python網(wǎng)絡(luò)爬蟲的流程步驟-創(chuàng)新互聯(lián)
本文將為大家詳細介紹“python網(wǎng)絡(luò)爬蟲的流程步驟”,內(nèi)容步驟清晰詳細,細節(jié)處理妥當,而小編每天都會更新不同的知識點,希望這篇“python網(wǎng)絡(luò)爬蟲的流程步驟”能夠給你意想不到的收獲,請大家跟著小編的思路慢慢深入,具體內(nèi)容如下,一起去收獲新知識吧。
為思禮等地區(qū)用戶提供了全套網(wǎng)頁設(shè)計制作服務(wù),及思禮網(wǎng)站建設(shè)行業(yè)解決方案。主營業(yè)務(wù)為成都網(wǎng)站制作、成都做網(wǎng)站、思禮網(wǎng)站設(shè)計,以傳統(tǒng)方式定制建設(shè)網(wǎng)站,并提供域名空間備案等一條龍服務(wù),秉承以專業(yè)、用心的態(tài)度為用戶提供真誠的服務(wù)。我們深信只要達到每一位用戶的要求,就會得到認可,從而選擇與我們長期合作。這樣,我們也可以走得更遠!python網(wǎng)絡(luò)爬蟲步驟:首先準備所需庫,編寫爬蟲調(diào)度程序;然后編寫url管理器,并編寫網(wǎng)頁下載器;接著編寫網(wǎng)頁解析器;最后編寫網(wǎng)頁輸出器即可。
python網(wǎng)絡(luò)爬蟲步驟
(1)準備所需庫
我們需要準備一款名為BeautifulSoup(網(wǎng)頁解析)的開源庫,用于對下載的網(wǎng)頁進行解析,我們是用的是PyCharm編譯環(huán)境所以可以直接下載該開源庫。
步驟如下:
選擇File->Settings
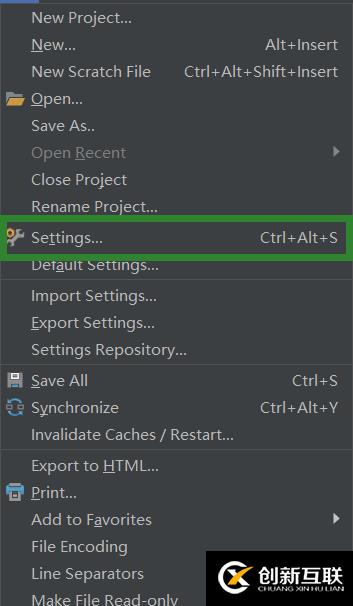
打開Project:PythonProject下的Project interpreter
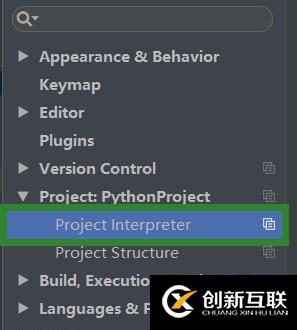
點擊加號添加新的庫
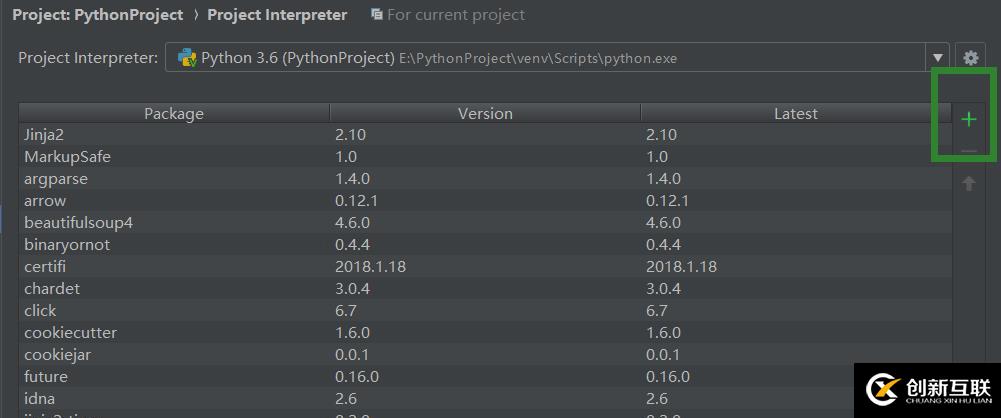
輸入bs4選擇bs4點擊Install Packge進行下載
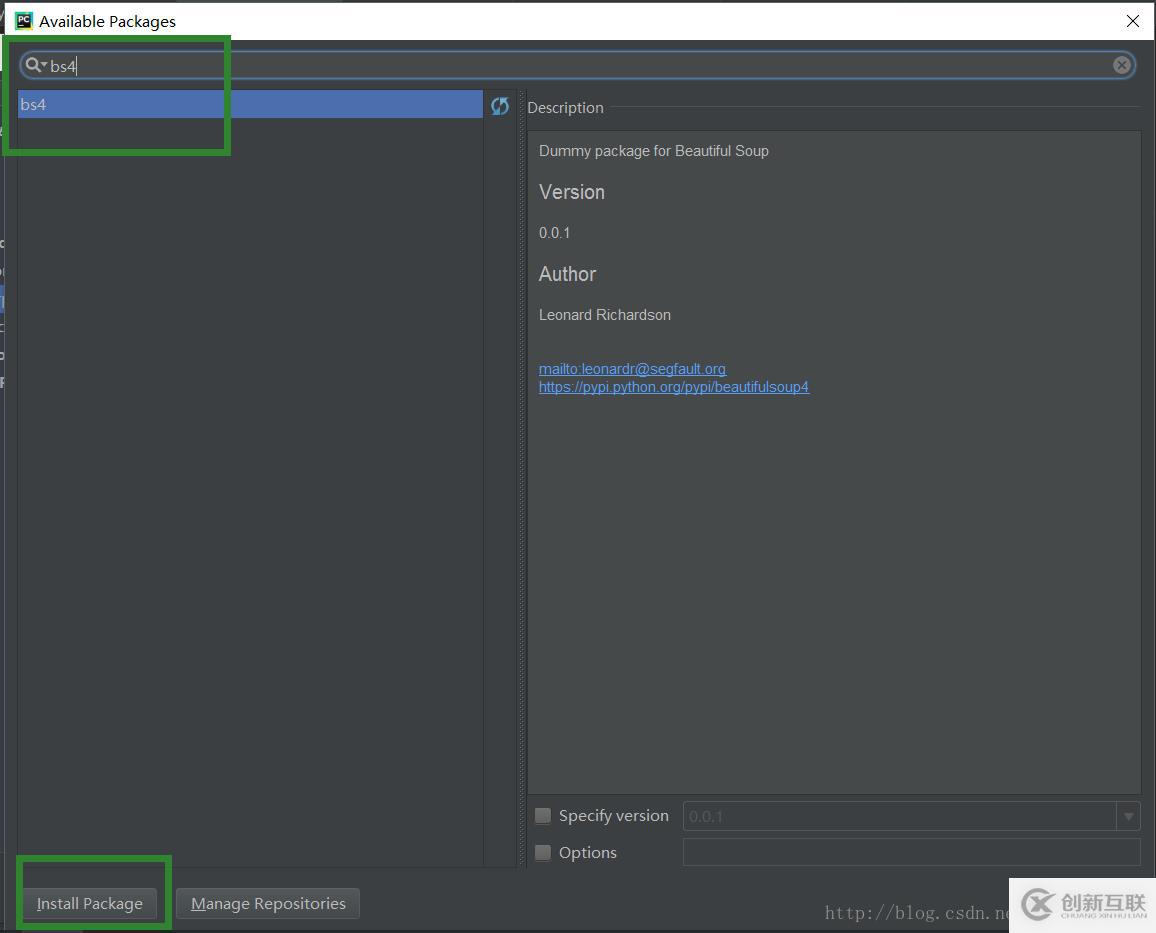
(2)編寫爬蟲調(diào)度程序
這里的bike_spider是項目名稱引入的四個類分別對應(yīng)下面的四段代碼url管理器,url下載器,url解析器,url輸出器。
# 爬蟲調(diào)度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬蟲初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下載網(wǎng)頁
html_cont = self.downloader.download(new_url)
# 解析網(wǎng)頁
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 網(wǎng)頁輸出器收集數(shù)據(jù)
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)(3)編寫url管理器
我們把已經(jīng)爬取過的url和未爬取的url分開存放以便我們不會重復(fù)爬取某些已經(jīng)爬取過的網(wǎng)頁。
# url管理器 class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: self.new_urls.add(url) def get_new_url(self): # pop方法會幫我們獲取一個url并且移除它 new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url def has_new_url(self): return len(self.new_urls) != 0
(4)編寫網(wǎng)頁下載器
通過網(wǎng)絡(luò)請求來下載頁面
# 網(wǎng)頁下載器 import urllib.request class HtmlDownloader(object): def download(self, url): if url is None: return None response = urllib.request.urlopen(url) # code不為200則請求失敗 if response.getcode() != 200: return None return response.read()
(5)編寫網(wǎng)頁解析器
對網(wǎng)頁進行解析時我們需要知道我們要查詢的內(nèi)容都有哪些特征,我們可以打開一個網(wǎng)頁點擊右鍵審查元素來了解我們所查內(nèi)容的共同之處。
# 網(wǎng)頁解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 獲取標題
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h2")
res_data["title"] = title_node.get_text()
summary_node = soup.find("p", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列條件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 獲取到的url不完整,學要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls(6)編寫網(wǎng)頁輸出器
輸出的格式有很多種,我們選擇以html的形式輸出,這樣我們可以的到一個html頁面。
# 網(wǎng)頁輸出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我們以html表格形式進行輸出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("<html>")
fout.write("<meta charset='utf-8'>")
fout.write("<body>")
# 以表格輸出
fout.write("<table>")
for data in self.datas:
# 一行
fout.write("<tr>")
# 每個單元行的內(nèi)容
fout.write("<td>%s</td>" % data["url"])
fout.write("<td>%s</td>" % data["title"])
fout.write("<td>%s</td>" % data["summary"])
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
# 輸出完畢后一定要關(guān)閉輸出器
fout.close()如果你能讀到這里,小編希望你對“python網(wǎng)絡(luò)爬蟲的流程步驟”這一關(guān)鍵問題有了從實踐層面最深刻的體會,具體使用情況還需要大家自己動手實踐使用過才能領(lǐng)會,如果想閱讀更多相關(guān)內(nèi)容的文章,歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道!
文章標題:python網(wǎng)絡(luò)爬蟲的流程步驟-創(chuàng)新互聯(lián)
當前地址:http://chinadenli.net/article22/coggcc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供App設(shè)計、移動網(wǎng)站建設(shè)、企業(yè)網(wǎng)站制作、動態(tài)網(wǎng)站、網(wǎng)頁設(shè)計公司、軟件開發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- C#forUnity快速入門(連載5)-C#OOP編程之封裝性-創(chuàng)新互聯(lián)
- pdfbox開發(fā)文檔pdf怎么創(chuàng)建表格PDF文檔添加表格數(shù)據(jù)方法?-創(chuàng)新互聯(lián)
- WIN10下java8的開發(fā)環(huán)境配置-創(chuàng)新互聯(lián)
- HTML表單-創(chuàng)新互聯(lián)
- C語言實現(xiàn)簡單計算器功能的示例-創(chuàng)新互聯(lián)
- bootstrap-為水平排列的表單和內(nèi)聯(lián)表單設(shè)置可選的圖標-創(chuàng)新互聯(lián)
- Python中寫入訓練日志文件并控制臺輸出的示例分析-創(chuàng)新互聯(lián)

- 移動網(wǎng)站建設(shè)容易進入的誤區(qū) 2021-12-10
- 移動網(wǎng)站建設(shè)需要注意修補這些漏洞 2022-10-29
- 移動網(wǎng)站建設(shè)需要考慮哪些問題? 2016-01-07
- 東莞移動網(wǎng)站建設(shè):建設(shè)一個手機網(wǎng)站有哪些優(yōu)勢? 2021-09-19
- 移動網(wǎng)站建設(shè)時要注意視覺的設(shè)計及優(yōu)化 2016-10-05
- 移動網(wǎng)站建設(shè)時這些問題千萬不能出現(xiàn)! 2021-04-28
- 一線品牌企業(yè)全站高端網(wǎng)站設(shè)計哪家好? 2022-06-14
- 成都移動網(wǎng)站建設(shè)注意事項有哪些? 2020-08-18
- 深圳寶安移動網(wǎng)站建設(shè)長滾動頁面的優(yōu)勢是什么 2021-12-02
- 移動網(wǎng)站建設(shè)與搜索引擎的關(guān)系 2023-03-27
- 移動網(wǎng)站建設(shè)需要注意的問題 2014-10-25
- 移動網(wǎng)站建設(shè)是未來的一個大好市場 2020-11-07