sklearn特征有哪些
這篇文章主要講解了“sklearn特征有哪些”,文中的講解內(nèi)容簡(jiǎn)單清晰,易于學(xué)習(xí)與理解,下面請(qǐng)大家跟著小編的思路慢慢深入,一起來(lái)研究和學(xué)習(xí)“sklearn特征有哪些”吧!
創(chuàng)新互聯(lián)是一家專業(yè)提供巴宜企業(yè)網(wǎng)站建設(shè),專注與做網(wǎng)站、成都網(wǎng)站設(shè)計(jì)、H5場(chǎng)景定制、小程序制作等業(yè)務(wù)。10年已為巴宜眾多企業(yè)、政府機(jī)構(gòu)等服務(wù)。創(chuàng)新互聯(lián)專業(yè)網(wǎng)絡(luò)公司優(yōu)惠進(jìn)行中。
問(wèn)題引出
當(dāng)我們拿到數(shù)據(jù)并對(duì)其進(jìn)行了數(shù)據(jù)預(yù)處理,但還不能直接拿去訓(xùn)練模型,還需要選擇有意義的特征(即特征選擇),這樣做有四個(gè)好處:
1、避免維度災(zāi)難
2、降低學(xué)習(xí)難度
3、減少過(guò)擬合
4、增強(qiáng)對(duì)特征和特征值之間的理解
常見(jiàn)的特征選擇有三種方法:
過(guò)濾法(Filter):先對(duì)數(shù)據(jù)集進(jìn)行特征選擇,然后再訓(xùn)練學(xué)習(xí)器,特征選擇過(guò)程與后續(xù)學(xué)習(xí)器無(wú)關(guān)。
包裝法(Wrapper):根據(jù)目標(biāo)函數(shù)(通常是預(yù)測(cè)效果評(píng)分),每次選擇若干特征,或者排除若干特征。
嵌入法(Embedding):先使用機(jī)器學(xué)習(xí)模型進(jìn)行訓(xùn)練,得到各個(gè)特征的權(quán)值系數(shù),根據(jù)系數(shù)從大到小選擇特征。
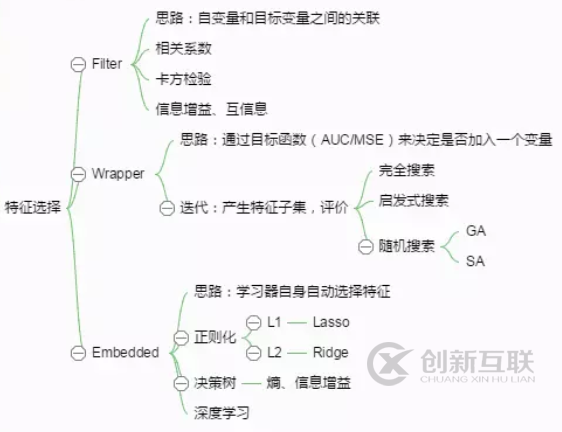
其中,過(guò)濾法是最簡(jiǎn)單,最易于運(yùn)行和最易于理解的。
過(guò)濾法核心思路就是考察自變量和目標(biāo)變量之間的關(guān)聯(lián)性、相關(guān)性,設(shè)定閾值,優(yōu)先選擇與目標(biāo)相關(guān)性高的特征。
主要方法:
1、分類問(wèn)題:卡方檢驗(yàn)(chi2),F(xiàn)檢驗(yàn)(f_classif), 互信息(mutual_info_classif)
2、回歸問(wèn)題:相關(guān)系數(shù)(f_regression), 信息系數(shù)(mutual_info_regression)
卡方檢驗(yàn)、F檢驗(yàn)、互信息、相關(guān)系數(shù)、信息系數(shù)
這些都是統(tǒng)計(jì)學(xué)領(lǐng)域的概念,在sklearn特征選擇中被使用,所以在解釋這些概念時(shí),我也重點(diǎn)參考了sklearn文檔。
卡方檢驗(yàn)百科定義:
卡方檢驗(yàn)就是統(tǒng)計(jì)樣本的實(shí)際觀測(cè)值與理論推斷值之間的偏離程度,實(shí)際觀測(cè)值與理論推斷值之間的偏離程度就決定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若兩個(gè)值完全相等時(shí),卡方值就為0,表明理論值完全符合。
卡方值 計(jì)算公式
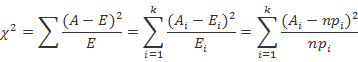
不要望公式興嘆,其實(shí)只需掌握到第一個(gè)等號(hào)后就行了:A為實(shí)際值,T為理論值。
F檢驗(yàn)
F檢驗(yàn)和方差分析(ANOVA)是一回事,主要用于兩個(gè)及兩個(gè)以上樣本均數(shù)差別的顯著性檢驗(yàn)。方差分析的基本原理是認(rèn)為不同處理組的均數(shù)間的差別基本來(lái)源有兩個(gè):(1) 實(shí)驗(yàn)條件,即不同的處理造成的差異,稱為組間差異。用變量在各組的均值與總均值之偏差平方和的總和表示,記作 ,組間自由度 。
(2) 隨機(jī)誤差,如測(cè)量誤差造成的差異或個(gè)體間的差異,稱為組內(nèi)差異,用變量在各組的均值與該組內(nèi)變量值之偏差平方和的總和表示, 記作 ,組內(nèi)自由度 。

利用f值可以判斷假設(shè)H0是否成立: 值越大,大到一定程度時(shí),就有理由拒絕零假設(shè),認(rèn)為不同總體下的均值存在顯著差異。所以我們可以根據(jù)樣本的某個(gè)特征 的f值來(lái)判斷特征 對(duì)預(yù)測(cè)類別的幫助, 值越大,預(yù)測(cè)能力也就越強(qiáng),相關(guān)性就越大,從而基于此可以進(jìn)行特征選擇。
互信息(mutual_info_classif/regression)
互信息是變量間相互依賴性的量度。不同于相關(guān)系數(shù),互信息并不局限于實(shí)值隨機(jī)變量,它更加一般且決定著聯(lián)合分布 p(X,Y) 和分解的邊緣分布的乘積 p(X)p(Y) 的相似程度。
兩個(gè)離散隨機(jī)變量 X 和 Y 的互信息可以定義為:
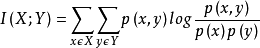
相關(guān)系數(shù)(f_regression)
相關(guān)系數(shù)是一種最簡(jiǎn)單的,能幫助理解特征和響應(yīng)變量之間關(guān)系的方法,該方法衡量的是變量之間的線性相關(guān)性,結(jié)果的取值區(qū)間為[-1,1],-1表示完全的負(fù)相關(guān),+1表示完全的正相關(guān),0表示沒(méi)有線性相關(guān)。
式中 是代表所有樣本的在i號(hào)特征上的取值的 維列向量,分子上其實(shí)兩個(gè) 維列向量的內(nèi)積,所以 是一個(gè)數(shù)值,其實(shí)就是樣本相關(guān)系數(shù)。
值越大,第i個(gè)特征和因變量y之間的相關(guān)性就越大,據(jù)此我們做特征選擇。
P值 (P-value)
P值,也就是常見(jiàn)到的 P-value。P 值是一種概率,指的是在 H0 假設(shè)為真的前提下,樣本結(jié)果出現(xiàn)的概率。如果 P-value 很小,則說(shuō)明在原假設(shè)為真的前提下,樣本結(jié)果出現(xiàn)的概率很小,甚至很極端,這就反過(guò)來(lái)說(shuō)明了原假設(shè)很大概率是錯(cuò)誤的。通常,會(huì)設(shè)置一個(gè)顯著性水平(significance level) 與 P-value 進(jìn)行比較,如果 P-value < ,則說(shuō)明在顯著性水平 下拒絕原假設(shè), 通常情況下設(shè)置為0.05。
sklearn特征選擇——過(guò)濾法
sklearn過(guò)濾法特征選擇方法
SelectBest 只保留 k 個(gè)最高分的特征;SelectPercentile 只保留用戶指定百分比的最高得分的特征;使用常見(jiàn)的單變量統(tǒng)計(jì)檢驗(yàn):假正率SelectFpr,錯(cuò)誤發(fā)現(xiàn)率selectFdr,或者總體錯(cuò)誤率SelectFwe;GenericUnivariateSelect 通過(guò)結(jié)構(gòu)化策略進(jìn)行特征選擇,通過(guò)超參數(shù)搜索估計(jì)器進(jìn)行特征選擇。
SelectKBest按照scores保留K個(gè)特征;
SelectPercentile按照scores保留指定百分比的特征;
SelectFpr、SelectFdr和SelectFwe對(duì)每個(gè)特征使用通用的單變量統(tǒng)計(jì)檢驗(yàn);
GenericUnivariateSelect允許使用可配置策略如超參數(shù)搜索估計(jì)器選擇最佳的單變量選擇策略。特征選擇指標(biāo)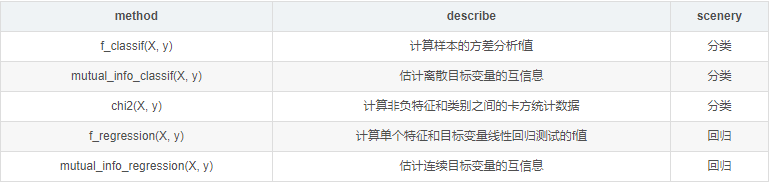 使用sklearn中SelectKBest函數(shù)進(jìn)行特征選擇,參數(shù)中的score_func選擇:分類:chi2----卡方檢驗(yàn)
使用sklearn中SelectKBest函數(shù)進(jìn)行特征選擇,參數(shù)中的score_func選擇:分類:chi2----卡方檢驗(yàn)
f_classif----方差分析,計(jì)算方差分析(ANOVA)的F值 (組間均方 / 組內(nèi)均方)
mutual_info_classif----互信息,互信息方法可以捕捉任何一種統(tǒng)計(jì)依賴,但是作為非參數(shù)方法,需要更多的樣本進(jìn)行準(zhǔn)確的估計(jì)
回歸:f_regression----相關(guān)系數(shù),計(jì)算每個(gè)變量與目標(biāo)變量的相關(guān)系數(shù),然后計(jì)算出F值和P值
mutual_info_regression----互信息,互信息度量 X 和 Y 共享的信息:它度量知道這兩個(gè)變量其中一個(gè),對(duì)另一個(gè)不確定度減少的程度。
sklearn過(guò)濾法特征選擇-示例
在sklearn中,可以使用chi2這個(gè)類來(lái)做卡方檢驗(yàn)得到所有特征的卡方值與顯著性水平P臨界值,我們可以給定卡方值閾值, 選擇卡方值較大的部分特征。代碼如下:
首先import包和實(shí)驗(yàn)數(shù)據(jù):
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.datasets import load_iris
#導(dǎo)入IRIS數(shù)據(jù)集
iris = load_iris()
使用卡方檢驗(yàn)來(lái)選擇特征
model1 = SelectKBest(chi2, k=2)#選擇k個(gè)最佳特征
model1.fit_transform(iris.data, iris.target)#iris.data是特征數(shù)據(jù),iris.target是標(biāo)簽數(shù)據(jù),該函數(shù)可以選擇出k個(gè)特征
結(jié)果輸出為:
array([[ 1.4, 0.2],
[ 1.4, 0.2],
[ 1.3, 0.2],
[ 1.5, 0.2],
[ 1.4, 0.2],
[ 1.7, 0.4],
[ 1.4, 0.3],
可以看出后使用卡方檢驗(yàn),選擇出了后兩個(gè)特征。如果我們還想查看卡方檢驗(yàn)的p值和得分,可以使用第3步。
查看p-values和scores
model1.scores_ #得分
得分輸出為:
array([ 10.81782088, 3.59449902, 116.16984746, 67.24482759])
可以看出后兩個(gè)特征得分最高,與我們第二步的結(jié)果一致;
model1.pvalues_ #p-values
p值輸出為:
array([ 4.47651499e-03, 1.65754167e-01, 5.94344354e-26, 2.50017968e-15])可以看出后兩個(gè)特征的p值最小,置信度也最高,與前面的結(jié)果一致。
感謝各位的閱讀,以上就是“sklearn特征有哪些”的內(nèi)容了,經(jīng)過(guò)本文的學(xué)習(xí)后,相信大家對(duì)sklearn特征有哪些這一問(wèn)題有了更深刻的體會(huì),具體使用情況還需要大家實(shí)踐驗(yàn)證。這里是創(chuàng)新互聯(lián),小編將為大家推送更多相關(guān)知識(shí)點(diǎn)的文章,歡迎關(guān)注!
本文題目:sklearn特征有哪些
鏈接URL:http://chinadenli.net/article34/ihpdse.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供小程序開(kāi)發(fā)、做網(wǎng)站、網(wǎng)站內(nèi)鏈、標(biāo)簽優(yōu)化、商城網(wǎng)站、虛擬主機(jī)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 深圳網(wǎng)站建設(shè)多少錢,網(wǎng)站關(guān)鍵詞優(yōu)化排名要如何穩(wěn)定? 2021-11-04
- 合肥做網(wǎng)站公司怎樣理解網(wǎng)站建設(shè)的關(guān)鍵字 2022-05-22
- 成都網(wǎng)站建設(shè)中溝通的必要性 2016-10-28
- 網(wǎng)站建設(shè)的幾大小竅門 2022-06-26
- 成都高端網(wǎng)站建設(shè)公司哪個(gè)好?如何選擇? 2022-08-21
- 新建設(shè)成都網(wǎng)站建設(shè)如何快速收錄 2022-08-10
- 吸引用戶注意力的3個(gè)網(wǎng)站建設(shè)設(shè)計(jì)技巧 2022-05-24
- 鄂爾多斯公司網(wǎng)站建設(shè):做網(wǎng)站時(shí)有哪些特別重要的點(diǎn)? 2021-10-15
- 成都網(wǎng)站制作和網(wǎng)站建設(shè)公司溝通網(wǎng)站建設(shè)的功能問(wèn)題? 2013-10-07
- 海淀網(wǎng)站建設(shè)公司手把手教你,怎樣做好網(wǎng)站定位? 2021-05-24
- 成都網(wǎng)站建設(shè)需要把提升用戶的體驗(yàn)放在第一 2022-05-29
- 企業(yè)網(wǎng)站建設(shè)比較常見(jiàn)的首頁(yè)布局方法 2022-05-15