lxml與pyquery解析html的方法
本篇內(nèi)容主要講解“l(fā)xml與pyquery解析html的方法”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強(qiáng)。下面就讓小編來帶大家學(xué)習(xí)“l(fā)xml與pyquery解析html的方法”吧!
創(chuàng)新互聯(lián)制作網(wǎng)站網(wǎng)頁找三站合一網(wǎng)站制作公司,專注于網(wǎng)頁設(shè)計,做網(wǎng)站、成都做網(wǎng)站,網(wǎng)站設(shè)計,企業(yè)網(wǎng)站搭建,網(wǎng)站開發(fā),建網(wǎng)站業(yè)務(wù),680元做網(wǎng)站,已為上1000+服務(wù),創(chuàng)新互聯(lián)網(wǎng)站建設(shè)將一如既往的為我們的客戶提供最優(yōu)質(zhì)的網(wǎng)站建設(shè)、網(wǎng)絡(luò)營銷推廣服務(wù)!
lxml
首先來了解一下lxml,很多常用的解析html的庫都用到了lxml這個庫,例如BeautifulSoup、pyquery。
下面我們介紹一下lxml關(guān)于html解析的3個Element。
_Element
_Element獲取
from lxml import etree text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first</a></li> <li class="item-1"><a href="link2.html">second</a></li> <li class="item-0"><a href="link3.html">third</a></li> </ul> </div> ''' # lxml.etree._Element element = etree.HTML(text)
_Element常用方法
# 通過css選擇器獲取節(jié)點 cssselect(expr) # 通過標(biāo)簽或者xpath語法獲取第一個匹配 find(path) # 通過標(biāo)簽或者xpath語法獲取所有匹配 findall(path) # 獲取屬性值 get(key) # 獲取所有屬性 items() # 獲取所有屬性名稱 keys() # 獲取所有屬性值 values() # 獲取子節(jié)點 getchildren() # 獲取父節(jié)點 getparent() # 獲取相鄰的下一個節(jié)點 getnext() # 獲取相鄰的上一個節(jié)點 getprevious() # 迭代節(jié)點 iter(tag) # 通過xpath表達(dá)式獲取節(jié)點 xpath(path)
_Element示例
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first</a></li>
<li class="item-1"><a href="link2.html">second</a></li>
<li class="item-0" rel="third"><a href="link3.html">third</a></li>
</ul>
</div>
'''
element = etree.HTML(text)
# css選擇器,獲取class為item-0的li節(jié)點
lis = element.cssselect("li.item-0")
for li in lis:
# 獲取class屬性
print(li.get("class"))
# 獲取屬性名稱和值,元組列表
print(li.items())
# 獲取節(jié)點所有的屬性名稱
print(li.keys())
# 獲取所有屬性值
print(li.values())
print("--------------")
ass = element.cssselect("li a")
for a in ass:
# 獲取文本節(jié)點
print(a.text)
print("--------------")
# 獲取第一個li節(jié)點
li = element.find("li")
# 獲取所有l(wèi)i節(jié)點
lis = element.find("li")
# 獲取所有的a節(jié)點
lias = element.iter("a")
for lia in lias:
print(lia.get("href"))
textStr = element.itertext("a")
for ts in textStr:
print(ts)xpath我們后面單獨介紹。
_ElementTree
_ElementTree獲取
from io import StringIO from lxml import etree text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first</a></li> <li class="item-1"><a href="link2.html">second</a></li> <li class="item-0"><a href="link3.html">third</a></li> </ul> </div> ''' parser = etree.HTMLParser() # lxml.etree._ElementTree elementTree = etree.parse(StringIO(text), parser) # 可以直接從文件讀取 # elementTree = etree.parse(r'F:\tmp\etree.html',parser)
_ElementTree常用方法
find(path) findall(path) iter(tag) xpath(path)
_ElementTree方法和 _Element的同名方法使用基本一樣。
有很多不同的是_ElementTree的find和findall方法只接受xpath表達(dá)式。
_ElementTree示例
from io import StringIO
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first</a></li>
<li class="item-1"><a href="link2.html">second</a></li>
<li class="item-0"><a href="link3.html">third</a></li>
</ul>
</div>
'''
parser = etree.HTMLParser()
elementTree = etree.parse(StringIO(text), parser)
lis = elementTree.iter("li")
for li in lis:
print(type(li))
print("---------")
firstLi = elementTree.find("//li")
print(type(firstLi))
print(firstLi.get("class"))
print("---------")
ass = elementTree.findall("//li/a")
for a in ass:
print(a.text)HtmlElement
HtmlElement獲取
import lxml.html text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first</a></li> <li class="item-1"><a href="link2.html">second</a></li> <li class="item-0"><a href="link3.html">third</a> </ul> </div> ''' # lxml.html.HtmlElement htmlElement = lxml.html.fromstring(text)
HtmlElement繼承了etree.ElementBase和HtmlMixin,etree.ElementBase繼承了_Element。
因為HtmlElement繼承了_Element,所以_Element中介紹的方法,HtmlElement都可以使用。 HtmlElement還可以使用HtmlMixin中的方法。
HtmlMixin常用方法
# 通過類名獲取節(jié)點 find_class(class_name) # 通過id獲取節(jié)點 get_element_by_id(id) # 獲取文本節(jié)點 text_content() # 通過css選擇器獲取節(jié)點 cssselect(expr)
xpath
xpath功能非常強(qiáng)大,并且_Element、_ElementTree、HtmlElement都可以使用xpath表達(dá)式,所以最后介紹一下xpath。
| 表達(dá)式 | 描述 |
|---|---|
| / | 從根節(jié)點開始,絕對路徑 |
| // | 從當(dāng)前節(jié)點選取子孫節(jié)點,相對路徑,不關(guān)心位置 |
| . | 選取當(dāng)前節(jié)點 |
| .. | 選取當(dāng)前節(jié)點的父節(jié)點 |
| @ | 選取屬性 |
| * | 通配符,選擇所有元素節(jié)點與元素名 |
| @* | 選取所有屬性 |
| [@attrib] | 選取具有給定屬性的所有元素 |
| [@attrib='value'] | 選取給定屬性具有給定值的所有元素 |
| [tag] | 選取所有具有指定元素的直接子節(jié)點 |
| [tag='text'] | 選取所有具有指定元素并且文本內(nèi)容是text節(jié)點 |
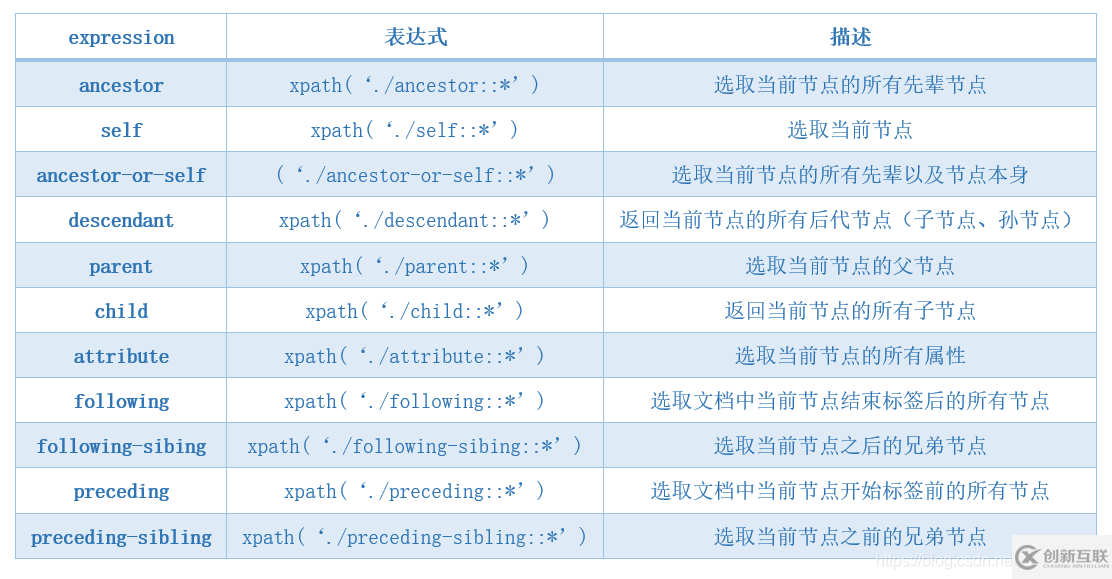
| expression | 表達(dá)式 | 描述 |
|---|---|---|
| ancestor | xpath('./ancestor:: *') | 選取當(dāng)前節(jié)點的所有先輩節(jié)點 |
| ancestor-or-self | ('./ancestor-or-self:: *') | 選取當(dāng)前節(jié)點的所有先輩以及節(jié)點本身 |
| attribute | xpath('./attribute:: *') | 選取當(dāng)前節(jié)點的所有屬性 |
| child | xpath('./child:: *') | 返回當(dāng)前節(jié)點的所有子節(jié)點 |
| descendant | xpath('./descendant:: *') | 返回當(dāng)前節(jié)點的所有后代節(jié)點(子節(jié)點、孫節(jié)點) |
| following | xpath('./following:: *') | 選取文檔中當(dāng)前節(jié)點結(jié)束標(biāo)簽后的所有節(jié)點 |
| following-sibing | xpath('./following-sibing:: *') | 選取當(dāng)前節(jié)點之后的兄弟節(jié)點 |
| parent | xpath('./parent:: *') | 選取當(dāng)前節(jié)點的父節(jié)點 |
| preceding | xpath('./preceding:: *') | 選取文檔中當(dāng)前節(jié)點開始標(biāo)簽前的所有節(jié)點 |
| preceding-sibling | xpath('./preceding-sibling:: *') | 選取當(dāng)前節(jié)點之前的兄弟節(jié)點 |
| self | xpath('./self:: *') | 選取當(dāng)前節(jié)點 |
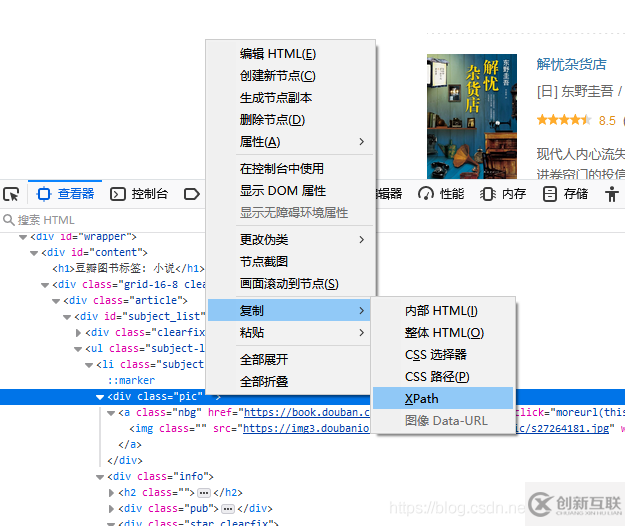
很多時候我們可以通過瀏覽器獲取xpath表達(dá)式:
示例
from lxml.html.clean import Cleaner
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0" rel="li1"><a href="link1.html">first</a></li>
<li class="item-1" rel="li2"><a href="link2.html" rel="attrRel">second</a></li>
<li class="item-0" rel="li3"><a href="link3.html" id="thirda">third</a>
</ul>
</div>
'''
# 去除css、script
cleaner = Cleaner(style=True, scripts=True, page_structure=False, safe_attrs_only=False)
print(cleaner.clean_html(text))
# _Element
element = etree.HTML(text)
# 文本節(jié)點,特殊字符轉(zhuǎn)義
print(element.xpath('//text()'))
# 文本節(jié)點,不轉(zhuǎn)義
print(element.xpath('string()'))
# find、findall只能使用相對路徑,以.//開頭
print(element.findall('.//a[@rel]'))
print(element.find('.//a[@rel]'))
# 獲取包含rel屬性的a節(jié)點
print(element.xpath('//a[@rel]'))
# 獲取ul元素下的第一個li節(jié)點,注意是列表,因為ul可能有多個
print(element.xpath("//ul/li[1]"))
# 獲取ul元素下rel屬性為li2的li節(jié)點
print(element.xpath("//ul/li[@rel='li2']"))
# 獲取ul元素下的倒數(shù)第2個節(jié)點
print(element.xpath("//ul/li[last()-1]"))
# 獲取ul元素下的前2個li節(jié)點
print(element.xpath("//ul/li[position()<3]"))
# 獲取li元素下的所有a節(jié)點
for a in element.xpath("//li/a"):
print(a.text)
print(a.get("href"))
# 獲取父節(jié)點,列表,因為可能匹配多個a
print(element.xpath('//a[@href="link2.html"]/parent::*'))
# 獲取的是文本節(jié)點對象列表
print(element.xpath('//li[@class="item-1"]/a/text()'))
print("---------------")
# 獲取a的href屬性
print(element.xpath('//li/a/@href'))
# 獲取所有l(wèi)i子孫節(jié)點的href屬性
print(element.xpath('//li//@href'))xpath示例
from lxml import etree
text = '''
<li class="subject-item">
<div class="pic">
<a class="nbg" href="https://book.douban.com/subject/25862578/">
<img class="" src="https://img3.doubanio.com/view/subject/m/public/s27264181.jpg" width="90">
</a>
</div>
<div class="info">
<h3 class=""><a href="https://book.douban.com/subject/25862578/" title="解憂雜貨店">解憂雜貨店</a></h3>
<div class="pub">[日] 東野圭吾 / 李盈春 / 南海出版公司 / 2014-5 / 39.50元</div>
<div class="star clearfix">
<span class="allstar45"></span>
<span class="rating_nums">8.5</span>
<span class="pl">
(537322人評價)
</span>
</div>
<p>現(xiàn)代人內(nèi)心流失的東西,這家雜貨店能幫你找回——僻靜的街道旁有一家雜貨店,只要寫下煩惱投進(jìn)卷簾門的投信口,第二天就會在店后的牛奶箱里得到回答。因男友身患絕... </p>
</div>
</li>
'''
element = etree.HTML(text)
# 查找符合xpath(//li/div/a)的節(jié)點
aeles = element.xpath("//li/div/a")
for aele in aeles:
# 獲取href屬性
print(aele.get("href"))
# 查找img標(biāo)簽,并且獲取src屬性
print(aele.find("img").get("src"))
# 返回列表的原因是:雖然我們只取了第一個a節(jié)點,但是上級xpath(//li/div[@class='info']/h3)可能匹配多個
for a in element.xpath("//li/div[@class='info']/h3/a[1]"):
print(a.get("href"))
print(a.text)
# print(a.get("title"))
# 指定div的class屬性
for pu in element.xpath("//li/div[@class='info']/div[@class='pub']"):
print(pu.text)
# 使用到contains函數(shù)和or運算符
spans = element.xpath("//li/div[@class='info']/div[@class='star clearfix']/span[contains(@class,'rating_nums') or "
"contains(@class,'pl')]")
for span in spans:
print(span.text.strip())
for content in element.xpath("//li/div[@class='info']/p"):
print(content.text)
# 如果確定只有一個或者只需要第一個可以使用find,注意find使用xpath為參數(shù)的時候使用相對路徑(.//開頭)
print(element.find(".//li/div[@class='info']/p").text)pyquery
構(gòu)造PyQuery
從字符串:
from pyquery import PyQuery as pq html = '' with open(r"F:\tmp\db.html", "r", encoding='utf-8') as f: html = f.read() doc = pq(html)
從URL:
from pyquery import PyQuery as pq
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'
}
doc = pq('https://book.douban.com/tag/小說', headers=headers)從文件:
from pyquery import PyQuery as pq doc = pq(filename=r"F:\tmp\db.html")
從文件有一個問題就是不能指定文件編碼,所以一般都是自己讀取文件,然后從字符串構(gòu)造。
選擇器
pyquery最強(qiáng)大的地方就在于,它可以像jQuery使用css選擇器一樣獲取節(jié)點。
常用的一些選擇器:
id選擇器(#id) 類選擇器(.class) 屬性選擇器(a[href="xxx"]) 偽類選擇器(:first :last :even :odd :eq :lt :gt :checked :selected)
前面我們已經(jīng)知道怎樣構(gòu)造一個PyQuery,上面我們有知道了怎么通過選擇器獲取節(jié)點,下面我們通過一個小示例來具體了解一下。
from pyquery import PyQuery as pq
html = '''
<!DOCTYPE html>
<html>
<head>
<title>pyquery</title>
</head>
<body>
<ul id="container">
<li class="li1">li1</li>
<li class="li2">li2</li>
<li class="li3" data-type='3'>li3</li>
</ul>
</body>
</html>
'''
doc = pq(html)
# id選擇器,outerHtml輸出整體的html
print(doc("#container").outerHtml())
print("----------")
# 類選擇器
print(doc(".li1").outerHtml())
print("----------")
# 偽類選擇器
# 選擇第2個li節(jié)點,并通過text獲取該li節(jié)點的值
print(doc('li:nth-child(2)').text())
# 獲取第1個li節(jié)點
print(doc('li:first-child').text())
# 獲取最后一個li節(jié)點,并通過attr獲取該節(jié)點的data-type屬性值
print(doc('li:last-child').attr("data-type"))
print(doc("li:contains('li3')").attr("data-type"))
print("----------")
# 屬性選擇器
# 選擇li的data-type的屬性值為3的節(jié)點
print(doc("li[data-type='3']").outerHtml())首先我們通過html字符串構(gòu)造了一個PyQuery對象,然后就可以通過選擇器愉快的獲取我們想要的節(jié)點了。
注意:上面的text方法是獲取節(jié)點的文本,attr是獲取節(jié)點的屬性,非常常用
這里就補(bǔ)貼輸出代碼了,如果感興趣可以自己動手嘗試一下,看一下輸出。
查找與過濾節(jié)點
很多時候,我們并不能直接通過選擇器一步到位的獲取到我們需要的節(jié)點,所以我們需要另外一些查找、過濾、遍歷節(jié)點的方法,例如:find、filter、eq、not_、items、each等,下面我們還是通過一個小例子來介紹一下這些方法。
from pyquery import PyQuery as pq
html = '''
<!DOCTYPE html>
<html>
<head>
<title>pyquery</title>
</head>
<body>
<ul id="container">
<li class="li1">li1</li>
<li class="li2">li2</li>
<li class="li3" data-type='3'>li3</li>
</ul>
</body>
</html>
'''
doc = pq(html)
# find的語法和直接使用選擇器一樣
print("---find:")
print(doc.find("li").show())
# 輸出li的個數(shù)
print(doc.find("li").size())
# filter過濾得到滿足條件的
print("---filter:")
print(doc.find("li").filter(".li3").show())
# eq選擇第n個,下標(biāo)從0開始
print("---eq:")
print(doc.find("li").eq(1).show())
# not_排除滿足條件的節(jié)點
print("---not_:")
print(doc.find("li").not_("li[data-type='3']").show())
lis = doc.find("li")
# 輸出PyQuery
print(type(lis))
# each輸出的類型是lxml.etree._Element
print("---each:")
lis.each(lambda i, e: print(type(e)))
print("---for:")
for li in lis:
print(type(li))
# items獲取到的類型才是PyQuery
print("---items:")
for li in lis.items():
print(type(li))這些方法還是比較基礎(chǔ)的,看代碼中的注釋就能知道是什么意思了,如果有疑問,可以自己動手調(diào)試一下。
注意lis是PyQuery類型,PyQuery的each是lxml.etree._Element類型,items才是PyQuery
這意味著使用for\each循環(huán)不能使用PyQuery的find、filter、text、attr這些方法。
需要使用lxml.etree._Element的方法。
到此,相信大家對“l(fā)xml與pyquery解析html的方法”有了更深的了解,不妨來實際操作一番吧!這里是創(chuàng)新互聯(lián)網(wǎng)站,更多相關(guān)內(nèi)容可以進(jìn)入相關(guān)頻道進(jìn)行查詢,關(guān)注我們,繼續(xù)學(xué)習(xí)!
本文名稱:lxml與pyquery解析html的方法
本文來源:http://chinadenli.net/article24/jgjgje.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站維護(hù)、做網(wǎng)站、云服務(wù)器、虛擬主機(jī)、域名注冊、動態(tài)網(wǎng)站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 5秒讓您明白為何需要自適應(yīng)網(wǎng)站 2019-10-21
- 響應(yīng)式網(wǎng)站布局和自適應(yīng)網(wǎng)站布局區(qū)別在哪 2021-10-04
- 自適應(yīng)網(wǎng)站和普通的網(wǎng)站有什么不同 2016-11-11
- 自適應(yīng)網(wǎng)站建設(shè)注意要點有哪些 2020-12-04
- 如何開發(fā)一個真正的自適應(yīng)網(wǎng)站? 2016-11-11
- 上海自適應(yīng)網(wǎng)站建設(shè)要注意什么? 2020-12-28
- 響應(yīng)式網(wǎng)站建設(shè)和自適應(yīng)網(wǎng)站建設(shè)之間的區(qū)別 2014-10-17
- 在網(wǎng)站開發(fā)中傳統(tǒng)的網(wǎng)站相對于自適應(yīng)網(wǎng)站有著什么樣的劣勢呢? 2016-10-27
- 自適應(yīng)網(wǎng)站建設(shè)方案 2021-05-15
- 建設(shè)營銷型手機(jī)網(wǎng)站應(yīng)注意哪些要素? 2022-05-22
- 自適應(yīng)網(wǎng)站與傳統(tǒng)網(wǎng)站的區(qū)別及優(yōu)缺點 2022-08-10
- 自適應(yīng)網(wǎng)站是什么意思?專業(yè)自適應(yīng)網(wǎng)站建設(shè)的公司 2022-05-11