list數(shù)據(jù)怎么利用pandas拆分成行或列-創(chuàng)新互聯(lián)
本篇文章為大家展示了list數(shù)據(jù)怎么利用pandas拆分成行或列,內(nèi)容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。

數(shù)據(jù)
import numpy as np
import pandas as pd
data = [{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]},
{'Name': '小紅', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]
data = pd.DataFrame(data)
data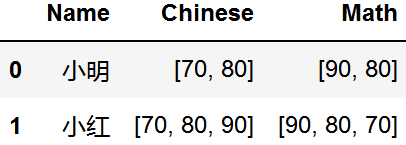
拆分成行
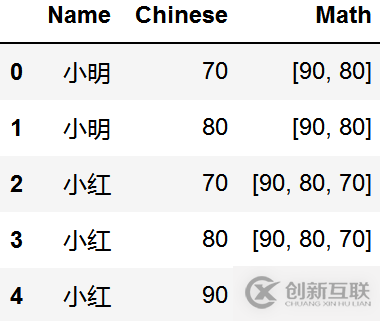
def split_row(data, column): '''拆分成行 :param data: 原始數(shù)據(jù) :param column: 拆分的列名 :type data: pandas.core.frame.DataFrame :type column: str ''' row_len = list(map(len, data[column].values)) rows = [] for i in data.columns: if i == column: row = np.concatenate(data[i].values) else: row = np.repeat(data[i].values, row_len) rows.append(row) return pd.DataFrame(np.dstack(tuple(rows))[0], columns=data.columns) split_row(data, column='Chinese')
拆分成列

from copy import deepcopy def split_col(data, column): '''拆分成列 :param data: 原始數(shù)據(jù) :param column: 拆分的列名 :type data: pandas.core.frame.DataFrame :type column: str ''' data = deepcopy(data) max_len = max(list(map(len, data[column].values))) # 較大長度 new_col = data[column].apply(lambda x: x + [None]*(max_len - len(x))) # 補空值,None可換成np.nan new_col = np.array(new_col.tolist()).T # 轉(zhuǎn)置 for i, j in enumerate(new_col): data[column + str(i)] = j return data split_col(data, column='Chinese')
其他情況
1. 批量處理+不要原列
def split_col(data, columns): '''拆分成列 :param data: 原始數(shù)據(jù) :param columns: 拆分的列名 :type data: pandas.core.frame.DataFrame :type columns: list ''' for c in columns: new_col = data.pop(c) max_len = max(list(map(len, new_col.values))) # 較大長度 new_col = new_col.apply(lambda x: x + [None]*(max_len - len(x))) # 補空值,None可換成np.nan new_col = np.array(new_col.tolist()).T # 轉(zhuǎn)置 for i, j in enumerate(new_col): data[c + str(i)] = j split_col(data, columns=['Chinese','Math']) data
2. 帶int和list數(shù)據(jù)
轉(zhuǎn)成這樣:
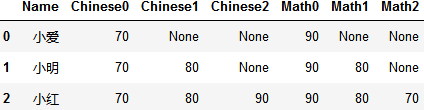
import numpy as np
import pandas as pd
data = [{'Name': '小愛', 'Chinese': 70, 'Math': 90},
{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]},
{'Name': '小紅', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}]
data = pd.DataFrame(data)
def split_col(data, columns):
'''拆分成列
:param data: 原始數(shù)據(jù)
:param columns: 拆分的列名
:type data: pandas.core.frame.DataFrame
:type columns: list
'''
for c in columns:
new_col = data.pop(c)
max_len = max(list(map(lambda x:len(x) if isinstance(x, list) else 1, new_col.values))) # 較大長度
new_col = new_col.apply(lambda x: x+[None]*(max_len - len(x)) if isinstance(x, list) else [x]+[None]*(max_len - 1)) # 補空值,None可換成np.nan
new_col = np.array(new_col.tolist()).T # 轉(zhuǎn)置
for i, j in enumerate(new_col):
data[c + str(i)] = j
split_col(data, columns=['Chinese','Math'])
data上述內(nèi)容就是list數(shù)據(jù)怎么利用pandas拆分成行或列,你們學(xué)到知識或技能了嗎?如果還想學(xué)到更多技能或者豐富自己的知識儲備,歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道。
文章題目:list數(shù)據(jù)怎么利用pandas拆分成行或列-創(chuàng)新互聯(lián)
瀏覽地址:http://chinadenli.net/article2/dpppic.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供自適應(yīng)網(wǎng)站、虛擬主機、做網(wǎng)站、定制開發(fā)、外貿(mào)建站、Google
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容

- 新站收錄很好但是沒有排名是什么原因?怎么解決? 2016-08-22
- 【SEO優(yōu)化】網(wǎng)站收錄狂掉的原因是什么?有什么解決方法? 2022-04-19
- 為什么你的網(wǎng)站不被搜索引擎收錄? 2016-09-14
- 想要提升網(wǎng)站收錄率,這么做才對! 2013-10-17
- 成都SEO收錄與索引傻傻分不清 2016-10-28
- 網(wǎng)站有收錄卻沒排名如何解決? 2015-12-26
- seo優(yōu)化人員怎樣對待網(wǎng)站的收錄問題呢? 2015-02-11
- 網(wǎng)站內(nèi)容不收錄?這幾點了解一下! 2013-08-05
- SEO優(yōu)化公司:網(wǎng)站被收錄的方法是什么 2016-11-14
- 提高網(wǎng)站文章收錄率要怎么做? 2016-12-19
- 提高網(wǎng)站收錄方法有哪些? 2014-07-02
- 成都網(wǎng)站優(yōu)化:收錄量和外鏈到底是哪個重要? 2016-10-31