 2020-07-07
- 靜態(tài)網(wǎng)站跟動(dòng)態(tài)網(wǎng)站在制作上有哪些區(qū)別呢 2016-11-12
- 行業(yè)動(dòng)態(tài)網(wǎng)站后臺(tái)管理系統(tǒng)的安全隱患 2021-08-23
- 企業(yè)站使用靜態(tài)網(wǎng)頁(yè)還是使用動(dòng)態(tài)網(wǎng)頁(yè)分析 2016-08-08
- 互聯(lián)網(wǎng)+醫(yī)療的最新行業(yè)動(dòng)態(tài) 2013-07-22
- 網(wǎng)站建設(shè)基礎(chǔ)知識(shí)之靜態(tài)和動(dòng)態(tài)網(wǎng)站(二) 2016-09-16