apachedruid有什么用
這篇文章主要介紹了apache druid有什么用,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
創(chuàng)新互聯(lián)主要從事網(wǎng)站設計、網(wǎng)站建設、網(wǎng)頁設計、企業(yè)做網(wǎng)站、公司建網(wǎng)站等業(yè)務。立足成都服務固陽,十年網(wǎng)站建設經(jīng)驗,價格優(yōu)惠、服務專業(yè),歡迎來電咨詢建站服務:028-86922220
什么是apache druid?
它是一個集時間序列數(shù)據(jù)庫、數(shù)據(jù)倉庫和全文檢索系統(tǒng)特點于一體的分析性數(shù)據(jù)平臺。
本文會為大家簡單了解一下druid的特性、使用場景、技術特點和架構等,這會有助于我們選擇數(shù)據(jù)存儲方案,深入了解druid存儲和時間序列存儲等。
概覽
一個現(xiàn)代化的云原生,流原生,分析型數(shù)據(jù)庫
Druid是為快速查詢和快速攝入數(shù)據(jù)的工作流而設計的。Druid強在有強大的UI,運行時可操作查詢,和高性能并發(fā)處理。Druid可以被視為一個滿足多樣化用戶場景的數(shù)據(jù)倉庫的開源替代品。
輕松與現(xiàn)有的數(shù)據(jù)管道集成
Druid可以從消息總線流式獲取數(shù)據(jù)(如Kafka,Amazon Kinesis),或從數(shù)據(jù)湖批量加載文件(如HDFS,Amazon S3和其他同類數(shù)據(jù)源)。
比傳統(tǒng)方案快100倍的性能
Druid對數(shù)據(jù)攝入和數(shù)據(jù)查詢的基準性能測試大大超過了傳統(tǒng)解決方案。
Druid的架構融合了數(shù)據(jù)倉庫,時間序列數(shù)據(jù)庫和檢索系統(tǒng)最好的特性。
解鎖新的工作流
Druid為Clickstream,APM(應用性能管理系統(tǒng)),supply chain(供應鏈),網(wǎng)絡遙測,數(shù)字營銷和其他事件驅(qū)動形式的場景解鎖了新的查詢方式和工作流。Druid專為實時和歷史數(shù)據(jù)的快速臨時查詢而構建。
部署在AWS/GCP/Azure,混合云,k8s和租用服務器上
Druid可以部署在任何*NIX環(huán)境中。無論是內(nèi)部環(huán)境還是云環(huán)境。部署Druid是非常easy的:通過添加或刪減服務來擴容縮容。
使用場景
Apache Druid適用于對實時數(shù)據(jù)提取,高性能查詢和高可用要求較高的場景。因此,Druid通常被作為一個具有豐富GUI的分析系統(tǒng),或者作為一個需要快速聚合的高并發(fā)API的后臺。Druid更適合面向事件數(shù)據(jù)。
比較常見的使用場景:
點擊流分析(web和mobile分析)
風控分析
網(wǎng)路遙測分析(網(wǎng)絡性能監(jiān)控)
服務器指標存儲
供應鏈分析(制造業(yè)指標)
應用性能指標
商業(yè)智能/實時在線分析系統(tǒng)OLAP
下面將詳細分析這些使用場景:
用戶活動和行為
Druid經(jīng)常用在點擊流,訪問流,和活動流數(shù)據(jù)上。具體場景包括:衡量用戶參與度,為產(chǎn)品發(fā)布追蹤A/B測試數(shù)據(jù),并了解用戶使用方式。Druid可以做到精確和近似計算用戶指標,例如不重復計數(shù)指標。這意味著,如日活用戶指標可以在一秒鐘計算出近似值(平均精度98%),以查看總體趨勢,或精確計算以展示給利益相關者。Druid可以用來做“漏斗分析”,去測量有多少用戶做了某種操作,而沒有做另一個操作。這對產(chǎn)品追蹤用戶注冊十分有用。
網(wǎng)絡流
Druid常常用來收集和分析網(wǎng)絡流數(shù)據(jù)。Druid被用于管理以任意屬性切分組合的流數(shù)據(jù)。Druid能夠提取大量網(wǎng)絡流記錄,并且能夠在查詢時快速對數(shù)十個屬性組合和排序,這有助于網(wǎng)絡流分析。這些屬性包括一些核心屬性,如IP和端口號,也包括一些額外添加的強化屬性,如地理位置,服務,應用,設備和ASN。Druid能夠處理非固定模式,這意味著你可以添加任何你想要的屬性。
數(shù)字營銷
Druid常常用來存儲和查詢在線廣告數(shù)據(jù)。這些數(shù)據(jù)通常來自廣告服務商,它對衡量和理解廣告活動效果,點擊穿透率,轉(zhuǎn)換率(消耗率)等指標至關重要。
Druid最初就是被設計成一個面向廣告數(shù)據(jù)的強大的面向用戶的分析型應用程序。在存儲廣告數(shù)據(jù)方面,Druid已經(jīng)有大量生產(chǎn)實踐,全世界有大量用戶在上千臺服務器上存儲了PB級數(shù)據(jù)。
應用性能管理
Druid常常用于追蹤應用程序生成的可運營數(shù)據(jù)。和用戶活動使用場景類似,這些數(shù)據(jù)可以是關于用戶怎樣和應用程序交互的,它可以是應用程序自身上報的指標數(shù)據(jù)。Druid可用于下鉆發(fā)現(xiàn)應用程序不同組件的性能如何,定位瓶頸,和發(fā)現(xiàn)問題。
不像許多傳統(tǒng)解決方案,Druid具有更小存儲容量,更小復雜度,更大數(shù)據(jù)吞吐的特點。它可以快速分析數(shù)以千計屬性的應用事件,并計算復雜的加載,性能,利用率指標。比如,基于百分之95查詢延遲的API終端。我們可以以任何臨時屬性組織和切分數(shù)據(jù),如以天為時間切分數(shù)據(jù),如以用戶畫像統(tǒng)計,如按數(shù)據(jù)中心位置統(tǒng)計。
物聯(lián)網(wǎng)和設備指標
Driud可以作為時間序列數(shù)據(jù)庫解決方案,來存儲處理服務器和設備的指標數(shù)據(jù)。收集機器生成的實時數(shù)據(jù),執(zhí)行快速臨時的分析,去估量性能,優(yōu)化硬件資源,和定位問題。
和許多傳統(tǒng)時間序列數(shù)據(jù)庫不同,Druid本質(zhì)上是一個分析引擎。Druid融合了時間序列數(shù)據(jù)庫,列式分析數(shù)據(jù)庫,和檢索系統(tǒng)的理念。它在單個系統(tǒng)中支持了基于時間分區(qū),列式存儲,和搜索索引。這意味著基于時間的查詢,數(shù)字聚合,和檢索過濾查詢都會特別快。
你可以在你的指標中包括百萬唯一維度值,并隨意按任何維度組合group和filter(Druid 中的 dimension維度類似于時間序列數(shù)據(jù)庫中的tag)。你可以基于tag group和rank,并計算大量復雜的指標。而且你在tag上檢索和過濾會比傳統(tǒng)時間序列數(shù)據(jù)庫更快。
OLAP和商業(yè)智能
Druid經(jīng)常用于商業(yè)智能場景。公司部署Druid去加速查詢和增強應用。和基于Hadoop的SQL引擎(如Presto或Hive)不同,Druid為高并發(fā)和亞秒級查詢而設計,通過UI強化交互式數(shù)據(jù)查詢。這使得Druid更適合做真實的可視化交互分析。
技術
Apache Druid 是一個開源的分布式數(shù)據(jù)存儲引擎。Druid的核心設計融合了OLAP/analytic databases,timeseries database,和search systems的理念,以創(chuàng)造一個適用廣泛用例的統(tǒng)一系統(tǒng)。Druid將這三種系統(tǒng)的主要特性融合進Druid的ingestion layer(數(shù)據(jù)攝入層),storage format(存儲格式化層),querying layer(查詢層),和core architecture(核心架構)中。
.jpg)
Druid的主要特性包括:
列式存儲
Druid單獨存儲并壓縮每一列數(shù)據(jù)。并且查詢時只查詢特定需要查詢的數(shù)據(jù),支持快速scan,ranking和groupBy。
原生檢索索引
Druid為string值創(chuàng)建反向索引以達到數(shù)據(jù)的快速搜索和過濾。
流式和批量數(shù)據(jù)攝入
開箱即用的Apache kafka,HDFS,AWS S3連接器connectors,流式處理器。
靈活的數(shù)據(jù)模式
Druid優(yōu)雅地適應不斷變化的數(shù)據(jù)模式和嵌套數(shù)據(jù)類型。
基于時間的優(yōu)化分區(qū)
Druid基于時間對數(shù)據(jù)進行智能分區(qū)。因此,Druid基于時間的查詢將明顯快于傳統(tǒng)數(shù)據(jù)庫。
支持SQL語句
除了原生的基于JSON的查詢外,Druid還支持基于HTTP和JDBC的SQL。
水平擴展能力
百萬/秒的數(shù)據(jù)攝入速率,海量數(shù)據(jù)存儲,亞秒級查詢。
易于運維
可以通過添加或移除Server來擴容和縮容。Druid支持自動重平衡,失效轉(zhuǎn)移。
數(shù)據(jù)攝入
Druid同時支持流式和批量數(shù)據(jù)攝入。Druid通常通過像Kafka這樣的消息總線(加載流式數(shù)據(jù))或通過像HDFS這樣的分布式文件系統(tǒng)(加載批量數(shù)據(jù))來連接原始數(shù)據(jù)源。
Druid通過Indexing處理將原始數(shù)據(jù)以segment的方式存儲在數(shù)據(jù)節(jié)點,segment是一種查詢優(yōu)化的數(shù)據(jù)結(jié)構。
.jpg)
數(shù)據(jù)存儲
像大多數(shù)分析型數(shù)據(jù)庫一樣,Druid采用列式存儲。根據(jù)不同列的數(shù)據(jù)類型(string,number等),Druid對其使用不同的壓縮和編碼方式。Druid也會針對不同的列類型構建不同類型的索引。
類似于檢索系統(tǒng),Druid為string列創(chuàng)建反向索引,以達到更快速的搜索和過濾。類似于時間序列數(shù)據(jù)庫,Druid基于時間對數(shù)據(jù)進行智能分區(qū),以達到更快的基于時間的查詢。
不像大多數(shù)傳統(tǒng)系統(tǒng),Druid可以在數(shù)據(jù)攝入前對數(shù)據(jù)進行預聚合。這種預聚合操作被稱之為rollup,這樣就可以顯著的節(jié)省存儲成本。
.jpg)
查詢
Druid支持JSON-over-HTTP和SQL兩種查詢方式。除了標準的SQL操作外,Druid還支持大量的唯一性操作,利用Druid提供的算法套件可以快速的進行計數(shù),排名和分位數(shù)計算。
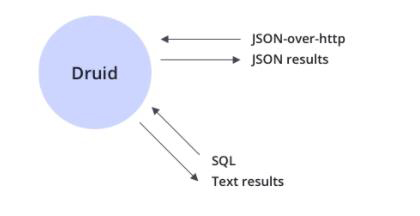
架構
Druid是微服務架構,可以理解為一個拆解成多個服務的數(shù)據(jù)庫。Druid的每一個核心服務(ingestion(攝入服務),querying(查詢服務),和coordination(協(xié)調(diào)服務))都可以單獨部署或聯(lián)合部署在商業(yè)硬件上。
Druid清晰的命名每一個服務,以確保運維人員可以根據(jù)使用情況和負載情況很好地調(diào)整相應服務的參數(shù)。例如,當負載需要時,運維人員可以給數(shù)據(jù)攝入服務更多的資源而減少數(shù)據(jù)查詢服務的資源。
Druid可以獨立失敗而不影響其他服務的運行。
.jpg)
運維
Drui被設計成一個健壯的系統(tǒng),它需要7*24小時運行。Druid擁有以下特性,以確保長期運行,并保證數(shù)據(jù)不丟失。
數(shù)據(jù)副本
Druid根據(jù)配置的副本數(shù)創(chuàng)建多個數(shù)據(jù)副本,所以單機失效不會影響Druid的查詢。
獨立服務
Druid清晰的命名每一個主服務,每一個服務都可以根據(jù)使用情況做相應的調(diào)整。服務可以獨立失敗而不影響其他服務的正常運行。例如,如果數(shù)據(jù)攝入服務失效了,將沒有新的數(shù)據(jù)被加載進系統(tǒng),但是已經(jīng)存在的數(shù)據(jù)依然可以被查詢。
自動數(shù)據(jù)備份
Druid自動備份所有已經(jīng)indexed的數(shù)據(jù)到一個文件系統(tǒng),它可以是分布式文件系統(tǒng),如HDFS。你可以丟失所有Druid集群的數(shù)據(jù),并快速從備份數(shù)據(jù)中重新加載。
滾動更新
通過滾動更新,你可以在不停機的情況下更新Druid集群,這樣對用戶就是無感知的。所有Druid版本都是向后兼容。
想了解時間序列數(shù)據(jù)庫和對比,可移步另一篇文章:
時間序列數(shù)據(jù)庫(TSDB)初識與選擇
感謝你能夠認真閱讀完這篇文章,希望小編分享的“apache druid有什么用”這篇文章對大家有幫助,同時也希望大家多多支持創(chuàng)新互聯(lián),關注創(chuàng)新互聯(lián)行業(yè)資訊頻道,更多相關知識等著你來學習!
網(wǎng)頁名稱:apachedruid有什么用
URL標題:http://chinadenli.net/article30/gphhso.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供外貿(mào)網(wǎng)站建設、用戶體驗、服務器托管、網(wǎng)頁設計公司、關鍵詞優(yōu)化、網(wǎng)站建設
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 網(wǎng)站的結(jié)構對網(wǎng)站排名有何價值? 2020-07-26
- 分享網(wǎng)站排名下降的因素 2021-10-14
- 網(wǎng)站排名上不去怎么辦 創(chuàng)新互聯(lián)網(wǎng)站優(yōu)化全新方法分享 2021-05-03
- 【SEO優(yōu)化】網(wǎng)站排名優(yōu)化技巧 2022-05-02
- 網(wǎng)站排名經(jīng)常不穩(wěn)定的幾點原因 2021-06-04
- 如何優(yōu)化移動端的網(wǎng)站排名? 2021-09-19
- 認識SEO四類錯誤,快速提升網(wǎng)站排名 2017-02-21
- 怎么優(yōu)化關鍵詞?別讓錯誤的編寫內(nèi)容成為傷害網(wǎng)站排名的刀 2022-08-16
- 堅持發(fā)原創(chuàng)文章網(wǎng)站排名就一定能上去嗎? 2020-08-07
- 濱州網(wǎng)站排名作為一名SEO外鏈專員應晉升本身在SEO方面的本領 2023-01-17
- 詳解SEO布詞以及網(wǎng)站排名優(yōu)化技巧 2022-12-24
- 視覺效果設計對網(wǎng)站排名的重要性 2016-12-15