selenium怎么解決python爬蟲亂碼問題-創(chuàng)新互聯(lián)
這篇文章主要介紹了selenium怎么解決python爬蟲亂碼問題,具有一定借鑒價值,需要的朋友可以參考下。希望大家閱讀完這篇文章后大有收獲。下面讓小編帶著大家一起了解一下。
在用requests庫對博客進行爬取時,發(fā)現(xiàn)亂碼報錯,如下圖所示:
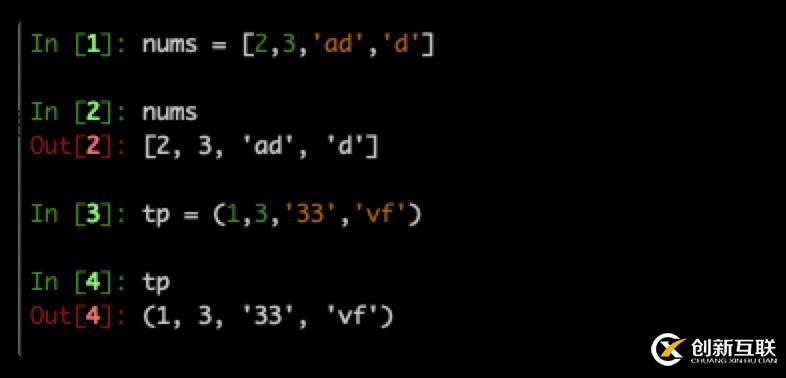
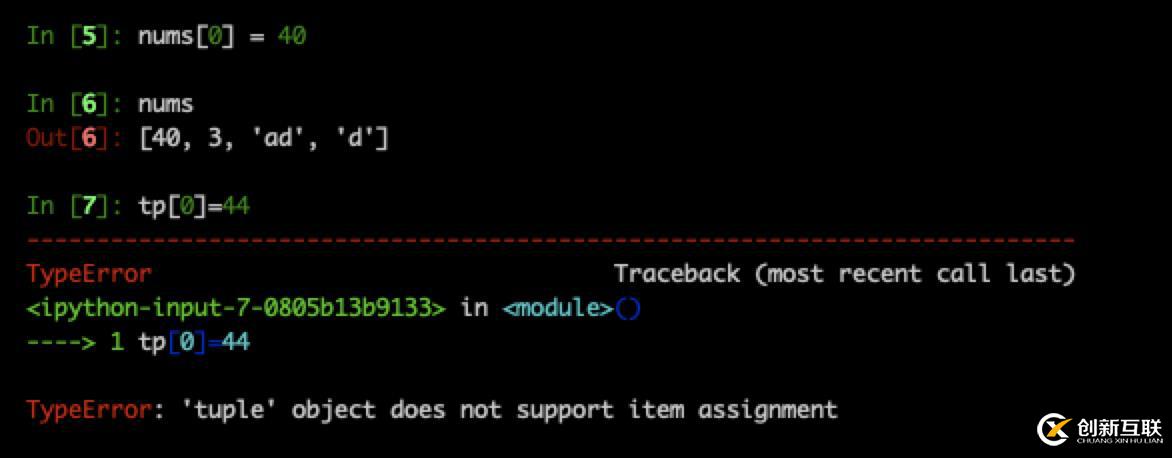
網(wǎng)上查找了一些方法,以為是遇到了網(wǎng)站加密處理。后來發(fā)現(xiàn) 通過F12還 是能獲取網(wǎng)頁的元素,那么有什么辦法能規(guī)避亂碼問題呢?答案是:用selenium.
效果如下
代碼
# coding=utf-8
# @Auther : "鵬哥賊優(yōu)秀"
# @Date : 2019/10/16
# @Software : PyCharm
from selenium import webdriver
url = 'https://blog.csdn.net/yuzipeng'
driver = webdriver.Chrome("F:\\Python成長之路\\chromedriver.exe")
driver.get(url)
urls = driver.find_elements_by_xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
blogurl = ['https://blog.csdn.net/yuzipeng/article/details/' + url.get_attribute('data-articleid') for url in urls]
titles = driver.find_elements_by_xpath('//div[@class="article-item-box csdn-tracking-statistics"]/h5/a')
blogtitle = [title.text for title in titles]
myblog = {k:v for k,v in zip(blogtitle,blogurl)}
for k,v in myblog.items():
print(k,v)
driver.close()感謝你能夠認真閱讀完這篇文章,希望小編分享selenium怎么解決python爬蟲亂碼問題內(nèi)容對大家有幫助,同時也希望大家多多支持創(chuàng)新互聯(lián)網(wǎng)站建設(shè)公司,,關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道,遇到問題就找創(chuàng)新互聯(lián)網(wǎng)站建設(shè)公司,,詳細的解決方法等著你來學(xué)習(xí)!
分享名稱:selenium怎么解決python爬蟲亂碼問題-創(chuàng)新互聯(lián)
路徑分享:http://chinadenli.net/article22/edcjc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站設(shè)計公司、網(wǎng)站營銷、App開發(fā)、用戶體驗、定制開發(fā)、服務(wù)器托管
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 網(wǎng)站收錄量與索引量不一樣的原因 2013-05-18
- 成都網(wǎng)站優(yōu)化:網(wǎng)站有收錄卻沒有排名 2016-04-02
- 讓網(wǎng)站頁面快速收錄的方法? 2014-10-25
- 網(wǎng)站收錄多少才合適?如何提高網(wǎng)站收錄 2016-08-22
- SEO優(yōu)化加快網(wǎng)站收錄的秘訣方法 2023-04-14
- 新站要想網(wǎng)站收錄好 網(wǎng)站制作時的網(wǎng)站結(jié)構(gòu)很重要 2016-11-04
- 網(wǎng)站SEO優(yōu)化:新網(wǎng)站如何快速被百度收錄? 2014-08-04
- 導(dǎo)致網(wǎng)站收錄異常的因素有哪些 2014-11-29
- 如何提高網(wǎng)站收錄和排名 2013-09-15
- 新營銷網(wǎng)站收錄不穩(wěn)定現(xiàn)象正常嗎 2016-09-24
- SEO優(yōu)化之如何提升網(wǎng)站收錄量 2015-02-08
- 如何讓新站快速被百度收錄? 2014-04-12