如何在Pycharm中安裝Scrapy-創(chuàng)新互聯(lián)
這期內(nèi)容當中小編將會給大家?guī)碛嘘P(guān)如何在Pycharm中安裝Scrapy,文章內(nèi)容豐富且以專業(yè)的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。

Scrapy是一個開源的網(wǎng)絡(luò)爬蟲框架,Python編寫的。最初設(shè)計用于網(wǎng)頁抓取,也可以用來提取數(shù)據(jù)使用API或作為一個通用的網(wǎng)絡(luò)爬蟲。是數(shù)據(jù)采集不可必備的利器。
安裝
pip install scrapy
如果使用上面的命令太慢。國內(nèi)可以使用豆瓣源進行加速。
pip install -i https://pypi.douban.com/simple scrapy
注意要寫錯了,是 https://pypi.douban.com/simple 很多包都可以使用這個源進行加速,這也是pip的一個技巧,還可以使用阿里云進行加速。
安裝完成之后在命令行輸入
scrapy -v
如果出現(xiàn)了相應(yīng)的版本號就說明安裝成功。
創(chuàng)建項目
目前還沒有IDE 能夠創(chuàng)建scrapy的項目,我們必須手動初始化項目。
1、找一個目錄
輸入命令
scrapy startproject SpiderObject
命令行出現(xiàn)這樣的結(jié)果說明創(chuàng)建成果
You can start your first spider with: cd SpiderObject scrapy genspider example example.com
去文件夾中看看

初始化項目
使用pycharm打開該項目

如果出現(xiàn)這個頁面就說明對了。

下面生成一個模板
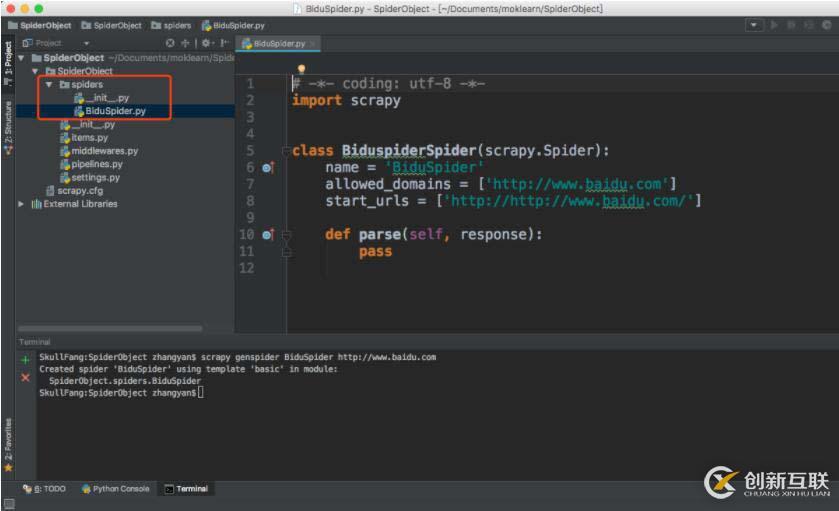
打開pycharm的terminal

輸入
scrapy genspider BiduSpider http://www.baidu.com
我們的spider 包下面會多一個文件
上述就是小編為大家分享的如何在Pycharm中安裝Scrapy了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關(guān)知識,歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道。
本文標題:如何在Pycharm中安裝Scrapy-創(chuàng)新互聯(lián)
當前鏈接:http://chinadenli.net/article20/hhpco.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供服務(wù)器托管、品牌網(wǎng)站建設(shè)、關(guān)鍵詞優(yōu)化、網(wǎng)站改版、面包屑導(dǎo)航、用戶體驗
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 網(wǎng)站內(nèi)鏈建設(shè)注意事項以及網(wǎng)站外鏈建設(shè)注意事項 2022-05-02
- 成都網(wǎng)站內(nèi)鏈優(yōu)化有哪些重要方式? 2023-04-24
- 網(wǎng)站內(nèi)鏈你真的會做嗎 2016-11-02
- 成都關(guān)鍵詞排名:網(wǎng)站內(nèi)鏈優(yōu)化 2016-11-13
- SEO之網(wǎng)站內(nèi)鏈的重要性! 2022-11-07
- 正確建設(shè)網(wǎng)站內(nèi)鏈的5個方法 2022-05-22
- 創(chuàng)新互聯(lián):如何建立優(yōu)質(zhì)的網(wǎng)站內(nèi)鏈結(jié)構(gòu)? 2014-02-08
- 【網(wǎng)絡(luò)推廣】如何構(gòu)建網(wǎng)站內(nèi)鏈, 有利于SEO排名? 2016-11-07
- 如何使用nofollow優(yōu)化網(wǎng)站內(nèi)鏈? 2015-07-29
- 網(wǎng)站內(nèi)鏈建設(shè)切勿泛濫 2021-07-20
- 關(guān)于網(wǎng)站內(nèi)鏈布局的事情 2016-05-03
- 【SEO優(yōu)化】SEO優(yōu)化中網(wǎng)站內(nèi)鏈布局的作用 2022-01-20