詳解Python爬蟲如何實(shí)現(xiàn)百度翻譯功能過程-創(chuàng)新互聯(lián)
小編這次要給大家分享的是詳解Python爬蟲如何實(shí)現(xiàn)百度翻譯功能過程,文章內(nèi)容豐富,感興趣的小伙伴可以來了解一下,希望大家閱讀完這篇文章之后能夠有所收獲。

首先,需要簡(jiǎn)單的了解一下爬蟲,盡可能簡(jiǎn)單快速的上手,其次,需要了解的是百度的API的接口,搞定這個(gè)之后,最后,按照官方給出的demo,然后寫自己的一個(gè)小程序
打開瀏覽器 F12 打開百度翻譯網(wǎng)頁源代碼:
我們可以輕松的找到百度翻譯的請(qǐng)求接口為:http://fanyi.baidu.com/sug
然后我們可以從方法為POST的請(qǐng)求中找到參數(shù)為:kw:job(job是輸入翻譯的內(nèi)容)
下面是代碼部分:
from urllib import request,parse
import json
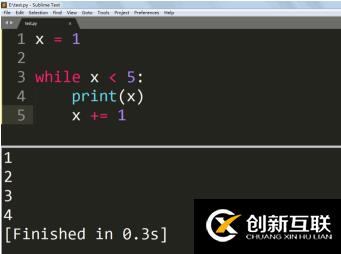
def translate(content):
url = "http://fanyi.baidu.com/sug"
data = parse.urlencode({"kw":content}) # 將參數(shù)進(jìn)行轉(zhuǎn)碼
headers = {
'User-Agent': 'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10'
}
req = request.Request(url,data=bytes(data,encoding="utf-8"),headers=headers)
r = request.urlopen(req)
# print(r.code) 查看返回的狀態(tài)碼
html = r.read().decode('utf-8')
# json格式化
html = json.loads(html)
# print(html)
for k in html["data"]:
print(k["k"],k["v"])
if __name__ == '__main__':
content = input("請(qǐng)輸入您要翻譯的內(nèi)容:")
translate(content)
當(dāng)前名稱:詳解Python爬蟲如何實(shí)現(xiàn)百度翻譯功能過程-創(chuàng)新互聯(lián)
本文鏈接:http://chinadenli.net/article32/sppsc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供定制開發(fā)、動(dòng)態(tài)網(wǎng)站、電子商務(wù)、網(wǎng)站導(dǎo)航、面包屑導(dǎo)航、用戶體驗(yàn)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 7月股權(quán)智庫&管理智庫內(nèi)容回顧-創(chuàng)新互聯(lián)
- 使用Docker快速搭建Zookeeper和kafka集群-創(chuàng)新互聯(lián)
- Linux中如何安裝Kafka分布式集群-創(chuàng)新互聯(lián)
- 我的朗科運(yùn)維第八課-創(chuàng)新互聯(lián)
- Mysql復(fù)制Replication的實(shí)現(xiàn)方法-創(chuàng)新互聯(lián)
- Apache網(wǎng)頁優(yōu)化---網(wǎng)頁壓縮與緩存-創(chuàng)新互聯(lián)
- 如何解決php中mysql亂碼-創(chuàng)新互聯(lián)

- 外貿(mào)網(wǎng)站建設(shè)需要了解的知識(shí) 2022-12-29
- 成都外貿(mào)網(wǎng)站建設(shè)應(yīng)該具備的功能有哪些? 2018-02-25
- 外貿(mào)網(wǎng)站建設(shè)時(shí)的注意事項(xiàng) 2022-11-14
- 如何進(jìn)行高端外貿(mào)網(wǎng)站建設(shè) 2016-11-10
- 談外貿(mào)網(wǎng)站建設(shè)用戶體驗(yàn)的幾個(gè)方面 2016-11-03
- 內(nèi)貿(mào)網(wǎng)站建設(shè)和外貿(mào)網(wǎng)站建設(shè)的不同之處有哪些? 2022-05-01
- 成都外貿(mào)網(wǎng)站建設(shè),推廣需要同步跟進(jìn) 2022-08-26
- 成都外貿(mào)網(wǎng)站建設(shè)關(guān)鍵詞如何獲得更好的排名 2022-05-30
- 聊聊外貿(mào)網(wǎng)站建設(shè)的關(guān)鍵之處是什么 2016-09-10
- 外貿(mào)網(wǎng)站建設(shè)需要做好哪些細(xì)節(jié)才能出彩? 2015-10-08
- 外貿(mào)網(wǎng)站建設(shè)這幾項(xiàng)必須注意 2021-01-05
- 使用WordPress做外貿(mào)網(wǎng)站建設(shè)的注意事項(xiàng) 2022-06-02