【計算機體系結(jié)構(gòu)-02】機器模型-創(chuàng)新互聯(lián)
計算機的基本工作就是進行運算,那么計算就需要有用來處理計算方法的處理單元和提供或保存數(shù)值的存儲單元。一般將用來處理計算方法的處理單元稱為 算術(shù)邏輯單元 (ALU--Arithmetic Logic Unit)。在一個計算過程中可能會是這樣的一個流程,從存儲單元中取出一些數(shù)據(jù),放進ALU中進行計算,然后將計算結(jié)果保存到存儲單元中。
那么完成這個計算流程的機器模型是如何利用存儲單元和算術(shù)邏輯單元構(gòu)建起來的?該如何訪問存儲器?機器模型該允許什么樣的指令和操作?操作數(shù)怎么獲取從哪來?結(jié)果又該放在哪?
?
首先明確一點,機器模型不是指令集架構(gòu),上篇文章《【計算機體系結(jié)構(gòu)-01】指令集體系結(jié)構(gòu)、微體系結(jié)構(gòu)簡介》已經(jīng)說明了,指令集架構(gòu)是為軟件編程提供的一種規(guī)范,它是關(guān)于計算和操作指令如何封裝制定的一套標(biāo)準(zhǔn),而 機器模型則是一種更加基礎(chǔ)的理論,是構(gòu)建出存儲器和 ALU 的物理結(jié)構(gòu),從而確定數(shù)據(jù)如何移動,又如何從 ALU 移動到存儲器。
不管你信不信,在一個處理器中是可以沒有寄存器的(寄存器不是必要的)。OK,來看一個歷史上實際搭建過的處理器,它的結(jié)構(gòu)非常簡單。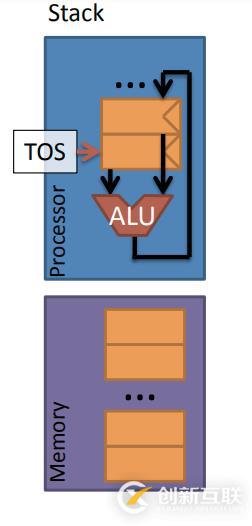
那么可以看圖片中的這種機器模型,利用棧結(jié)構(gòu)存儲,而棧只是一個存儲器,并非寄存器。棧的結(jié)構(gòu)相信大家已經(jīng)很清楚,數(shù)據(jù)會遵循先入后出的順序入棧、出棧。這個 機器模型的工作流程很簡單,只需要從棧頂開始取兩個元素,通過 ALU 計算,然后將結(jié)果保存棧頂。
2.2. 累加器架構(gòu) (Accumluator Architecture)下面是一個累加器的結(jié)構(gòu)。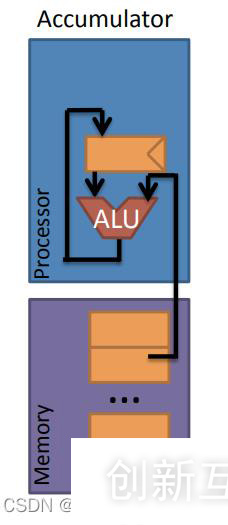
累加器,顧名思義會對一個數(shù)值不停的做加法,而得到的結(jié)果最終也只會有一個,操作數(shù)只有一個,因此在處理器中只會有一個寄存器,所有的計算都是自動的或不可見的。同時還可以提供給累加器另外一個操作數(shù),即除了寄存器中的操作數(shù)還提供一個來自存儲器 (Memory) 的操作數(shù),此時則需要給該操作數(shù)命名。
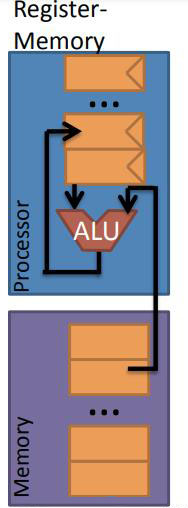
根據(jù)上面累加器的兩個參數(shù)方案那么很容易想到上圖這種架構(gòu),寄存器-存儲器架構(gòu),即一個源操作數(shù)來自于存儲器,該操作數(shù)需要命名,而另一個操作數(shù)可以來自于寄存器(不需要命名),然后,還可以有一個目的存儲(可選),用于保存計算結(jié)果的存儲位置,同樣需要命名才可以。那么這種結(jié)構(gòu)一個操作最多需要有兩個命名的操作數(shù)。
2.4. 寄存器-寄存器架構(gòu) (Register-Register Architecture)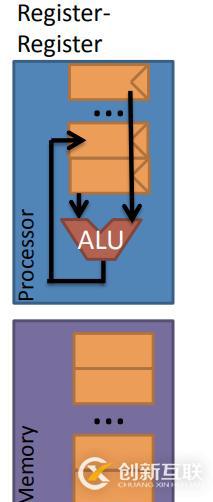
那么寄存器-寄存器架構(gòu),兩個操作數(shù)均來自于處理器中的寄存器,同時兩者均需被命名,當(dāng)需要有目的存儲時,還需要為目的存儲操作數(shù)命名。
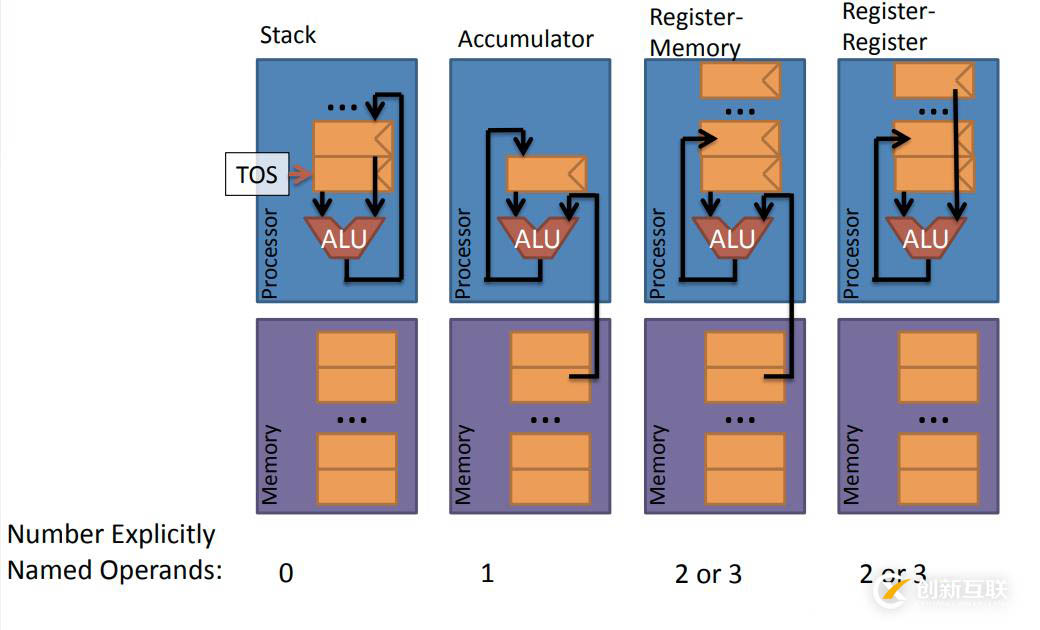
這四種架構(gòu),需要被命名的操作數(shù)數(shù)目分別為0、1、2或3、2或3,相信通過上文你已經(jīng)清楚了,后面兩種架構(gòu)為什么是2或3,因為有時候數(shù)據(jù)計算結(jié)果的保存目的地會隱式的確定無需命名,當(dāng)需要明確指出時,那么就會多一個命名操作數(shù)。
例如,X86架構(gòu)中的第一個操作數(shù)總是作為結(jié)果的保存位置,因此它會少命名一個操作數(shù)。例如MIPS、RISC架構(gòu)則需要將三個操作數(shù)全部命名。
棧基架構(gòu)雖然是個很老的架構(gòu)模型,但是很經(jīng)典。過去的Burrough's 5000 (B5000)機器就是使用的棧基架構(gòu)(1960年),近一點的Java虛擬機實際上也是利用棧結(jié)構(gòu)實現(xiàn)。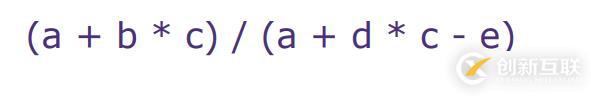
用一個例子🌰來說明棧基架構(gòu)機器模型的工作原理,來看上圖這個計算表達式,首先用a加上b * c,然后整個括號的計算結(jié)果除以a加上d * c再減去e的運算結(jié)果才得到最終的表達式結(jié)果。這對于我們來說計算這個表達式很簡單,但對于計算機來說就沒那么直接了,甚至有點復(fù)雜。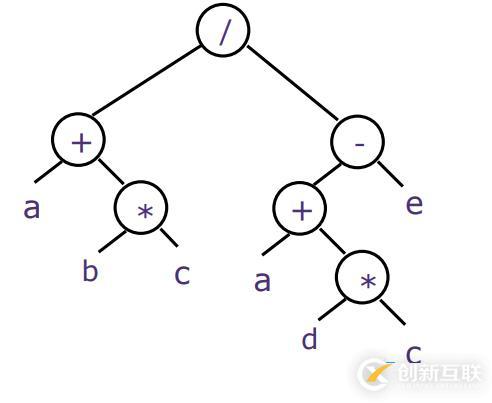
實際上計算機會將這個表達式分解并生成一個 解析樹,就上圖這樣。一個二叉樹的結(jié)構(gòu),所有的葉子節(jié)點上是需要做計算的數(shù),其它節(jié)點則是運算符。開始先由b乘以c加上a,用這個結(jié)果除以另一邊的子表達式。整個二叉樹用順序結(jié)構(gòu)保存即為計算機應(yīng)該要做的操作表達式,像下面這樣。

如果現(xiàn)在使用的是棧基架構(gòu)的機器模型,那么就意味著會有一個求值棧,首先pusha到棧中,接著push b到棧中、push c到棧中,當(dāng)遇到運算符,拿棧頂?shù)膬蓚€元素做對應(yīng)的運算,再保存到棧中,依次類推就會得到下面這樣的棧操作流程。
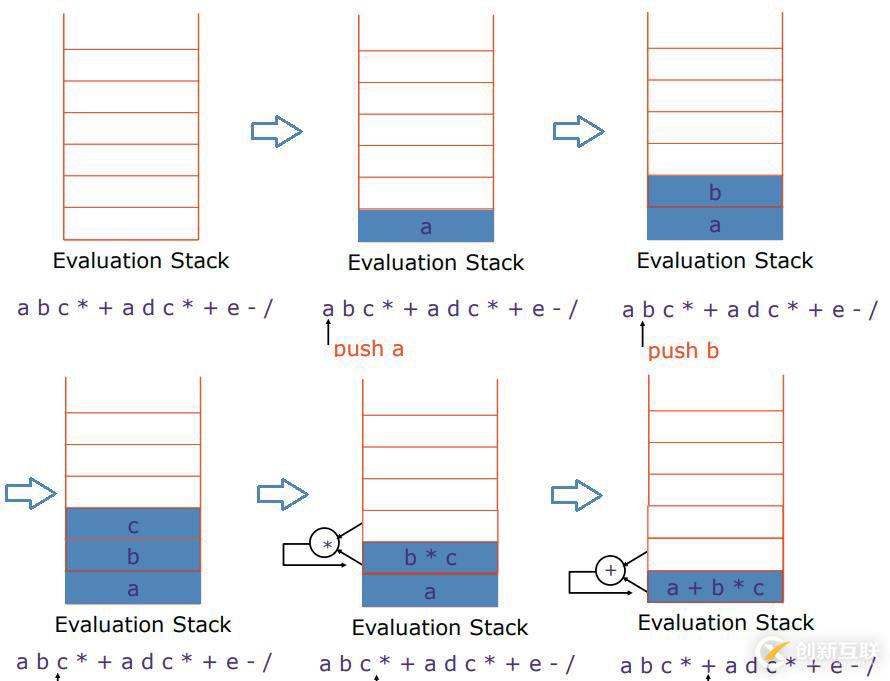
通過這樣的棧操作流程,就可以把左邊的子表達式結(jié)果計算出來,依照該方法繼續(xù)姐可以計算出整個表達式的結(jié)果。你會發(fā)現(xiàn)計算機在計算這樣長的表達式,實際上可以在一個很小的棧中完成對整個表達式的計算,并且有一個好處是,完全不需要對任何一個操作數(shù)命名(因為操作數(shù)是固定的,總是拿棧頂?shù)膬蓚€元素作運算)。因此這個機器模型可以讓你跑任何現(xiàn)實的程序。
?
需要注意的一點是,棧是處理器狀態(tài)的一部分,并且很多時候在指令集體系架構(gòu)的角度來看棧是無限大的。但在實際上,計算機中的棧是有限長的,因為在計算機中無論如何都不可能出現(xiàn)一個無限長且真實存在的棧。它只是在概念上是無限的,因此你需要保證不能發(fā)生棧溢出(內(nèi)存溢出、主存儲器溢出)。 例如,上面例子中的表達式如果是很長,或者產(chǎn)生的解析樹太深,都會導(dǎo)致棧溢出的可能。
🤕基礎(chǔ)設(shè)計:
假如現(xiàn)在有一個指令集架構(gòu)的微架構(gòu)實現(xiàn)是基于棧基架構(gòu)的,由于求值棧在進行計算時總是需要兩個操作數(shù),那么就將求值棧中的頂部的兩個元素的地址是保存在寄存器中,而其余的則保存在主存中(包含溢出的元素)。每一次入棧操作都會產(chǎn)生一次內(nèi)存引用,每一次出棧操作也會有一次內(nèi)存引用(出棧會將棧中的元素返回到主存中)。而且更重要的是,當(dāng)發(fā)生棧溢出后,將會增加額外的內(nèi)存引用,因為在做棧操作時需要將主存的數(shù)據(jù)先拿出來。顯然,這樣的結(jié)構(gòu)讓操作產(chǎn)生的步驟非常的多(內(nèi)存引用)。
🤪優(yōu)化設(shè)計:
那么站在微系體系架構(gòu)優(yōu)化的角度考慮,將棧中的N個元素全部直接保存在寄存器中(棧中的所有元素N小于或等于可用的寄存器數(shù)),這樣每次執(zhí)行push和pop操作時就不必執(zhí)行內(nèi)存引用,就只有當(dāng)發(fā)生棧溢出時才需要增加一步內(nèi)存引用操作。
Okay,用優(yōu)化后的棧來計算一下,繼續(xù)再用上面的例子,現(xiàn)在給出限制條件,限制棧的大小為 2,即最多只能放兩個元素,超過則會發(fā)生溢出。

先來看這個例子都會做什么,首先push了三次元素進棧,然后對頂部的兩個元素做乘法,然后再做加法,之后再三次push操作,棧頂兩個元素相乘,用結(jié)果加上a,接著push e,用上一次結(jié)果減去e,再將棧頂兩個元素做除法完成計算。
但是棧中只能存放兩個元素,那么來看看在棧操作中具體會發(fā)生什么事情,
- 第一步
push a,這時候時空棧,沒問題,直接進,非空非滿棧; - 第二步,接著
push b,也 OK,此時為滿棧; - 第三步,當(dāng)
push c的時候,發(fā)現(xiàn)棧已經(jīng)滿了,這個時候還想要再push,那就會發(fā)生 棧下溢(Underflow),此時會先將棧底元素也就是a,保存到主存中(Main Memory),該操作會發(fā)生一次內(nèi)存引用,圖中的ss(a)表示將astore到主存中,R0寄存器的值改變?yōu)?code>a的主存地址(這便發(fā)生額外的一次內(nèi)存引用),然后將c壓入棧頂。 - 第四步,將棧頂?shù)膬蓚€元素做乘法運算,將結(jié)果
b * c保存到R1,棧元素減一,同時從a的主存地址獲取(fetche)a(發(fā)生內(nèi)存引用)也就是圖中的sf(a),將a保存到R0中,此時棧中有兩個元素,棧頂是R1 = b * c,滿棧; - 第五步,將棧頂?shù)膬蓚€元素做加法運算,將結(jié)果
a + b * c入棧保存到R0,棧元素減一,此時棧中只有一個元素即為棧頂元素R0 = a + b * c,非空非滿棧; - 第六步,
push a,進棧,沒問題,R1 = a,此時為滿棧,棧頂元素為a; - 第七步,
push d進棧,發(fā)生underflow,將棧底元素保存到主存發(fā)生一次內(nèi)存引用(ss(a + b * c)),R0保存a + b * c的存儲地址,此時棧頂元素為R2 = d,滿棧; - 第八步,
push c進棧,發(fā)生underflow,將棧底元素保存到主存,發(fā)生一次內(nèi)存引用(ss(a)),此時棧頂元素為R3 = c,滿棧; - 第九步,將棧頂?shù)膬蓚€元素做乘法運算,將結(jié)果
d + c保存到R2,棧元素減一,同時從a的主存地址獲取(fetche)a(發(fā)生內(nèi)存引用)也就是圖中的sf(a),將a保存到R1中,此時棧中有兩個元素,棧頂是R2 = b * c,滿棧; - 第十步,將棧頂?shù)膬蓚€元素做加法運算,將結(jié)果
a + d * c保存到R1,棧元素減一,同時從a + b * c的主存地址獲取(fetche)a + b * c的值(發(fā)生內(nèi)存引用)也就是圖中的sf(a + b * c),將a + b * c保存到R0中,此時棧中有兩個元素,棧頂是R1 = a + d * c,滿棧; - 第十一步,
push e入棧操作,發(fā)生underflow,將棧底元素保存到主存發(fā)生一次內(nèi)存引用(ss(a + b * c)),R0保存a + b * c的存儲地址,此時棧頂元素為R2 = e,滿棧; - 第十二步,將棧頂?shù)膬蓚€元素做減法運算,將計算結(jié)果
a + d * c - e保存到R1,棧元素減一,同時從R0保存的主存地址拿出a + b * c的值保存進R0,此時為滿棧,棧頂元素R1 = a + d * c - e; - 第十三步,將棧頂?shù)膬蓚€元素做除法運算,將計算結(jié)果
(a + b * c) / (a + d * c - e)用R0保存,棧元素減一。
統(tǒng)計一下,利用這個求值棧計算過程中間接性的做了4次store操作和4次fetche操作,也就是說使用該結(jié)構(gòu)棧在正常的流程中額外的增加了8次訪存操作。
我們改變一下棧大小會發(fā)生什么,將棧的大小增加為4,那么它的執(zhí)行流程將會是下面這樣。

哇嗚,一氣呵成,中間沒有發(fā)生內(nèi)存引用,Good。因為計算該表達式最多的情況下會一次性有4個元素在棧中,那么棧的大小只要滿足,就不會發(fā)生棧溢出的情況,也就不會有內(nèi)存引用這樣額外的訪存操作了。
通過上面的幾個例子,相信各位已經(jīng)清楚了棧基架構(gòu)的機器模型。看起來他們是可以成功的完成計算任務(wù),但是有一個明顯的問題不知道機智的你有沒有發(fā)現(xiàn)。第一步的時候push a,將a入棧,接著后面又有一次push a,push c同樣是,我們再做重復(fù)多余的工作欸!!棧基機器模型的架構(gòu)很簡單,指令很密集,但這對于機器性能不算是好事,因為使用該模型將意味著要面臨多次的重新讀取。
如果使用指令集架構(gòu),如MIPS,那么將會有32個通用寄存器,可以在任何指令中為任何一個寄存器命名。那么這時候,當(dāng)你已經(jīng)load了a、b、c、d、e數(shù)值到寄存器空間中一次了,那么之后所有關(guān)于這幾個數(shù)的操作時都無需重新load。事實上這個問題時由指令集解決的,并不是基礎(chǔ)機器模型的問題,也不是微架構(gòu)要解決的問題。
上文已經(jīng)介紹了這四種機器模型,Stack-Based、Accumulator、Register-Memory、Register-Register。現(xiàn)在用一個簡單的計算C = A + B,分別使用這四個機器模型,看看會有什么不同。
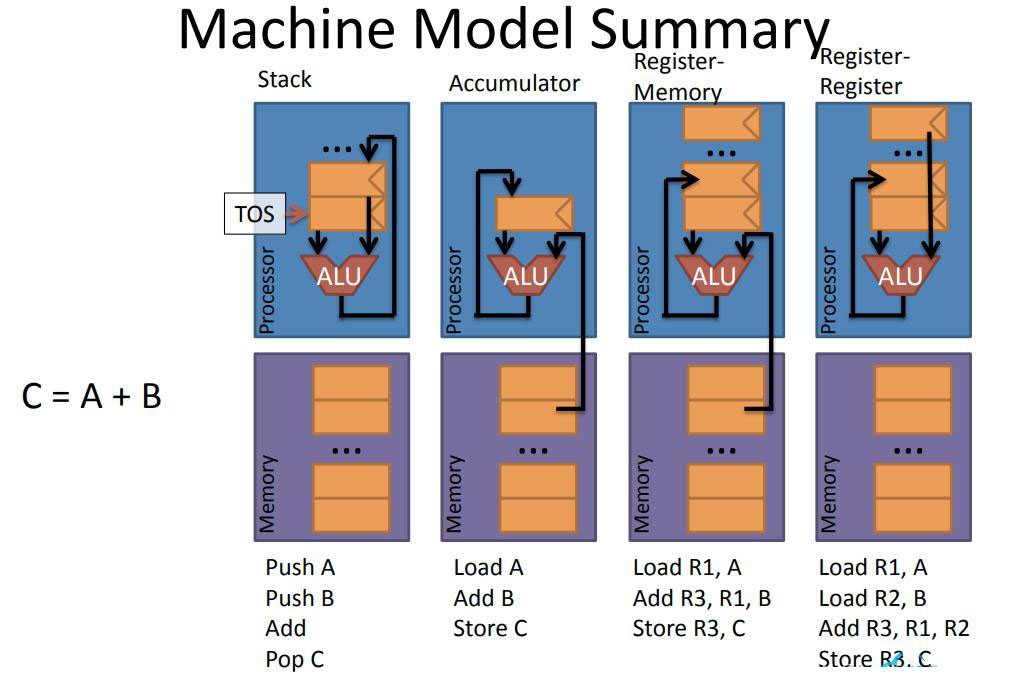
- Stack-Based Architecture
棧基架構(gòu)的機器模型的工作過程就是,Push A,將A的值入棧,Push B,將B的值入棧,用棧頂兩個元素做Add操作,然后將結(jié)果Pop到C中保存。
- Accumulator Architecture
累加器的機器模型工作過程為,Load A,Add B即A + B,然后將結(jié)果Store到C中。
- Register-Memory Architecture
寄存器-存儲器架構(gòu)機器模型的工作過程,Load R1, A、Add R3, R1, B,將B的值與R1保存的值相加,將結(jié)果保存到R3中,再將R3的值Store到C中。
- Register-Register Architecture
寄存器-寄存器架構(gòu)機器模型的工作過程為,Load R1, A、Load R2, B,執(zhí)行Add,將R1和R2保存的值相加,并將結(jié)果保存到R3中,再將R3的值Store到C中,完成計算。
相比前兩個架構(gòu),后兩個架構(gòu)在使用A、B之前需要先Load,計算完后還需要Store,看起來似乎不夠高效,沒有前面兩個模型簡潔,但是當(dāng)之后需要重復(fù)性的使用A、B的值進行計算的話,那么后兩個架構(gòu),將不需要再次Load,而可以直接使用,而前兩個架構(gòu)則需要重復(fù)性的執(zhí)行Push或Load指令,這樣看起來優(yōu)勢就會體現(xiàn)出來了。
覺得這篇文章對你有幫助的話,就留下一個贊吧*^v^*
請尊重作者,轉(zhuǎn)載還請注明出處!感謝配合~
[作者]: Imagine Miracle
[版權(quán)]: 本作品采用「署名-非商業(yè)性使用-相同方式共享 4.0 國際」許可協(xié)議進行許可。
[本文鏈接]: https://blog.csdn.net/qq_36393978/article/details/128717724
你是否還在尋找穩(wěn)定的海外服務(wù)器提供商?創(chuàng)新互聯(lián)www.cdcxhl.cn海外機房具備T級流量清洗系統(tǒng)配攻擊溯源,準(zhǔn)確流量調(diào)度確保服務(wù)器高可用性,企業(yè)級服務(wù)器適合批量采購,新人活動首月15元起,快前往官網(wǎng)查看詳情吧
分享標(biāo)題:【計算機體系結(jié)構(gòu)-02】機器模型-創(chuàng)新互聯(lián)
文章鏈接:http://chinadenli.net/article0/ceosoo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供用戶體驗、移動網(wǎng)站建設(shè)、定制開發(fā)、企業(yè)建站、虛擬主機、做網(wǎng)站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- linux端口是什么意思-創(chuàng)新互聯(lián)
- 為什么有必要對網(wǎng)站開啟https?-創(chuàng)新互聯(lián)
- C#刪除數(shù)組內(nèi)的某個值、一組值方法詳解-創(chuàng)新互聯(lián)
- perl語言入門第七版百度云perl語言與c相比如何?-創(chuàng)新互聯(lián)
- ASP.net中Core如何自定義View查找位置-創(chuàng)新互聯(lián)
- PyTorch中加載數(shù)據(jù)集的示例分析-創(chuàng)新互聯(lián)
- jQuery+PHP+Mysql如何實現(xiàn)抽獎程序-創(chuàng)新互聯(lián)

- 搜索引擎優(yōu)化(SEO)主要優(yōu)化哪幾個點? 2016-08-10
- 網(wǎng)站SEO:針對品牌和企業(yè)的搜索引擎優(yōu)化 2022-09-04
- 站外搜索引擎優(yōu)化戰(zhàn)略有哪些 2020-09-18
- 關(guān)于搜索引擎優(yōu)化的誤區(qū) 2022-06-06
- SEO搜索引擎優(yōu)化技巧 2015-04-11
- 濟寧網(wǎng)站排名有效辦理網(wǎng)站搜索引擎優(yōu)化排名和收錄問題,讓搜索排名變得垂手可得 2023-01-13
- 門戶網(wǎng)站搜索引擎優(yōu)化的三項討論 2020-03-31
- 你是否忽略了你的頁外搜索引擎優(yōu)化? 2022-08-19
- 臨沂百度快照:「搜索引擎優(yōu)化平臺」天天欣賞的網(wǎng)站是怎么做出來的? 2023-01-04
- 基于Flash的網(wǎng)站的搜索引擎優(yōu)化技巧 2016-11-16
- 網(wǎng)站建設(shè)對搜索引擎優(yōu)化的重要性 2022-08-27
- 做搜索引擎優(yōu)化,你不能不知道搜索引擎是如何 2014-02-09