python如何讀取各種文件數(shù)據(jù)-創(chuàng)新互聯(lián)
這篇文章主要介紹了python如何讀取各種文件數(shù)據(jù),具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。

python有哪些常用庫
python常用的庫:1.requesuts;2.scrapy;3.pillow;4.twisted;5.numpy;6.matplotlib;7.pygama;8.ipyhton等。
python讀取.txt(.log)文件 、.xml 文件 、excel文件數(shù)據(jù),并將數(shù)據(jù)類型轉(zhuǎn)換為需要的類型,添加到list中詳解
1.讀取文本文件數(shù)據(jù)(.txt結(jié)尾的文件)或日志文件(.log結(jié)尾的文件)
以下是文件中的內(nèi)容,文件名為data.txt(與data.log內(nèi)容相同),且處理方式相同,調(diào)用時改個名稱就可以了:
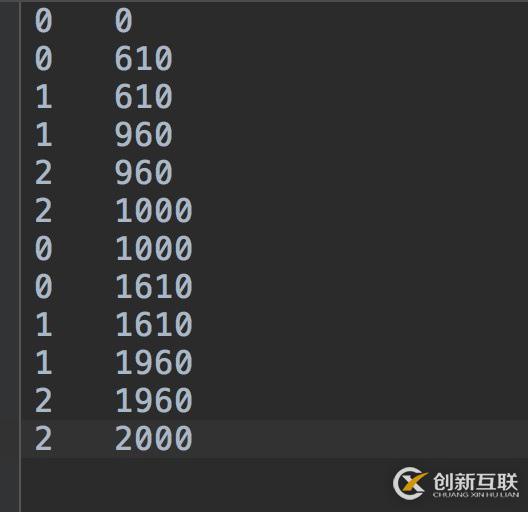
以下是python實現(xiàn)代碼:
# -*- coding:gb2312 -*- import json def read_txt_high(filename): with open(filename, 'r') as file_to_read: list0 = [] #文件中的第一列數(shù)據(jù) list1 = [] #文件中的第二列數(shù)據(jù) while True: lines = file_to_read.readline() # 整行讀取數(shù)據(jù) if not lines: break item = [i for i in lines.split()] data0 = json.loads(item[0])#每行第一個值 data1 = json.loads(item[1])#每行第二個值 list0.append(data0) list1.append(data1) return list0,list1
list0與list1分別為文檔中的第一列數(shù)據(jù)與第二列數(shù)據(jù)。運行若是文本文件(.txt結(jié)尾的文件)輸入以下:
aa,bb = read_txt_high('data.txt')
print aa
print bb若是日志文件(.log結(jié)尾的文件),輸入以下:
aa,bb = read_txt_high('data.log')
print aa
print bb運行結(jié)果如下:

2.讀取.xml結(jié)尾的文件
XML文件的名稱為abc.xml, 內(nèi)容如下圖所示:
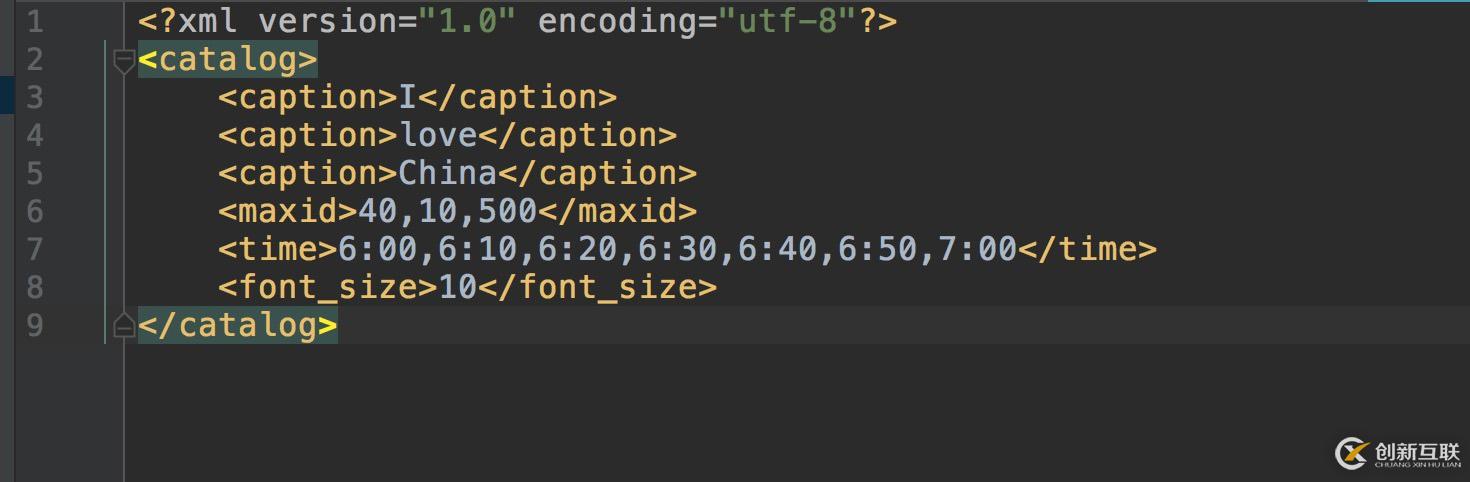
以下是實現(xiàn)代碼:
# -*- coding:gb2312 -*-
# coding = utf-8
from pylab import *
import xml.dom.minidom
def read_xml():
dom = xml.dom.minidom.parse('abc.xml')#打開xml文檔
cc=dom.getElementsByTagName('caption')
list_str = [] #字符串
for item in cc:
list_str.append(str(item.firstChild.data))
bb = dom.getElementsByTagName('maxid')
list_fig = []
for item in bb:
list_fig.append(item.firstChild.data)
su = list_fig[0].encode("gbk")
list_fig2 = su.split(",")
list_fig_num = []
for i in list_fig2:
list_fig_num.append(int(i))
ee = dom.getElementsByTagName('time')
list_tim = []
for item in ee:
list_tim.append(item.firstChild.data)
sg = list_tim[0].encode("gbk")
list_time = sg.split(",")
gg = dom.getElementsByTagName('font_size')
g1 = []
for item in gg:
g1.append(item.firstChild.data)
su = g1[0].encode("gbk")
return list_str,list_fig_num,list_time,su調(diào)用此函數(shù)如下所示:
a,b,c,d = read_xml() print a print b print c print d
輸出結(jié)果如下圖所示:

3.讀取excel文件數(shù)據(jù),并將其存入list列表中
excel表格中的數(shù)據(jù)如下圖所示,表格命名為data.xlsx:
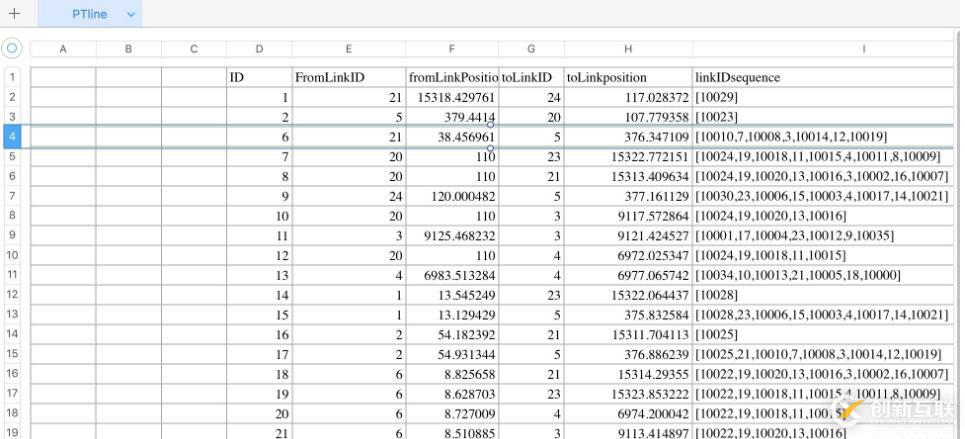
首先將ID列中的數(shù)據(jù)保存到列表list_col中,實現(xiàn)代碼如下所示:
# -*- coding: utf-8 -*-
import xlrd
import json
def read_ex_stop_PTline():
# 打開文件
workbook = xlrd.open_workbook(r'data.xlsx')
sheet = workbook.sheet_by_name('PTline')
list_col = []
for i in range(1,sheet.nrows):
c = sheet.cell(i,3).value
list_col.append(int(c))
print list_col調(diào)用此函數(shù),輸出結(jié)果如下:

以下將linkIDsequence列數(shù)據(jù)存放到一個list中,即list_ele中,實現(xiàn)代碼如下:
# -*- coding: utf-8 -*-
import xlrd
import json
def read_ex_stop_PTline():
# 打開文件
workbook = xlrd.open_workbook(r'data.xlsx')
sheet = workbook.sheet_by_name('PTline')
list_ele = [] #第八列的所有數(shù)據(jù)放入一個list中
for i in range(1,sheet.nrows):
c = sheet.cell(i, 8).value
cc = json.loads(c) #第八列的每個單元格處理為一個list
for j in range(len(cc)):
list_ele.append(cc[j])
print list_ele調(diào)用函數(shù)read_ex_stop_PTline,輸出結(jié)果如下圖所示:

感謝你能夠認真閱讀完這篇文章,希望小編分享的“python如何讀取各種文件數(shù)據(jù)”這篇文章對大家有幫助,同時也希望大家多多支持創(chuàng)新互聯(lián)成都網(wǎng)站設計公司,關注創(chuàng)新互聯(lián)成都網(wǎng)站設計公司行業(yè)資訊頻道,更多相關知識等著你來學習!
另外有需要云服務器可以了解下創(chuàng)新互聯(lián)scvps.cn,海內(nèi)外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、網(wǎng)站設計器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務可用性高、性價比高”等特點與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
當前標題:python如何讀取各種文件數(shù)據(jù)-創(chuàng)新互聯(lián)
文章起源:http://chinadenli.net/article38/gcisp.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站設計公司、網(wǎng)站導航、面包屑導航、App設計、網(wǎng)站內(nèi)鏈、網(wǎng)站營銷
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- Linux系統(tǒng)下centos7怎么搭建ElasticSearch中間件-創(chuàng)新互聯(lián)
- 數(shù)據(jù)結(jié)構-循環(huán)順序隊列的基本操作-創(chuàng)新互聯(lián)
- 云主機的用途-創(chuàng)新互聯(lián)
- 怎么用python抓取百度貼吧內(nèi)容-創(chuàng)新互聯(lián)
- mysql多實例啟動簡要備忘-創(chuàng)新互聯(lián)
- 安裝lamp之一鍵安裝php-創(chuàng)新互聯(lián)
- 怎么在微信小程序中實現(xiàn)一個圖片翻轉(zhuǎn)效果-創(chuàng)新互聯(lián)

- 站長建站選擇云主機好還是虛擬主機好 2021-09-24
- 云服務器與虛擬主機對比優(yōu)勢分析 2021-02-05
- 為什么有些獨立IP的云主機會比共享虛擬主機的速度慢? 2021-02-14
- 新手站長如何挑選虛擬主機服務器?記住這四點不入坑! 2022-06-04
- 獨立ip虛擬主機哪里購買好 2022-07-17
- 虛擬主機銷售系統(tǒng)有哪些?虛擬主機有什么優(yōu)勢? 2022-10-05
- 網(wǎng)站制作中,如何選擇匹配度高的虛擬主機? 2013-05-10
- 網(wǎng)站優(yōu)化之基礎篇:虛擬主機選擇注意事項 2021-09-03
- 虛擬主機怎么鑒別是不是被掛馬? 2022-10-08
- 虛擬主機選擇哪種操作系統(tǒng)比較好? 2022-10-07
- 虛擬主機有什么指標?怎么選虛擬主機? 2021-02-01
- 國內(nèi)外虛擬主機對比:站長該如何選擇 2021-10-27