hive的基礎理論-創(chuàng)新互聯(lián)
1. hive的介紹
什么是hive:Hive是基于hadoop的一個數(shù)據(jù)倉庫工具,實質就是一款基于hdfs的MapReduce計算框架,對存儲在HDFS中的數(shù)據(jù)進行分析和管理。
hive的工作方式:把存放在hive中的數(shù)據(jù)都抽象成一張二維表格,提供了一個類似于sql語句的操作方式,這些sql語句最終被hive的底層翻譯成為MapReduce程序,最終在hadoop集群上運行,結果也會輸出在hdfs之中。(必須是結構化的數(shù)據(jù))。在存儲的時候hive對數(shù)據(jù)不做校驗,在讀取的時候校驗。
hive的的優(yōu)點:極大的簡化了分布式的計算程序的編程。使不會分布式編程的,其他工作人員都可以進行海量數(shù)據(jù)的統(tǒng)計分析。
hive的的缺點:不支持行級別的增刪改操作、hive的查詢延遲很嚴重、hive中不支持事務,主要用于做OLAP(聯(lián)機分析處理)。
hive的的適用場景:hive數(shù)據(jù)倉庫中的數(shù)據(jù),主要是存儲,在進行ETL(數(shù)據(jù)清洗、抽取、轉換、裝載)操作之后的具有結構化的數(shù)據(jù)。但是數(shù)據(jù)的存儲的格式?jīng)]有特殊要求,可以使普通文件,也可以是溢寫壓縮文件等等。
hive的的與關系型數(shù)據(jù)庫的對比: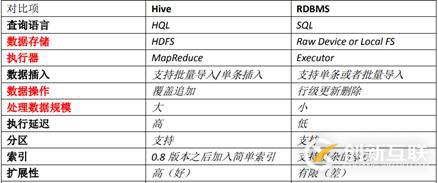

2. hive的架構

hive的架構中有四個部分組成:
用戶接口:
- CLI(command line interface),shell終端命令行,采用交互式使用hive命令行與hive進行交互,最常用(學習、生成、調(diào)試)
- Jdbc/odbc:是hive的基于jdbc操作提供的客戶端,用戶(開發(fā)、運維)通過這個鏈接hive server服務
- Web UI:通過瀏覽器訪問hive(基本不用)
Thrift Server:Thrift是facebook開發(fā)的一個軟件框架,可以用來進行可擴展且跨語言的服務的開發(fā),hive集成了該服務,能讓不同的編程語言調(diào)用hive的接口。
底層四大組件:底層的四大組件完成hql查詢語句從詞法分析,語法分析,編譯,優(yōu)化,以及生成邏輯執(zhí)行計劃的生成。生成的邏輯執(zhí)行計劃存儲在hdfs中,并隨后由MapReduce調(diào)用執(zhí)行。
- 解釋器:解釋器的作用是將hiveSQL語句轉換成抽象語法數(shù)
- 編譯器:編譯器是將語法樹編譯成為邏輯執(zhí)行計劃
- 優(yōu)化器:優(yōu)化器是對邏輯執(zhí)行計劃進行優(yōu)化
- 執(zhí)行器:執(zhí)行時調(diào)用底層的運行框架執(zhí)行邏輯執(zhí)行計劃
執(zhí)行流程就是:hiveQL,通過命令或者客戶端提交,經(jīng)過compiler編譯器,運用metastore中的元數(shù)據(jù)進行類型檢測和語法分析,生成一個邏輯方案,然后通過的優(yōu)化處理,產(chǎn)生一個maptask程序。
元數(shù)據(jù)庫:就是存儲在hive中的數(shù)據(jù)的描述信息,通常包括:表的名字、表的列和分區(qū)以及其屬性、表的屬性(內(nèi)部表和外部表),表的數(shù)據(jù)所在目錄。而hive有兩種元數(shù)據(jù)的存儲方案:
- Metastore默認存儲在自帶的derby數(shù)據(jù)庫中。缺點是:不適合多用戶操作,并且數(shù)據(jù)存儲目錄不固定。數(shù)據(jù)庫跟著hive的進入目錄走,極度不方便管理。
- Hive和mysql之間通過Metastore服務交互(本地或者遠程)
3. hive的數(shù)據(jù)存儲
hive的存儲特點:
- hive中所有的數(shù)據(jù)都存儲在hdfs中,沒有專門的數(shù)據(jù)存儲格式,因為hive是讀模式,可支持TezxtFile、SequenceFile(序列化)RCFile(行列結合)或者自定義格式等
- 只需要在創(chuàng)建表的時候,告訴hive數(shù)據(jù)中的列分隔符和行分隔符,hive就可以解析數(shù)據(jù),默認的列分隔符是:(Ctrl + a 不可見字符: \x01),行分隔符是:(\n 換行符)
hive的存儲結構: hive的存儲結構:數(shù)據(jù)庫、表、視圖、分區(qū)和表數(shù)據(jù)等。數(shù)據(jù)庫、表、視圖、分區(qū)等等都對應hdfs上的一個目錄,表數(shù)據(jù)對應hdfs對應目錄下的文件。
例:
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/student.txt
Hdfs://Hadoop01/user/hive/warehouse:表示hive的數(shù)據(jù)倉庫
Hdfs://Hadoop01/user/hive/warehouse/myhive.db: hive的一個數(shù)據(jù)庫
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student hive中的一個表
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/student.txt 數(shù)據(jù)文件注意:當我們在創(chuàng)建表的時候,首先會在hdfs上的相應的目錄下生成一個文件,同時在hive的元數(shù)據(jù)庫中會為這個新建的表生成一條記錄。
hive具體的存儲結構:
- 數(shù)據(jù)倉庫:在 HDFS 中表現(xiàn)為${hive.metastore.warehouse.dir}目錄下一個文件夾
-表:hive的表分為內(nèi)部表、外部表、分區(qū)表、分桶表,表在hdfs中的表現(xiàn)形式也是目錄,但是不同的表之間的表現(xiàn)形式不同
- 視圖:物化,hive是不會進行物化,相當于給一個sql語句建立了一個快捷方式,保存的是一個視圖中的sql語句。只讀,基于基表創(chuàng)建。
- 數(shù)據(jù)文件 :表中的真實數(shù)據(jù)
4. hive的特特特別重要的要點
1)hive中內(nèi)部表和外部表的區(qū)別
內(nèi)部表:又叫管理表,表的創(chuàng)建,和刪除都由hive自己決定。
外部表:表結構上同內(nèi)部表,但是存儲的數(shù)據(jù)時自己定義的,外部表在刪除的時候只刪除元數(shù)據(jù),原始數(shù)據(jù)時不能刪除的。
內(nèi)部表和外部表的區(qū)別主要體現(xiàn)在兩個方面:
- 刪除:刪除內(nèi)部表,刪除元數(shù)據(jù)和數(shù)據(jù);刪除外部表,刪除元數(shù)據(jù),保留數(shù)據(jù)。
- 使用:如果數(shù)據(jù)的所有處理都在 Hive 中進行,那么傾向于 選擇內(nèi)部表,但是如果 Hive 和其他工具要針對相同的數(shù)據(jù)集進行處理,外部表更合適。使用外部表訪問存儲在hdfs上的數(shù)據(jù),然后通過hive轉化數(shù)據(jù)并存儲到內(nèi)部表中。
2)hive中分桶表和分區(qū)表的區(qū)別
分區(qū)表: 原來的一個大表存儲的時候分成不同的數(shù)據(jù)目錄進行存儲。
如果說是單分區(qū)表,那么在表的目錄下就只有一級子目錄,如果說是多分區(qū)表,那么在表的目錄下有多少分區(qū)就有多少級子目錄。不管是單分區(qū)表,還是多分區(qū)表,在表的目錄下,和非最終分區(qū)目錄下是不能之間存儲數(shù)據(jù)文件的。
例:
單分區(qū)表:
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/p0
多分區(qū)表:
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/p0
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/p1
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/p2
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/p1/p11 分桶表: 原理和hashpartitioner 一樣,將hive中的一張表的數(shù)據(jù)進行歸納分類的時候,歸納分類規(guī)則就是hashpartitioner。(需要指定分桶字段,指定分成多少桶)
bucket:在hdfs中表現(xiàn)為同一個表目錄或者分區(qū)目錄下根據(jù)某個字段的值進行Hash散列之后的多個文件,分桶的表現(xiàn)形式就是一個單獨的文件.
例:
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/age>15
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/age>20
Hdfs://Hadoop01/user/hive/warehouse/myhive.db/student/age>30分區(qū)表和分桶的區(qū)別除了存儲的格式不同外,最主要的是作用:
- 分區(qū)表:細化數(shù)據(jù)管理,縮小mapreduce程序 需要掃描的數(shù)據(jù)量。
- 分桶表:提高join查詢的效率,在一份數(shù)據(jù)會被經(jīng)常用來做連接查詢的時候建立分桶,分桶字段就是連接字段;提高采樣的效率。
另外有需要云服務器可以了解下創(chuàng)新互聯(lián)scvps.cn,海內(nèi)外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務可用性高、性價比高”等特點與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
分享標題:hive的基礎理論-創(chuàng)新互聯(lián)
當前鏈接:http://chinadenli.net/article18/dpppdp.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供移動網(wǎng)站建設、軟件開發(fā)、營銷型網(wǎng)站建設、網(wǎng)站制作、ChatGPT、小程序開發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉載內(nèi)容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 如何正確的使用ComboBox控件-創(chuàng)新互聯(lián)
- 在leopard中使用MacPorts(DarwinPorts)-創(chuàng)新互聯(lián)
- CSS中常用樣式有哪些-創(chuàng)新互聯(lián)
- phpunset對json_encode的影響有哪些-創(chuàng)新互聯(lián)
- Python如何使用TkinterPlace布局管理器-創(chuàng)新互聯(lián)
- PHP下解決Cannotfindmodule(IP-MIB)的問題-創(chuàng)新互聯(lián)
- hadoop框架介紹serverless框架-創(chuàng)新互聯(lián)

- 成都小程序開發(fā)是否會曇花一現(xiàn)? 2022-07-31
- 分析企業(yè)在小程序開發(fā)當中需規(guī)避的幾個問題 2016-10-19
- 小程序開發(fā)了,如何選擇靠譜的服務商 2021-08-28
- 靠譜的微信小程序開發(fā)公司 2021-08-12
- 北京朝陽企業(yè)面對APP和小程序開發(fā)應該選擇那種? 2020-12-07
- 哪些服務適用于小程序? 2014-03-02
- 微信小程序開發(fā)成本大概是多少?小程序如何為企業(yè)或商家盈利? 2022-08-25
- 如何開發(fā)微信小程序?微信小程序開發(fā)文檔包含制作方法和詳細步驟 2022-08-05
- 成都小程序開發(fā):論已上線小程序的二次開發(fā) 2022-07-17
- 微信小程序開發(fā)不懂代碼怎么制作? 2022-11-08
- 小程序開發(fā)制作為實體店帶來哪些優(yōu)勢? 2020-11-16
- 微信小程序的火爆,對百度競價會有影響嗎? 2014-06-06