怎么分析sparkrdd的另類解讀
這篇文章將為大家詳細(xì)講解有關(guān)怎么分析spark rdd的另類解讀,文章內(nèi)容質(zhì)量較高,因此小編分享給大家做個(gè)參考,希望大家閱讀完這篇文章后對相關(guān)知識有一定的了解。
在成都網(wǎng)站設(shè)計(jì)、成都網(wǎng)站建設(shè)過程中,需要針對客戶的行業(yè)特點(diǎn)、產(chǎn)品特性、目標(biāo)受眾和市場情況進(jìn)行定位分析,以確定網(wǎng)站的風(fēng)格、色彩、版式、交互等方面的設(shè)計(jì)方向。創(chuàng)新互聯(lián)還需要根據(jù)客戶的需求進(jìn)行功能模塊的開發(fā)和設(shè)計(jì),包括內(nèi)容管理、前臺展示、用戶權(quán)限管理、數(shù)據(jù)統(tǒng)計(jì)和安全保護(hù)等功能。
1 Spark的RDD
提到Spark必說RDD,RDD是Spark的核心,如果沒有對RDD的深入理解,是很難寫好spark程序的,但是網(wǎng)上對RDD的解釋一般都屬于人云亦云、鸚鵡學(xué)舌,基本都沒有加入自己的理解。下面基于Spark原創(chuàng)作者的論文,對Spark的核心概念RDD做一個(gè)初步的探討。
1.1 Resilient
中文解釋是“能復(fù)原的;彈回的,有彈性的;”,在我們的生活中,一個(gè)東西有彈性,就說明這個(gè)東西不易損壞,例如皮球、輪胎,而蘋果公司在給蘋果手機(jī)申請的一個(gè)專利,正是在手機(jī)的四個(gè)角加入了類似橡皮筋材質(zhì)的東西,來增加手機(jī)跌落時(shí)的抗摔性。Spark的核心數(shù)據(jù)結(jié)構(gòu)有彈性,能復(fù)原,說明spark在設(shè)計(jì)之初就考慮把spark應(yīng)用在大規(guī)模的分布式集群中,因?yàn)檫@種大規(guī)模集群,任何一臺服務(wù)器是隨時(shí)都可能出故障的,如果正在進(jìn)行計(jì)算的子任務(wù)(Task)所在的服務(wù)器出故障,那么這個(gè)子任務(wù)自然在這臺服務(wù)器無法繼續(xù)執(zhí)行,這時(shí)RDD所具有的“彈性”就派上了用場,它可以使這個(gè)失敗的子任務(wù)在集群內(nèi)進(jìn)行遷移,從而保證整體任務(wù)(Job)對故障機(jī)器的平滑過渡。可能有些同學(xué)有疑問了,難道還有系統(tǒng)不具有彈性,是硬邦邦的?還真有,比如很多的即系查詢系統(tǒng),例如presto或者impala,因?yàn)樵谄渖线\(yùn)行的查詢,都是秒級的時(shí)延,所以如果子任務(wù)失敗,直接把查詢重跑一遍即可。而spark處理的任務(wù),可能時(shí)常要運(yùn)行分鐘級甚至小時(shí)級別,那么整個(gè)任務(wù)完全重跑的代價(jià)非常大,而某些task重跑的代價(jià)就比較小了,所以spark的數(shù)據(jù)結(jié)構(gòu)一定要有“彈性”,能自動容錯(cuò),保證任務(wù)只跑一遍。
1.2 Distributed
這個(gè)英文單詞的中文意思不用多解釋了,就是指的“分布式”。那么到底spark的數(shù)據(jù)結(jié)構(gòu)怎么個(gè)分布式法呢?這就涉及到了spark中分區(qū)(partition)的概念,也就是數(shù)據(jù)的切分規(guī)則,根據(jù)一些特定的規(guī)則切分后的數(shù)據(jù)子集,就可以在獨(dú)立的task中進(jìn)行處理,而這些task又是分散在集群多個(gè)服務(wù)器上并行的同時(shí)的執(zhí)行,這就是spark中Distributed的含義。spark源碼中RDD是個(gè)表示數(shù)據(jù)的基類,在這個(gè)基類之上衍生了很多的子RDD,不同的子RDD具有不同的功能,但是他們都要具備的能力就是能夠被切分(partition),比如從HDFS讀取數(shù)據(jù),那么會有hadoopRDD,這個(gè)hadoopRDD的切分規(guī)則就是如果一個(gè)HDFS文件可按照block(64M或者128M)進(jìn)行切分,例如txt格式,那么一個(gè)Block一個(gè)partition,spark會為這個(gè)Block生成一個(gè)task去處理這個(gè)Block的數(shù)據(jù),而如果HDFS上的文件不可切分,比如壓縮的zip或者gzip格式,那么一個(gè)文件對應(yīng)一個(gè)partition;如果數(shù)據(jù)在入庫時(shí)是隨機(jī)的,但是在處理時(shí)又需要根據(jù)數(shù)據(jù)的key進(jìn)行分組(group),那么就需要根據(jù)這個(gè)數(shù)據(jù)源的key對數(shù)據(jù)在集群中進(jìn)行分發(fā)(shuffle),把相同key的數(shù)據(jù)“歸類”到一起,如果把所有key放到同一個(gè)partition里,那么就只能有一個(gè)task來進(jìn)行歸類處理,性能會很差,所以這個(gè)過程的并行化,就是靠把key進(jìn)行切分,不同的key在不同的partition中被處理,來實(shí)現(xiàn)的歸類(group)過程并行化。
1.3 Datasets
看到這個(gè)詞,很多人會錯(cuò)誤的以為RDD是spark的數(shù)據(jù)存儲結(jié)構(gòu),其實(shí)并非如此,RDD中的Datasets并非真正的“集合”,更不是java中的collection,而是表示spark中數(shù)據(jù)處理的邏輯。怎么理解呢?這需要結(jié)合兩個(gè)概念來理解,第一是spark中RDD 的transform操作,另一個(gè)是spark中得pipeline。首先看RDD的transform,來看論文中的一個(gè)transform圖:
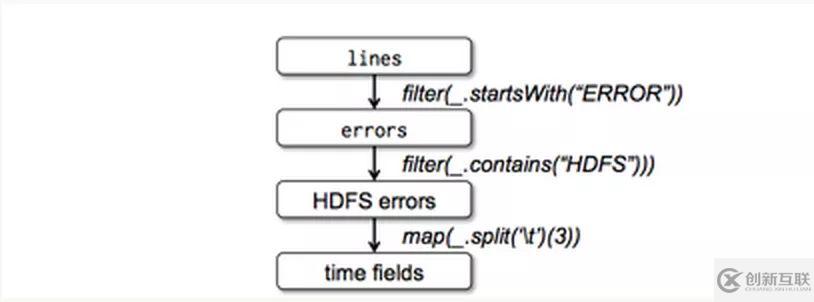 轉(zhuǎn)換
轉(zhuǎn)換
圖中每個(gè)長方形都是一個(gè)RDD,但是他們表示的數(shù)據(jù)結(jié)構(gòu)不同,注意,這里用的是”表示“,而不是”存儲“,例如lines這個(gè)RDD,就是最原始的文本行,而errors這個(gè)RDD,則只表示以”ERROR“開頭的文本行,而HDFSerrors這個(gè)RDD則表示包含了”HDFS“關(guān)鍵字的文本行。這就是一個(gè)RDD的”變形“過程。好了,我們回到上邊糾結(jié)的”表示“和”存儲“兩個(gè)字眼上,看看用不同的字眼表達(dá)會有什么不同的結(jié)果。如果我們用”存儲“,那么上一個(gè)RDD經(jīng)過transform后,需要存儲下來,等到全部處理完之后交給下一個(gè)處理邏輯(類似我們很久以前用迅雷下載電影,要先下載才能觀看,兩個(gè)過程是串行的)。那么問題來了,在一批數(shù)據(jù)達(dá)到之前,下一個(gè)處理邏輯必須要等待,這其實(shí)是沒有必要的。所以在上一個(gè)處理邏輯處理完一條數(shù)據(jù)后,如果立馬交給下一個(gè)處理邏輯,這樣就沒有等待的過程,整體系統(tǒng)性能會有極大的提升,而這正是用”表示“這個(gè)詞來表達(dá)的效果(類似后來的流媒體,不需要先下載電影,可以邊下載邊觀看),這也就是是spark中的pipeline(流水線)處理方式。
2 spark的lineage
RDD的三個(gè)單詞分析完了,球友們可能也有一個(gè)疑問,那就是對于pipeline的處理方式,感覺各個(gè)處理邏輯的數(shù)據(jù)都是”懸在空中“,沒有落磁盤那么踏實(shí)。確實(shí),如果是這種方式的話,spark怎么來保證這種”懸在空中“的流式數(shù)據(jù)在服務(wù)器故障后,能做到”可恢復(fù)“呢?這就引出了spark中另外一個(gè)重要的概念:lineage(血統(tǒng))。一個(gè)RDD的血統(tǒng),就是如上圖那樣的一系列處理邏輯,spark會為每個(gè)RDD記錄其血統(tǒng),借用范偉的經(jīng)典小品的橋段,spark知道每個(gè)RDD的子集是”怎么沒的“(變形變沒的)以及這個(gè)子集是 ”怎么來的“(變形變來的),那么當(dāng)數(shù)據(jù)子集丟失后,spark就會根據(jù)lineage,復(fù)原出這個(gè)丟失的數(shù)據(jù)子集,從而保證Datasets的彈性。
3 注意
1) 當(dāng)然如果RDD被cache和做了checkpoint就,可以理解為spark把一個(gè)RDD的數(shù)據(jù)“存儲了下來”,屬于后續(xù)優(yōu)化要講解的內(nèi)容。
2) RDD在transform時(shí),并非每處理一條就交給下一個(gè)RDD,而是使用小批量的方式傳遞,也屬于優(yōu)化的內(nèi)容。
關(guān)于怎么分析spark rdd的另類解讀就分享到這里了,希望以上內(nèi)容可以對大家有一定的幫助,可以學(xué)到更多知識。如果覺得文章不錯(cuò),可以把它分享出去讓更多的人看到。
當(dāng)前名稱:怎么分析sparkrdd的另類解讀
文章起源:http://chinadenli.net/article36/jggesg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站導(dǎo)航、用戶體驗(yàn)、面包屑導(dǎo)航、App開發(fā)、網(wǎng)站內(nèi)鏈、ChatGPT
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)

- 外貿(mào)建站中的哪些細(xì)節(jié)影響著網(wǎng)站流量? 2015-06-11
- 外貿(mào)建站和推廣如何做 2021-01-28
- 外貿(mào)建站需要哪些東西??? 2014-07-23
- 外貿(mào)建站選擇香港主機(jī)都有哪些優(yōu)勢? 2022-10-10
- 外貿(mào)建站前必看的四大技巧及優(yōu)化系統(tǒng) 2022-05-27
- 外貿(mào)建站系統(tǒng)如何選,要從不同角度去分析 2022-05-27
- 外貿(mào)建站過程中 這些點(diǎn)你必須了解 2015-10-03
- 海珠區(qū)外貿(mào)建站公司:專注歐美英文網(wǎng)頁設(shè)計(jì)制作! 2016-02-07
- 外貿(mào)建站過程中一些問題以及應(yīng)該注意什么 2015-07-07
- 外貿(mào)建站9大注意要點(diǎn) 2015-10-03
- 外貿(mào)建站需要哪些東西 2021-11-15
- 開發(fā)好的APP如何獲取用戶,告訴你了你也不一定領(lǐng)悟明白! 2022-06-02