CUDA編程筆記(2)-創(chuàng)新互聯(lián)
- 前言
- 1.CUDA的基本框架
- 直接使用c++編寫的數(shù)組相加的程序
- 使用cuda核函數(shù)的數(shù)組相加的程序
- 函數(shù)執(zhí)行空間標(biāo)識(shí)符
- 總結(jié)
- 參考:
前言
cuda程序的基本框架
1.CUDA的基本框架頭文件
常量定義(或者宏定義)
C++自定義函數(shù)和cuda核函數(shù)的聲明
int main()
{a分配主機(jī)與設(shè)備內(nèi)存
初始化主機(jī)中的數(shù)據(jù)
將某些數(shù)據(jù)從主機(jī)復(fù)制到設(shè)備
調(diào)用核函數(shù)在設(shè)備中進(jìn)行計(jì)算
將某些數(shù)據(jù)從設(shè)備復(fù)制到主機(jī)
釋放主機(jī)與設(shè)備內(nèi)存
}
c++自定義函數(shù)和cuda核函數(shù)的實(shí)現(xiàn)下面通過列子來體現(xiàn)這個(gè)框架
直接使用c++編寫的數(shù)組相加的程序這里直接使用c++編寫程序的習(xí)慣寫的數(shù)組相加的程序:
#include#include#includeconst double EP = 1.0e-15;
const double a = 1.23;
const double b = 2.34;
const double c = 3.57;
void add(const double *x,const double *y,double *z,const int N);
void check(const double *z,const int N);
int main()
{const int N = 100000000;
const int M = sizeof(double)*N;
// 分配內(nèi)存
double *x = (double *)malloc(M);
double *y = (double *)malloc(M);
double *z = (double *)malloc(M);
// double *x = new double[M];
// double *y = new double[M];
// double *z = new double[M];
// 初始化
for(int n=0;nx[n] = a;
y[n] = b;
}
// 數(shù)組求和
add(x,y,z,N);
check(z,N);
// 釋放內(nèi)存
free(x);
free(y);
free(z);
// delete []x;
// delete []y;
// delete []z;
return 0;
}
void add(const double *x,const double *y,double *z,const int N)
{for(int n=0;nz[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{bool has_error = false;
for(int n=0;nif(fabs(z[n]-c)>EP)
{has_error = true;
}
}
printf("%s\n",has_error?"HAS_ERROR":"NO_ERROR");
}
// 頭文件
#include#include#include// 常量定義
const double EP = 1.0e-15;
const double a = 1.23;
const double b = 2.34;
const double c = 3.57;
// c++自定義函數(shù)和cuda核函數(shù)的聲明
__global__ void add(const double *x,const double *y,double *z);
void check(const double *z,const int N);
int main()
{const int N = 100000000;
const int M = sizeof(double)*N;
// 分配主機(jī)內(nèi)存
double *h_x = (double *)malloc(M);
double *h_y = (double *)malloc(M);
double *h_z = (double *)malloc(M);
// double *h_x = new double[M];
// double *h_y = new double[M];
// double *h_z = new double[M];
// 分配設(shè)備內(nèi)存
double *d_x,*d_y,*d_z;
// printf("%p",d_x);
cudaMalloc((void **)&d_x,M);
cudaMalloc((void **)&d_y,M);
cudaMalloc((void **)&d_z,M);
// 初始化主機(jī)上的數(shù)據(jù)
for(int n=0;nh_x[n] = a;
h_y[n] = b;
}
// 將某些數(shù)據(jù)從主機(jī)復(fù)制到設(shè)備上
cudaMemcpy(d_x,h_x,M,cudaMemcpyHostToDevice);
cudaMemcpy(d_y,h_y,M,cudaMemcpyHostToDevice);
// 調(diào)用核函數(shù)在設(shè)備中進(jìn)行計(jì)算,數(shù)組求和
const int block_size = 128; // 不同型號(hào)的GPU有線程限制,開普勒到圖靈大為1024
const int gride_size = N/block_size;
add<<>>(d_x,d_y,d_z);
// 將某些數(shù)據(jù)從設(shè)備復(fù)制到主機(jī)上,這個(gè)數(shù)據(jù)傳輸函數(shù)隱式的起到了同步主機(jī)與設(shè)備的作用,所以后面用不用cudaDeviceSynchronize都可以
cudaMemcpy(h_z,d_z,M,cudaMemcpyDeviceToHost);
check(h_z,N);
// 釋放內(nèi)存
free(h_x);
free(h_y);
free(h_z);
// delete []h_x;
// delete []h_y;
// delete []h_z;
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}
__global__ void add(const double *x,const double *y,double *z)
{// 單指令-多線程,注意核函數(shù)中數(shù)據(jù)與線程的對(duì)應(yīng)關(guān)系
const int n = blockDim.x * blockIdx.x + threadIdx.x;
z[n] = x[n] + y[n];
}
void check(const double *z, const int N)
{bool has_error = false;
for(int n=0;nif(fabs(z[n]-c)>EP)
{has_error = true;
}
}
printf("%s\n",has_error?"HAS_ERROR":"NO_ERROR");
} // 單指令-多線程,注意核函數(shù)中數(shù)據(jù)與線程的對(duì)應(yīng)關(guān)系
const int n = blockDim.x * blockIdx.x + threadIdx.x;
blockDim指的是每個(gè)線程塊的線程總固定大小;
blockIdx指的是線程塊的索引;
threadIdx指的是線程的索引;
所以具體的一維線程索引會(huì)等于上面代碼式子所計(jì)算的索引核函數(shù)中數(shù)據(jù)與線程的對(duì)應(yīng)關(guān)系時(shí),注意到保存相應(yīng)數(shù)據(jù)類型的內(nèi)存大小N是自己定義的,所以就存在一個(gè)問題,如果gride_size = N/block_size不是剛好整數(shù)倍時(shí),就有可能引發(fā)錯(cuò)誤(越界)。所以,盡可能讓定義的線程個(gè)數(shù)多于元素個(gè)數(shù),然后通過條件語句來規(guī)避不需要的線程操作。可以寫成
int gride_size = (N%block_size==0?(N/block_size):(N/block_size + 1));
// 簡化成
int gride_size = (N-1) / block_size + 1; //or
int gride_size = (N+block_size-1) / block_size;同時(shí),在核函數(shù)里使用if條件語句規(guī)避不需要的線程操作:
// 參數(shù)傳入了 N
void __global__ add(const double *x, const double *y, double *z, const int N)
{const int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n< N)
{z[n] = x[n] + y[n];
}
}編譯的時(shí)候,用nvcc編譯會(huì)將設(shè)備代碼編譯為PTX(parallel thread execution)偽匯編代碼,再將偽匯編代碼編譯成二進(jìn)制的cubin代碼。在編譯為PTX代碼時(shí),需要指定GPU架構(gòu)的計(jì)算能力。默認(rèn)是2.0,可以自己看看自己GPU的算力,用nvcc編譯時(shí),加上-arch=sm_XY語句。如:
nvcc -g -arch=sm_75 xxx.cu -o xxx // GeForce RTX2080是7.5的通過結(jié)合上面的基本框架流程和未使用cuda核函數(shù)的c++程序進(jìn)行比較:
- (1)使用cuda核函數(shù)的程序,要使用cudaMalloc分配設(shè)備內(nèi)存并將數(shù)據(jù)復(fù)制到設(shè)備內(nèi)存中。同樣和c++分配內(nèi)存空間一樣,malloc與free要配套,cudaMalloc和cudaFree配套。c++中的另一種動(dòng)態(tài)分配內(nèi)存的new和delete可以替換malloc與free.
- (2)主機(jī)與設(shè)備間的數(shù)據(jù)傳遞使用cudaMemcpy,將主機(jī)(或設(shè)備)中的數(shù)據(jù)復(fù)制到設(shè)備(或主機(jī))中的內(nèi)存地址中。
- (3)注意核函數(shù)中數(shù)據(jù)與線程的對(duì)應(yīng)關(guān)系,單指令-多線程的操作需要注意對(duì)應(yīng)操作關(guān)系。
上面的cuda運(yùn)行的api可以在官方文檔查看使用說明:
https://docs.nvidia.com/cuda/cuda-runtime-api
如cudaMalloc,直接在搜索框里搜索,然后點(diǎn)進(jìn)去查看說明: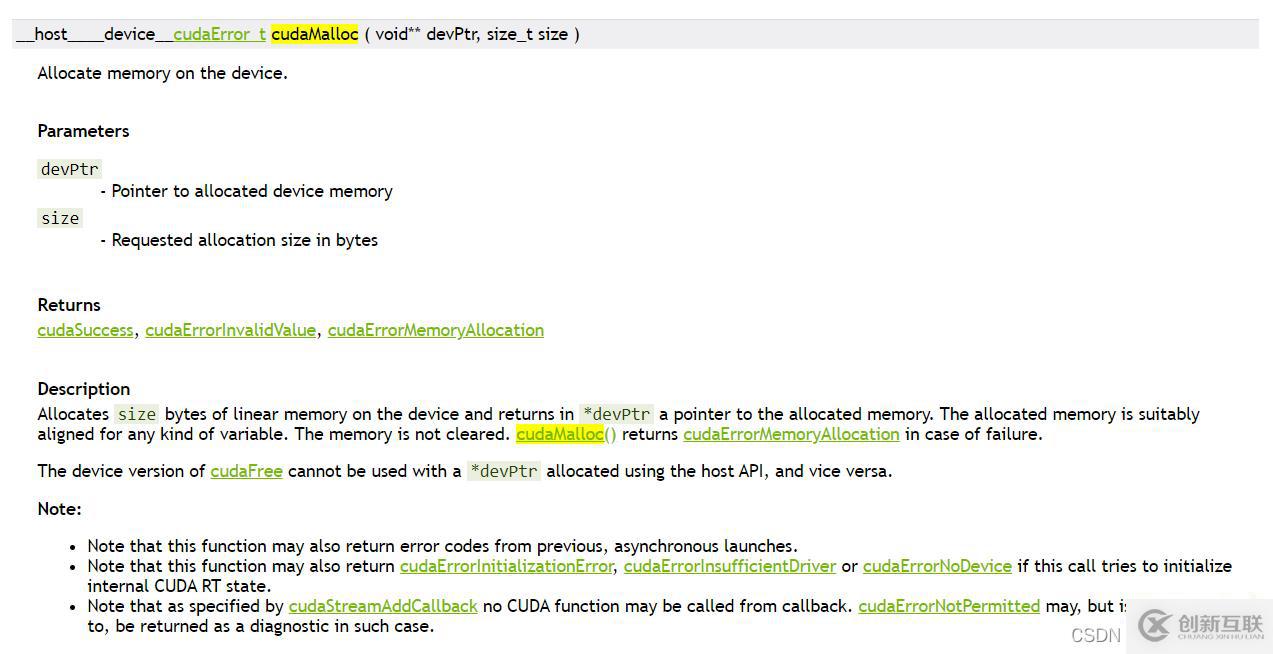
這里關(guān)注下返回值和輸入?yún)?shù):返回值是一個(gè)cudaError_t類型的信息,表示是否成功運(yùn)行此api,對(duì)于后面的程序檢查有用,輸入?yún)?shù)void **devPtr,因?yàn)榉祷刂狄呀?jīng)使用了,所以輸入?yún)?shù)使用一個(gè)雙重指針,指向指針的指針來指向數(shù)據(jù)原地址。
在cuda程序中,可以使用標(biāo)識(shí)符確定一個(gè)函數(shù)在哪里被調(diào)用和執(zhí)行。
(1)用__global__修飾的函數(shù)稱為核函數(shù)。一般由主機(jī)調(diào)用,在設(shè)備中執(zhí)行。動(dòng)態(tài)并行時(shí),也可以在核函數(shù)中互相調(diào)用。
(2)用__device__修飾的函數(shù)稱為設(shè)備函數(shù),只能被核函數(shù)或其他設(shè)備函數(shù)調(diào)用,在設(shè)備中執(zhí)行。
(3)用__host__修飾的函數(shù)就是主機(jī)端的普通C++函數(shù),在主機(jī)中調(diào)用,在主機(jī)中執(zhí)行。也可以省略,之所以提供這個(gè)修飾符,主要是有時(shí)可以用__host__和__device__同時(shí)修飾一個(gè)函數(shù),這樣可以避免代碼的冗余。
(4)可以使用修飾符__noinline__或者_(dá)_forceinline__建議一個(gè)設(shè)備函數(shù)為非內(nèi)聯(lián)函數(shù)或內(nèi)聯(lián)函數(shù)。
注意:
1.不能同時(shí)使用__global__和__device__修飾同一個(gè)函數(shù)。
2.不能同時(shí)使用__global__和__host__修飾同一個(gè)函數(shù)。
熟悉cuda程序的基本框架。
參考:如博客內(nèi)容有侵權(quán)行為,可及時(shí)聯(lián)系刪除!
CUDA 編程:基礎(chǔ)與實(shí)踐
https://docs.nvidia.com/cuda/
https://docs.nvidia.com/cuda/cuda-runtime-api
https://github.com/brucefan1983/CUDA-Programming
你是否還在尋找穩(wěn)定的海外服務(wù)器提供商?創(chuàng)新互聯(lián)www.cdcxhl.cn海外機(jī)房具備T級(jí)流量清洗系統(tǒng)配攻擊溯源,準(zhǔn)確流量調(diào)度確保服務(wù)器高可用性,企業(yè)級(jí)服務(wù)器適合批量采購,新人活動(dòng)首月15元起,快前往官網(wǎng)查看詳情吧
當(dāng)前名稱:CUDA編程筆記(2)-創(chuàng)新互聯(lián)
路徑分享:http://chinadenli.net/article36/cdodpg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供外貿(mào)網(wǎng)站建設(shè)、標(biāo)簽優(yōu)化、網(wǎng)站設(shè)計(jì)公司、手機(jī)網(wǎng)站建設(shè)、全網(wǎng)營銷推廣、網(wǎng)站改版
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 網(wǎng)站內(nèi)部鏈接建設(shè)的示例分析-創(chuàng)新互聯(lián)
- VMware創(chuàng)建虛擬機(jī)教程詳解及問題解決-創(chuàng)新互聯(lián)
- Unity3D腳印7——物理-創(chuàng)新互聯(lián)
- linux磁盤配額大小怎么設(shè)置-創(chuàng)新互聯(lián)
- syslog日志學(xué)習(xí)筆記-創(chuàng)新互聯(lián)
- Centos7安裝默認(rèn)mariadb5.5-創(chuàng)新互聯(lián)
- C++第二講——Demon和Angela的魔法之旅-創(chuàng)新互聯(lián)

- 品牌網(wǎng)站制作常見的布局方式 2022-03-22
- 為什么高端品牌網(wǎng)站制作公司越來越少了 2016-11-12
- 品牌網(wǎng)站制作為什么只能選擇網(wǎng)站定制 2021-10-04
- 集團(tuán)型網(wǎng)站建設(shè)品牌網(wǎng)站制作設(shè)計(jì) 2020-12-03
- 企業(yè)官方品牌網(wǎng)站制作需要遵循的三大原則 2023-03-02
- 湛江品牌網(wǎng)站制作:做好品牌網(wǎng)站制作方案有哪些要點(diǎn)? 2021-12-23
- 品牌網(wǎng)站制作之搜索引擎營銷 2021-11-17
- 中小企業(yè)品牌網(wǎng)站制作與塑造 2021-12-06
- 深圳品牌網(wǎng)站制作營銷重點(diǎn) 2021-09-28
- 企業(yè)品牌網(wǎng)站制作要注重哪些問題? 2023-04-18
- 品牌網(wǎng)站制作好方法好步驟? 2021-06-03
- 高端品牌網(wǎng)站制作策劃方案 2021-10-09