Python如何實(shí)現(xiàn)樸素貝葉斯-創(chuàng)新互聯(lián)
這篇文章將為大家詳細(xì)講解有關(guān)Python如何實(shí)現(xiàn)樸素貝葉斯,小編覺(jué)得挺實(shí)用的,因此分享給大家做個(gè)參考,希望大家閱讀完這篇文章后可以有所收獲。
概念簡(jiǎn)介:
樸素貝葉斯基于貝葉斯定理,它假設(shè)輸入隨機(jī)變量的特征值是條件獨(dú)立的,故稱之為“樸素”。簡(jiǎn)單介紹貝葉斯定理:
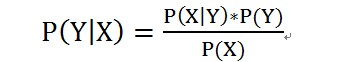
乍看起來(lái)似乎是要求一個(gè)概率,還要先得到額外三個(gè)概率,有用么?其實(shí)這個(gè)簡(jiǎn)單的公式非常貼切人類推理的邏輯,即通過(guò)可以觀測(cè)的數(shù)據(jù),推測(cè)不可觀測(cè)的數(shù)據(jù)。舉個(gè)例子,也許你在辦公室內(nèi)不知道外面天氣是晴天雨天,但是你觀測(cè)到有同事帶了雨傘,那么可以推斷外面八成在下雨。
若X 是要輸入的隨機(jī)變量,則Y 是要輸出的目標(biāo)類別。對(duì)X 進(jìn)行分類,即使求的使P(Y|X) 大的Y值。若X 為n 維特征變量 X = {A1, A2, …..An} ,若輸出類別集合為Y = {C1, C2, …. Cm} 。
X 所屬最有可能類別 y = argmax P(Y|X), 進(jìn)行如下推導(dǎo):
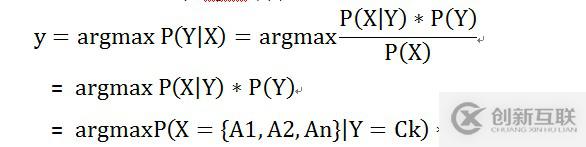
樸素貝葉斯的學(xué)習(xí)
有公式可知,欲求分類結(jié)果,須知如下變量:
各個(gè)類別的條件概率,
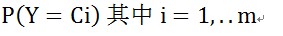
輸入隨機(jī)變量的特質(zhì)值的條件概率
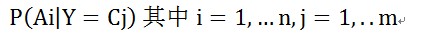
示例代碼:
import copy
class native_bayes_t:
def __init__(self, character_vec_, class_vec_):
"""
構(gòu)造的時(shí)候需要傳入特征向量的值,以數(shù)組方式傳入
參數(shù)1 character_vec_ 格式為 [("character_name",["","",""])]
參數(shù)2 為包含所有類別的數(shù)組 格式為["class_X", "class_Y"]
"""
self.class_set = {}
# 記錄該類別下各個(gè)特征值的條件概率
character_condition_per = {}
for character_name in character_vec_:
character_condition_per[character_name[0]] = {}
for character_value in character_name[1]:
character_condition_per[character_name[0]][character_value] = {
'num' : 0, # 記錄該類別下該特征值在訓(xùn)練樣本中的數(shù)量,
'condition_per' : 0.0 # 記錄該類別下各個(gè)特征值的條件概率
}
for class_name in class_vec:
self.class_set[class_name] = {
'num' : 0, # 記錄該類別在訓(xùn)練樣本中的數(shù)量,
'class_per' : 0.0, # 記錄該類別在訓(xùn)練樣本中的先驗(yàn)概率,
'character_condition_per' : copy.deepcopy(character_condition_per),
}
#print("init", character_vec_, self.class_set) #for debug
def learn(self, sample_):
"""
learn 參數(shù)為訓(xùn)練的樣本,格式為
[
{
'character' : {'character_A':'A1'}, #特征向量
'class_name' : 'class_X' #類別名稱
}
]
"""
for each_sample in sample:
character_vec = each_sample['character']
class_name = each_sample['class_name']
data_for_class = self.class_set[class_name]
data_for_class['num'] += 1
# 各個(gè)特質(zhì)值數(shù)量加1
for character_name in character_vec:
character_value = character_vec[character_name]
data_for_character = data_for_class['character_condition_per'][character_name][character_value]
data_for_character['num'] += 1
# 數(shù)量計(jì)算完畢, 計(jì)算最終的概率值
sample_num = len(sample)
for each_sample in sample:
character_vec = each_sample['character']
class_name = each_sample['class_name']
data_for_class = self.class_set[class_name]
# 計(jì)算類別的先驗(yàn)概率
data_for_class['class_per'] = float(data_for_class['num']) / sample_num
# 各個(gè)特質(zhì)值的條件概率
for character_name in character_vec:
character_value = character_vec[character_name]
data_for_character = data_for_class['character_condition_per'][character_name][character_value]
data_for_character['condition_per'] = float(data_for_character['num']) / data_for_class['num']
from pprint import pprint
pprint(self.class_set) #for debug
def classify(self, input_):
"""
對(duì)輸入進(jìn)行分類,輸入input的格式為
{
"character_A":"A1",
"character_B":"B3",
}
"""
best_class = ''
max_per = 0.0
for class_name in self.class_set:
class_data = self.class_set[class_name]
per = class_data['class_per']
# 計(jì)算各個(gè)特征值條件概率的乘積
for character_name in input_:
character_per_data = class_data['character_condition_per'][character_name]
per = per * character_per_data[input_[character_name]]['condition_per']
print(class_name, per)
if per >= max_per:
best_class = class_name
return best_class
character_vec = [("character_A",["A1","A2","A3"]), ("character_B",["B1","B2","B3"])]
class_vec = ["class_X", "class_Y"]
bayes = native_bayes_t(character_vec, class_vec)
sample = [
{
'character' : {'character_A':'A1', 'character_B':'B1'}, #特征向量
'class_name' : 'class_X' #類別名稱
},
{
'character' : {'character_A':'A3', 'character_B':'B1'}, #特征向量
'class_name' : 'class_X' #類別名稱
},
{
'character' : {'character_A':'A3', 'character_B':'B3'}, #特征向量
'class_name' : 'class_X' #類別名稱
},
{
'character' : {'character_A':'A2', 'character_B':'B2'}, #特征向量
'class_name' : 'class_X' #類別名稱
},
{
'character' : {'character_A':'A2', 'character_B':'B2'}, #特征向量
'class_name' : 'class_Y' #類別名稱
},
{
'character' : {'character_A':'A3', 'character_B':'B1'}, #特征向量
'class_name' : 'class_Y' #類別名稱
},
{
'character' : {'character_A':'A1', 'character_B':'B3'}, #特征向量
'class_name' : 'class_Y' #類別名稱
},
{
'character' : {'character_A':'A1', 'character_B':'B3'}, #特征向量
'class_name' : 'class_Y' #類別名稱
},
]
input_data ={
"character_A":"A1",
"character_B":"B3",
}
bayes.learn(sample)
print(bayes.classify(input_data))關(guān)于“Python如何實(shí)現(xiàn)樸素貝葉斯”這篇文章就分享到這里了,希望以上內(nèi)容可以對(duì)大家有一定的幫助,使各位可以學(xué)到更多知識(shí),如果覺(jué)得文章不錯(cuò),請(qǐng)把它分享出去讓更多的人看到。
另外有需要云服務(wù)器可以了解下創(chuàng)新互聯(lián)scvps.cn,海內(nèi)外云服務(wù)器15元起步,三天無(wú)理由+7*72小時(shí)售后在線,公司持有idc許可證,提供“云服務(wù)器、裸金屬服務(wù)器、高防服務(wù)器、香港服務(wù)器、美國(guó)服務(wù)器、虛擬主機(jī)、免備案服務(wù)器”等云主機(jī)租用服務(wù)以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡(jiǎn)單易用、服務(wù)可用性高、性價(jià)比高”等特點(diǎn)與優(yōu)勢(shì),專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應(yīng)用場(chǎng)景需求。
分享標(biāo)題:Python如何實(shí)現(xiàn)樸素貝葉斯-創(chuàng)新互聯(lián)
URL標(biāo)題:http://chinadenli.net/article20/ehjjo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站制作、服務(wù)器托管、定制網(wǎng)站、企業(yè)網(wǎng)站制作、品牌網(wǎng)站建設(shè)、面包屑導(dǎo)航
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 編譯原理筆記03-創(chuàng)新互聯(lián)
- webstorm中使用H5快捷鍵的注意事項(xiàng)有哪些-創(chuàng)新互聯(lián)
- 2022年第十三屆藍(lán)橋杯省賽--難度評(píng)價(jià)-創(chuàng)新互聯(lián)
- Mongodb中使用B樹(shù)索引的原因是什么-創(chuàng)新互聯(lián)
- python中怎么用JS加載加快爬蟲(chóng)獲取-創(chuàng)新互聯(lián)
- php將某一模板內(nèi)容解析過(guò)后,并獲取其返回值-創(chuàng)新互聯(lián)
- 實(shí)時(shí)同步工具原理解釋及環(huán)境準(zhǔn)備inotify-創(chuàng)新互聯(lián)

- 網(wǎng)站的結(jié)構(gòu)對(duì)網(wǎng)站排名有何價(jià)值? 2020-07-26
- 分析Alexa網(wǎng)站排名,排名分類 2013-08-20
- 為什么說(shuō)網(wǎng)站排名波動(dòng)是正常的事情? 2014-09-03
- 鄭州微笑seo:外鏈數(shù)量對(duì)網(wǎng)站排名的影響 2022-12-16
- 為什么網(wǎng)站排名好流量?卻很少? 2013-07-30
- 濟(jì)南網(wǎng)站排名區(qū)分內(nèi)容計(jì)策和要害詞排名的干系 2023-02-03
- 菏澤網(wǎng)站排名「外鏈宣布」怎么為一個(gè)網(wǎng)站做更多網(wǎng)站推廣外鏈? 2023-01-23
- 網(wǎng)站建好了如何提高網(wǎng)站排名 2022-09-21
- 企業(yè)網(wǎng)站制作如何提升網(wǎng)站排名 2022-11-11
- 網(wǎng)站軟文的持續(xù)更新可帶動(dòng)網(wǎng)站排名提升 2016-04-28
- 過(guò)年期間提升網(wǎng)站排名的方法 2022-11-26
- SEO的核心思想,讀懂這些網(wǎng)站排名不再艱難 2020-07-26