python爬蟲中scrapy怎么給圖書分類
這篇文章主要介紹python爬蟲中scrapy怎么給圖書分類,文中介紹的非常詳細(xì),具有一定的參考價(jià)值,感興趣的小伙伴們一定要看完!
十年的懷來(lái)網(wǎng)站建設(shè)經(jīng)驗(yàn),針對(duì)設(shè)計(jì)、前端、開發(fā)、售后、文案、推廣等六對(duì)一服務(wù),響應(yīng)快,48小時(shí)及時(shí)工作處理。營(yíng)銷型網(wǎng)站建設(shè)的優(yōu)勢(shì)是能夠根據(jù)用戶設(shè)備顯示端的尺寸不同,自動(dòng)調(diào)整懷來(lái)建站的顯示方式,使網(wǎng)站能夠適用不同顯示終端,在瀏覽器中調(diào)整網(wǎng)站的寬度,無(wú)論在任何一種瀏覽器上瀏覽網(wǎng)站,都能展現(xiàn)優(yōu)雅布局與設(shè)計(jì),從而大程度地提升瀏覽體驗(yàn)。創(chuàng)新互聯(lián)公司從事“懷來(lái)網(wǎng)站設(shè)計(jì)”,“懷來(lái)網(wǎng)站推廣”以來(lái),每個(gè)客戶項(xiàng)目都認(rèn)真落實(shí)執(zhí)行。
spider抓取程序:
在貼上代碼之前,先對(duì)抓取的頁(yè)面和鏈接做一個(gè)分析:
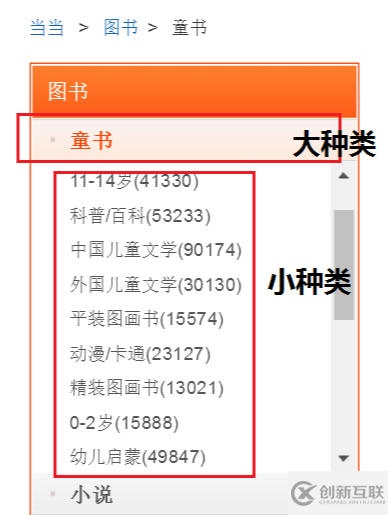
http://category.dangdang.com/pg4-cp01.25.17.00.00.00.html
這個(gè)是當(dāng)當(dāng)網(wǎng)圖書的鏈接,經(jīng)過(guò)分析發(fā)現(xiàn):大種類的id號(hào)對(duì)應(yīng) cp01.25中的25,小種類對(duì)應(yīng)id號(hào)中的第三個(gè) 17,pg4代表大種類 —>小種類下圖書的第17頁(yè)信息。
為了在抓取圖書信息的同時(shí)找到這本圖書屬于哪一大種類下的小種類的歸類信息,我們需要分三步走,第一步:大種類劃分,在首頁(yè)找到圖書各大種類名稱和對(duì)應(yīng)的id號(hào);第二步,根據(jù)大種類id號(hào)生成的鏈接,找到每個(gè)大種類下的二級(jí)子種類名稱,及對(duì)應(yīng)的id號(hào);第三步,在大種類 —>小種類的歸類下抓取每本圖書信息。
分步驟介紹下:
1、我們繼承redisSpider作為父類,start_urls作為初始鏈接,用于請(qǐng)求首頁(yè)圖書數(shù)據(jù)
# -*- coding: utf-8 -*-
import scrapy
import requests
from scrapy import Selector
from lxml import etree
from ..items import DangdangItem
from scrapy_redis.spiders import RedisSpider
class DangdangSpider(RedisSpider):
name = 'dangdangspider'
redis_key = 'dangdangspider:urls'
allowed_domains = ["dangdang.com"]
start_urls = 'http://category.dangdang.com/cp01.00.00.00.00.00.html'
def start_requests(self):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
yield scrapy.Request(url=self.start_urls, headers=headers, method='GET', callback=self.parse)2、在首頁(yè)中抓取大種類的名稱和id號(hào),其中yield回調(diào)函數(shù)中傳入的meta值為本次匹配出的大種類的名稱和id號(hào)
def parse(self, response):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent': user_agent}
lists = response.body.decode('gbk')
selector = etree.HTML(lists)
goodslist = selector.xpath('//*[@id="leftCate"]/ul/li')
for goods in goodslist:
try:
category_big = goods.xpath('a/text()').pop().replace(' ','') # 大種類
category_big_id = goods.xpath('a/@href').pop().split('.')[1] # id
category_big_url = "http://category.dangdang.com/pg1-cp01.{}.00.00.00.00.html".\
format(str(category_big_id))
# print("{}:{}".format(category_big_url,category_big))
yield scrapy.Request(url=category_big_url, headers=headers,callback=self.detail_parse,
meta={"ID1":category_big_id,"ID2":category_big})
except Exception:
Pass3、根據(jù)傳入的大種類的id號(hào)抓取每個(gè)大種類下的小種類圖書標(biāo)簽,yield回調(diào)函數(shù)中傳入的meta值為大種類id號(hào)和小種類id號(hào)
def detail_parse(self, response):
'''
ID1:大種類ID ID2:大種類名稱 ID3:小種類ID ID4:小種類名稱
'''
url = 'http://category.dangdang.com/pg1-cp01.{}.00.00.00.00.html'.format(response.meta["ID1"])
category_small = requests.get(url)
contents = etree.HTML(category_small.content.decode('gbk'))
goodslist = contents.xpath('//*[@class="sort_box"]/ul/li[1]/div/span')
for goods in goodslist:
try:
category_small_name = goods.xpath('a/text()').pop().replace(" ","").split('(')[0]
category_small_id = goods.xpath('a/@href').pop().split('.')[2]
category_small_url = "http://category.dangdang.com/pg1-cp01.{}.{}.00.00.00.html".\
format(str(response.meta["ID1"]),str(category_small_id))
yield scrapy.Request(url=category_small_url, callback=self.third_parse, meta={"ID1":response.meta["ID1"],\
"ID2":response.meta["ID2"],"ID3":category_small_id,"ID4":category_small_name})
# print("============================ {}".format(response.meta["ID2"])) # 大種類名稱
# print(goods.xpath('a/text()').pop().replace(" ","").split('(')[0]) # 小種類名稱
# print(goods.xpath('a/@href').pop().split('.')[2]) # 小種類ID
except Exception:
Pass4、抓取各大種類——>小種類下的圖書信息
def third_parse(self,response):
for i in range(1,101):
url = 'http://category.dangdang.com/pg{}-cp01.{}.{}.00.00.00.html'.format(str(i),response.meta["ID1"],\
response.meta["ID3"])
try:
contents = requests.get(url)
contents = etree.HTML(contents.content.decode('gbk'))
goodslist = contents.xpath('//*[@class="list_aa listimg"]/li')
for goods in goodslist:
item = DangdangItem()
try:
item['comments'] = goods.xpath('div/p[2]/a/text()').pop()
item['title'] = goods.xpath('div/p[1]/a/text()').pop()
item['time'] = goods.xpath('div/div/p[2]/text()').pop().replace("/", "")
item['price'] = goods.xpath('div/p[6]/span[1]/text()').pop()
item['discount'] = goods.xpath('div/p[6]/span[3]/text()').pop()
item['category1'] = response.meta["ID4"] # 種類(小)
item['category2'] = response.meta["ID2"] # 種類(大)
except Exception:
pass
yield item
except Exception:
pass分類之后的圖書種類想要查閱是不是變得容易了呢?畢竟要從一大堆數(shù)據(jù)中,找出我們想要的那類型圖書是件費(fèi)時(shí)費(fèi)力的事情,小伙伴也給圖書做個(gè)分類吧~
以上是“python爬蟲中scrapy怎么給圖書分類”這篇文章的所有內(nèi)容,感謝各位的閱讀!希望分享的內(nèi)容對(duì)大家有幫助,更多相關(guān)知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道!
文章題目:python爬蟲中scrapy怎么給圖書分類
標(biāo)題來(lái)源:http://chinadenli.net/article38/jgggsp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供軟件開發(fā)、網(wǎng)站策劃、網(wǎng)站維護(hù)、企業(yè)網(wǎng)站制作、搜索引擎優(yōu)化、網(wǎng)站內(nèi)鏈
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 成都企業(yè)在選擇建站公司時(shí)應(yīng)該考慮哪些問(wèn)題 2016-12-15
- 哪家建站公司做企業(yè)網(wǎng)站比較好 2022-08-10
- 上海建站公司如何將網(wǎng)站關(guān)鍵詞優(yōu)化到搜索引擎首頁(yè)? 2020-11-24
- 贛州專業(yè)建站公司:你了解什么是虛擬主機(jī)嗎? 2021-10-12
- 如何選擇一個(gè)靠譜的網(wǎng)頁(yè)建站公司 2016-11-14
- 如何選擇優(yōu)秀的建站公司 2017-05-31
- 建站公司如何更好地為客戶建設(shè)營(yíng)銷型網(wǎng)站 2021-09-28
- 怎么判斷建站公司的建站能力? 2021-06-20
- 想要找個(gè)靠譜建站公司做營(yíng)銷型網(wǎng)站,不妨先來(lái)了解這幾點(diǎn) 2022-08-31
- 網(wǎng)站進(jìn)行SEO優(yōu)化前必須分析的兩大塊 2022-05-24
- 不同的營(yíng)銷型網(wǎng)站建站公司報(bào)價(jià)為何不一樣? 2022-08-05
- 做網(wǎng)站建設(shè)如何選擇一個(gè)專業(yè)的豐臺(tái)建站公司 2021-12-14