如何從數(shù)據(jù)存儲角度分析Redis為何這么快
如何從數(shù)據(jù)存儲角度分析redis為何這么快,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細(xì)講解,有這方面需求的人可以來學(xué)習(xí)下,希望你能有所收獲。
創(chuàng)新互聯(lián)公司是專業(yè)的萊蕪網(wǎng)站建設(shè)公司,萊蕪接單;提供成都做網(wǎng)站、成都網(wǎng)站建設(shè),網(wǎng)頁設(shè)計,網(wǎng)站設(shè)計,建網(wǎng)站,PHP網(wǎng)站建設(shè)等專業(yè)做網(wǎng)站服務(wù);采用PHP框架,可快速的進(jìn)行萊蕪網(wǎng)站開發(fā)網(wǎng)頁制作和功能擴(kuò)展;專業(yè)做搜索引擎喜愛的網(wǎng)站,專業(yè)的做網(wǎng)站團(tuán)隊(duì),希望更多企業(yè)前來合作!
一、簡介和應(yīng)用
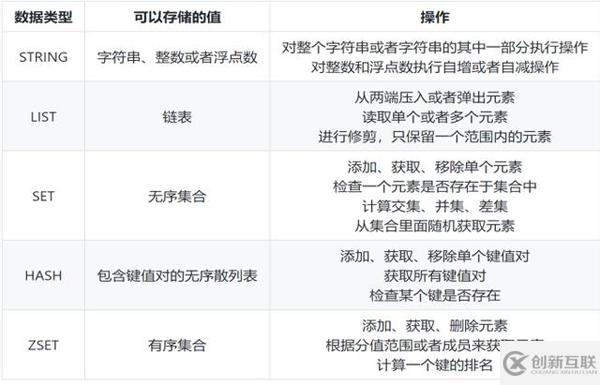
Redis是一個由ANSI C語言編寫,性能優(yōu)秀、支持網(wǎng)絡(luò)、可持久化的K-K內(nèi)存數(shù)據(jù)庫,并提供多種語言的API。它常用的類型主要是 String、List、Hash、Set、ZSet 這5種
Redis在互聯(lián)網(wǎng)公司一般有以下應(yīng)用:
String:緩存、限流、計數(shù)器、分布式鎖、分布式Session
Hash:存儲用戶信息、用戶主頁訪問量、組合查詢
List:微博關(guān)注人時間軸列表、簡單隊(duì)列
Set:贊、踩、標(biāo)簽、好友關(guān)系
Zset:排行榜
再比如電商在大促銷時,會用一些特殊的設(shè)計來保證系統(tǒng)穩(wěn)定,扣減庫存可以考慮如下設(shè)計:

上圖中,直接在Redis中扣減庫存,記錄日志后通過Worker同步到數(shù)據(jù)庫,在設(shè)計同步Worker時需要考慮并發(fā)處理和重復(fù)處理的問題。
通過上面的應(yīng)用場景可以看出Redis是非常高效和穩(wěn)定的,那Redis底層是如何實(shí)現(xiàn)的呢?
二、Redis的對象redisObject
當(dāng)我們執(zhí)行set hello world命令時,會有以下數(shù)據(jù)模型:
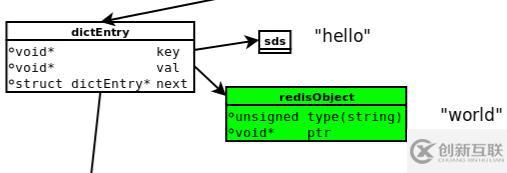
dictEntry:Redis給每個key-value鍵值對分配一個dictEntry,里面有著key和val的指針,next指向下一個dictEntry形成鏈表,這個指針可以將多個哈希值相同的鍵值對鏈接在一起,由此來解決哈希沖突問題(鏈地址法)。
sds:鍵key“hello”是以SDS(簡單動態(tài)字符串)存儲,后面詳細(xì)介紹。
redisObject:值val“world”存儲在redisObject中。實(shí)際上,redis常用5中類型都是以redisObject來存儲的;而redisObject中的type字段指明了Value對象的類型,ptr字段則指向?qū)ο笏诘牡刂贰?/p>
redisObject對象非常重要,Redis對象的類型、內(nèi)部編碼、內(nèi)存回收、共享對象等功能,都需要redisObject支持。這樣設(shè)計的好處是,可以針對不同的使用場景,對5中常用類型設(shè)置多種不同的數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn),從而優(yōu)化對象在不同場景下的使用效率。
無論是dictEntry對象,還是redisObject、SDS對象,都需要內(nèi)存分配器(如jemalloc)分配內(nèi)存進(jìn)行存儲。jemalloc作為Redis的默認(rèn)內(nèi)存分配器,在減小內(nèi)存碎片方面做的相對比較好。比如jemalloc在64位系統(tǒng)中,將內(nèi)存空間劃分為小、大、巨大三個范圍;每個范圍內(nèi)又劃分了許多小的內(nèi)存塊單位;當(dāng)Redis存儲數(shù)據(jù)時,會選擇大小最合適的內(nèi)存塊進(jìn)行存儲。
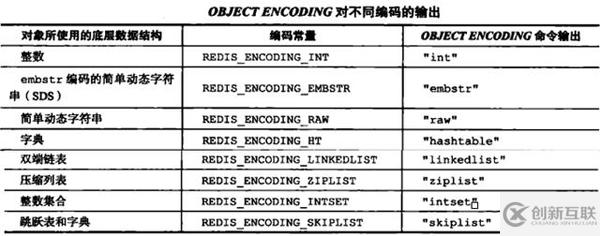
前面說過,Redis每個對象由一個redisObject結(jié)構(gòu)表示,它的ptr指針指向底層實(shí)現(xiàn)的數(shù)據(jù)結(jié)構(gòu),而數(shù)據(jù)結(jié)構(gòu)由encoding屬性決定。比如我們執(zhí)行以下命令得到存儲“hello”對應(yīng)的編碼:

redis所有的數(shù)據(jù)結(jié)構(gòu)類型如下(重要,后面會用):
三、String
字符串對象的底層實(shí)現(xiàn)可以是int、raw、embstr(上面的表對應(yīng)有名稱介紹)。embstr編碼是通過調(diào)用一次內(nèi)存分配函數(shù)來分配一塊連續(xù)的空間,而raw需要調(diào)用兩次。

int編碼字符串對象和embstr編碼字符串對象在一定條件下會轉(zhuǎn)化為raw編碼字符串對象。embstr:<=39字節(jié)的字符串。int:8個字節(jié)的長整型。raw:大于39個字節(jié)的字符串。
簡單動態(tài)字符串(SDS),這種結(jié)構(gòu)更像C++的String或者Java的ArrayList<Character>,長度動態(tài)可變:
struct sdshdr { // buf 中已占用空間的長度 int len; // buf 中剩余可用空間的長度 int free; // 數(shù)據(jù)空間 char buf[]; // ’’空字符結(jié)尾 };get:sdsrange---O(n)
set:sdscpy—O(n)
create:sdsnew---O(1)
len:sdslen---O(1)
常數(shù)復(fù)雜度獲取字符串長度:因?yàn)镾DS在len屬性中記錄了長度,所以獲取一個SDS長度時間復(fù)雜度僅為O(1)。
預(yù)空間分配:如果對一個SDS進(jìn)行修改,分為一下兩種情況:
SDS長度(len的值)小于1MB,那么程序?qū)⒎峙浜蚻en屬性同樣大小的未使用空間,這時free和len屬性值相同。舉個例子,SDS的len將變成15字節(jié),則程序也會分配15字節(jié)的未使用空間,SDS的buf數(shù)組的實(shí)際長度變成15+15+1=31字節(jié)(額外一個字節(jié)用戶保存空字符)。
SDS長度(len的值)大于等于1MB,程序會分配1MB的未使用空間。比如進(jìn)行修改之后,SDS的len變成30MB,那么它的實(shí)際長度是30MB+1MB+1byte。
惰性釋放空間:當(dāng)執(zhí)行sdstrim(截取字符串)之后,SDS不會立馬釋放多出來的空間,如果下次再進(jìn)行拼接字符串操作,且拼接的沒有剛才釋放的空間大,則那些未使用的空間就會排上用場。通過惰性釋放空間避免了特定情況下操作字符串的內(nèi)存重新分配操作。
杜絕緩沖區(qū)溢出:使用C字符串的操作時,如果字符串長度增加(如strcat操作)而忘記重新分配內(nèi)存,很容易造成緩沖區(qū)的溢出;而SDS由于記錄了長度,相應(yīng)的操作在可能造成緩沖區(qū)溢出時會自動重新分配內(nèi)存,杜絕了緩沖區(qū)溢出。
四、List
List對象的底層實(shí)現(xiàn)是quicklist(快速列表,是ziplist 壓縮列表 和linkedlist 雙端鏈表 的組合)。Redis中的列表支持兩端插入和彈出,并可以獲得指定位置(或范圍)的元素,可以充當(dāng)數(shù)組、隊(duì)列、棧等。
typedef struct listNode { // 前置節(jié)點(diǎn) struct listNode *prev; // 后置節(jié)點(diǎn) struct listNode *next; // 節(jié)點(diǎn)的值 void *value; } listNode; typedef struct list { // 表頭節(jié)點(diǎn) listNode *head; // 表尾節(jié)點(diǎn) listNode *tail; // 節(jié)點(diǎn)值復(fù)制函數(shù) void *(*dup)(void *ptr); // 節(jié)點(diǎn)值釋放函數(shù) void (*free)(void *ptr); // 節(jié)點(diǎn)值對比函數(shù) int (*match)(void *ptr, void *key); // 鏈表所包含的節(jié)點(diǎn)數(shù)量 unsigned long len; } list;rpush: listAddNodeHead ---O(1)
lpush: listAddNodeTail ---O(1)
push:listInsertNode ---O(1)
index : listIndex ---O(N)
pop:ListFirst/listLast ---O(1)
llen:listLength ---O(N)
4.1 linkedlist(雙端鏈表)
此結(jié)構(gòu)比較像Java的LinkedList,有興趣可以閱讀一下源碼。
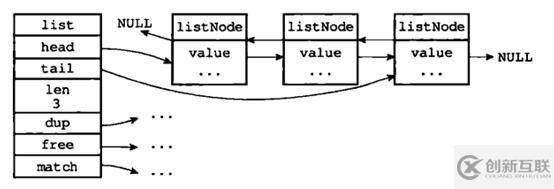
從圖中可以看出Redis的linkedlist雙端鏈表有以下特性:節(jié)點(diǎn)帶有prev、next指針、head指針和tail指針,獲取前置節(jié)點(diǎn)、后置節(jié)點(diǎn)、表頭節(jié)點(diǎn)和表尾節(jié)點(diǎn)的復(fù)雜度都是O(1)。len屬性獲取節(jié)點(diǎn)數(shù)量也為O(1)。
與雙端鏈表相比,壓縮列表可以節(jié)省內(nèi)存空間,但是進(jìn)行修改或增刪操作時,復(fù)雜度較高;因此當(dāng)節(jié)點(diǎn)數(shù)量較少時,可以使用壓縮列表;但是節(jié)點(diǎn)數(shù)量多時,還是使用雙端鏈表劃算。
4.2 ziplist(壓縮列表)
當(dāng)一個列表鍵只包含少量列表項(xiàng),且是小整數(shù)值或長度比較短的字符串時,那么redis就使用ziplist(壓縮列表)來做列表鍵的底層實(shí)現(xiàn)。
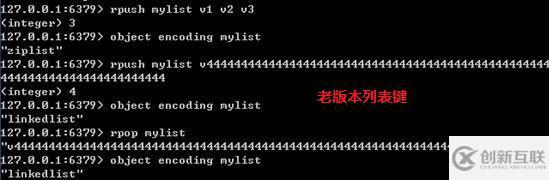
ziplist是Redis為了節(jié)約內(nèi)存而開發(fā)的,是由一系列特殊編碼的連續(xù)內(nèi)存塊(而不是像雙端鏈表一樣每個節(jié)點(diǎn)是指針)組成的順序型數(shù)據(jù)結(jié)構(gòu);具體結(jié)構(gòu)相對比較復(fù)雜,有興趣讀者可以看 Redis 哈希結(jié)構(gòu)內(nèi)存模型剖析。在新版本中list鏈表使用 quicklist 代替了 ziplist和 linkedlist:

quickList 是 zipList 和 linkedList 的混合體。它將 linkedList 按段切分,每一段使用 zipList 來緊湊存儲,多個 zipList 之間使用雙向指針串接起來。因?yàn)殒湵淼母郊涌臻g相對太高,prev 和 next 指針就要占去 16 個字節(jié) (64bit 系統(tǒng)的指針是 8 個字節(jié)),另外每個節(jié)點(diǎn)的內(nèi)存都是單獨(dú)分配,會加劇內(nèi)存的碎片化,影響內(nèi)存管理效率。
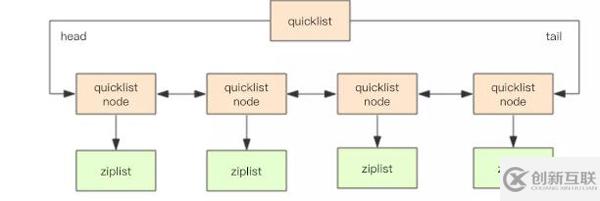
quicklist 默認(rèn)的壓縮深度是 0,也就是不壓縮。為了支持快速的 push/pop 操作,quicklist 的首尾兩個 ziplist 不壓縮,此時深度就是 1。為了進(jìn)一步節(jié)約空間,Redis 還會對 ziplist 進(jìn)行壓縮存儲,使用 LZF 算法壓縮。
五、Hash
Hash對象的底層實(shí)現(xiàn)可以是ziplist(壓縮列表)或者h(yuǎn)ashtable(字典或者也叫哈希表)。
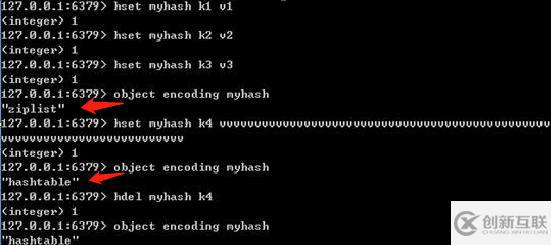
Hash對象只有同時滿足下面兩個條件時,才會使用ziplist(壓縮列表):1.哈希中元素數(shù)量小于512個;2.哈希中所有鍵值對的鍵和值字符串長度都小于64字節(jié)。
hashtable哈希表可以實(shí)現(xiàn)O(1)復(fù)雜度的讀寫操作,因此效率很高。源碼如下:
typedef struct dict { // 類型特定函數(shù) dictType *type; // 私有數(shù)據(jù) void *privdata; // 哈希表 dictht ht[2]; // rehash 索引 // 當(dāng) rehash 不在進(jìn)行時,值為 -1 int rehashidx; /* rehashing not in progress if rehashidx == -1 */ // 目前正在運(yùn)行的安全迭代器的數(shù)量 int iterators; /* number of iterators currently running */ } dict; typedef struct dictht { // 哈希表數(shù)組 dictEntry **table; // 哈希表大小 unsigned long size; // 哈希表大小掩碼,用于計算索引值 // 總是等于 size - 1 unsigned long sizemask; // 該哈希表已有節(jié)點(diǎn)的數(shù)量 unsigned long used; } dictht; typedef struct dictEntry { void *key; union {void *val;uint64_t u64;int64_t s64;} v; // 指向下個哈希表節(jié)點(diǎn),形成鏈表 struct dictEntry *next; } dictEntry; typedef struct dictType { // 計算哈希值的函數(shù) unsigned int (*hashFunction)(const void *key); // 復(fù)制鍵的函數(shù) void *(*keyDup)(void *privdata, const void *key); // 復(fù)制值的函數(shù) void *(*valDup)(void *privdata, const void *obj); // 對比鍵的函數(shù) int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 銷毀鍵的函數(shù) void (*keyDestructor)(void *privdata, void *key); // 銷毀值的函數(shù) void (*valDestructor)(void *privdata, void *obj); } dictType;上面源碼可以簡化成如下結(jié)構(gòu):
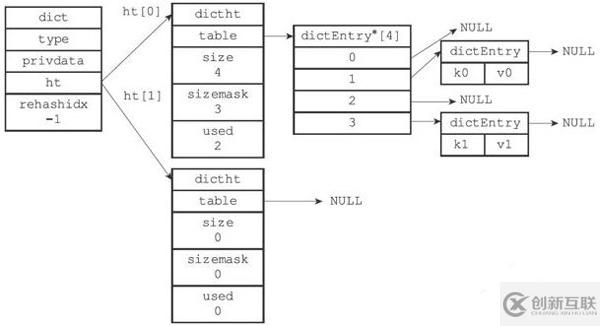
這個結(jié)構(gòu)類似于JDK7以前的HashMap<String,Object>,當(dāng)有兩個或以上的鍵被分配到哈希數(shù)組的同一個索引上時,會產(chǎn)生哈希沖突。Redis也使用鏈地址法來解決鍵沖突。即每個哈希表節(jié)點(diǎn)都有一個next指針,多個哈希表節(jié)點(diǎn)用next指針構(gòu)成一個單項(xiàng)鏈表,鏈地址法就是將相同hash值的對象組織成一個鏈表放在hash值對應(yīng)的槽位。
Redis中的字典使用hashtable作為底層實(shí)現(xiàn)的話,每個字典會帶有兩個哈希表,一個平時使用,另一個僅在rehash(重新散列)時使用。隨著對哈希表的操作,鍵會逐漸增多或減少。為了讓哈希表的負(fù)載因子維持在一個合理范圍內(nèi),Redis會對哈希表的大小進(jìn)行擴(kuò)展或收縮(rehash),也就是將ht【0】里面所有的鍵值對分多次、漸進(jìn)式的rehash到ht【1】里。
六、Set
Set集合對象的底層實(shí)現(xiàn)可以是intset(整數(shù)集合)或者h(yuǎn)ashtable(字典或者也叫哈希表)。
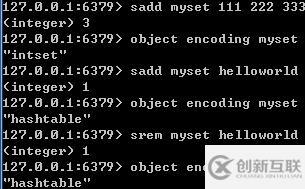
intset(整數(shù)集合)當(dāng)一個集合只含有整數(shù),并且元素不多時會使用intset(整數(shù)集合)作為Set集合對象的底層實(shí)現(xiàn)。
typedef struct intset { // 編碼方式 uint32_t encoding; // 集合包含的元素數(shù)量 uint32_t length; // 保存元素的數(shù)組 int8_t contents[]; } intset;sadd:intsetAdd---O(1)
smembers:intsetGetO(1)---O(N)
srem:intsetRemove---O(N)
slen:intsetlen ---O(1)
intset底層實(shí)現(xiàn)為有序,無重復(fù)數(shù)組保存集合元素。 intset這個結(jié)構(gòu)里的整數(shù)數(shù)組的類型可以是16位的,32位的,64位的。如果數(shù)組里所有的整數(shù)都是16位長度的,如果新加入一個32位的整數(shù),那么整個16的數(shù)組將升級成一個32位的數(shù)組。升級可以提升intset的靈活性,又可以節(jié)約內(nèi)存,但不可逆。
7.ZSet
ZSet有序集合對象底層實(shí)現(xiàn)可以是ziplist(壓縮列表)或者skiplist(跳躍表)。
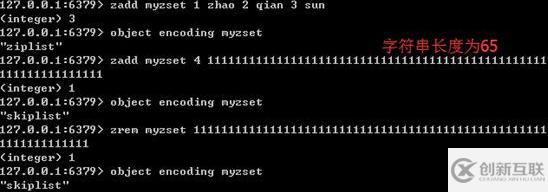
當(dāng)一個有序集合的元素數(shù)量比較多或者成員是比較長的字符串時,Redis就使用skiplist(跳躍表)作為ZSet對象的底層實(shí)現(xiàn)。
typedef struct zskiplist { // 表頭節(jié)點(diǎn)和表尾節(jié)點(diǎn) struct zskiplistNode *header, *tail; // 表中節(jié)點(diǎn)的數(shù)量 unsigned long length; // 表中層數(shù)***的節(jié)點(diǎn)的層數(shù) int level; } zskiplist; typedef struct zskiplistNode { // 成員對象 robj *obj; // 分值 double score; // 后退指針 struct zskiplistNode *backward; // 層 struct zskiplistLevel { // 前進(jìn)指針 struct zskiplistNode *forward; // 跨度---前進(jìn)指針?biāo)赶蚬?jié)點(diǎn)與當(dāng)前節(jié)點(diǎn)的距離 unsigned int span; } level[]; } zskiplistNode;zadd---zslinsert---平均O(logN), 最壞O(N)
zrem---zsldelete---平均O(logN), 最壞O(N)
zrank--zslGetRank---平均O(logN), 最壞O(N)
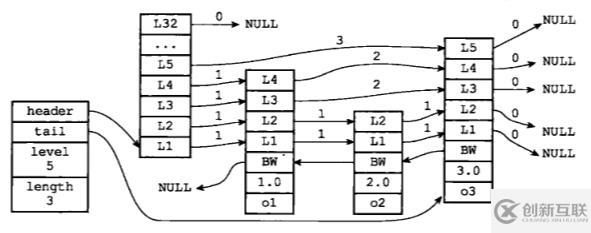
skiplist的查找時間復(fù)雜度是LogN,可以和平衡二叉樹相當(dāng),但實(shí)現(xiàn)起來又比它簡單。跳躍表(skiplist)是一種有序數(shù)據(jù)結(jié)構(gòu),它通過在某個節(jié)點(diǎn)中維持多個指向其他節(jié)點(diǎn)的指針,從而達(dá)到快速訪問節(jié)點(diǎn)的目的。
看完上述內(nèi)容是否對您有幫助呢?如果還想對相關(guān)知識有進(jìn)一步的了解或閱讀更多相關(guān)文章,請關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道,感謝您對創(chuàng)新互聯(lián)的支持。
名稱欄目:如何從數(shù)據(jù)存儲角度分析Redis為何這么快
文章位置:http://chinadenli.net/article22/jigsjc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供做網(wǎng)站、微信小程序、響應(yīng)式網(wǎng)站、網(wǎng)頁設(shè)計公司、網(wǎng)站建設(shè)、云服務(wù)器
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 優(yōu)化效果不理想?四個搜索引擎優(yōu)化的小技巧! 2016-08-20
- 視頻類搜索引擎優(yōu)化的重點(diǎn)是什么? 2016-01-21
- 搜索引擎優(yōu)化對于初學(xué)者的提示 2016-11-16
- 北京網(wǎng)站優(yōu)化公司 搜索引擎優(yōu)化解決方案 2021-04-15
- 營銷型網(wǎng)站符合搜索引擎優(yōu)化主要體現(xiàn)哪些方面 2022-08-13
- 搜索引擎優(yōu)化思維的重要性 2022-09-28
- 我們應(yīng)如何解決網(wǎng)站搜索引擎優(yōu)化排名和收錄問題? 2016-11-13
- 成都網(wǎng)站標(biāo)題在搜索引擎優(yōu)化中的作用 2017-01-15
- 搜索引擎優(yōu)化培訓(xùn):優(yōu)秀的寧德seo往往付出被別人更多 2023-04-06
- 搜索引擎優(yōu)化外貿(mào)網(wǎng)站營銷外包 2022-12-11
- 為搜索引擎優(yōu)化必備的方法之一:怎么做偽原創(chuàng)文章 2022-06-27
- 網(wǎng)站建設(shè)工作完成后做搜索引擎優(yōu)化的重要性 2020-03-06