再有人問你kafka把這篇扔給他(建議收藏)-創(chuàng)新互聯(lián)
最近重新讀起kafka的內(nèi)容,看到kafka官網(wǎng)文檔里,有專門一欄講kafka的設(shè)計,覺得很受益。我們常常會知道這個中間件是什么,是什么機制,這次想換個角度來聊,它在設(shè)計消息系統(tǒng)的時候,都做了哪些考慮?為什么這么考慮?

kafka只有一個,但是它的設(shè)計思想正在被成百上千個組件在學習和借鑒。這或許是更有價值的一件事。
PS:如果有講的不對的地方,歡迎大家指正。
PPS : 另外,本文比較長,偏基礎(chǔ),部分細節(jié)直接通過目錄跳過也行 😂
那我開始了啊
kafka 原理及設(shè)計思考- 前言
- 消息中間件的編年史
- 一簡介
- kafka 設(shè)計規(guī)劃
- rabbitMQ 架構(gòu)分析
- kafka 架構(gòu)圖
- 二基本原理
- 1持久化
- 磁盤
- 順序?qū)?/li>
- 存儲設(shè)計及查找過程
- 對比
- 小結(jié)
- 2生產(chǎn)者
- 第一問 發(fā)送到哪
- 第二問 怎么知道發(fā)送成功了
- 第三問 既不丟也不重復?
- 小結(jié)
- 3消費者
- 第一問 Push or pull
- 第二問 消費哪個分區(qū)
- 第三問 從哪條消息開始消費
- 小結(jié)
- 三特性及其具體保證
- 1高可用及水平擴展
- 2高吞吐
- 1 直連
- 2 順序?qū)?/li>
- 3 PageCache
- 4 零拷貝
- 5 批量壓縮
- 6 批量發(fā)送
- 7 水平擴展
- 總結(jié)
在正式介紹kafka的相關(guān)細節(jié)特性之前,先插播一個消息中間件的編年史。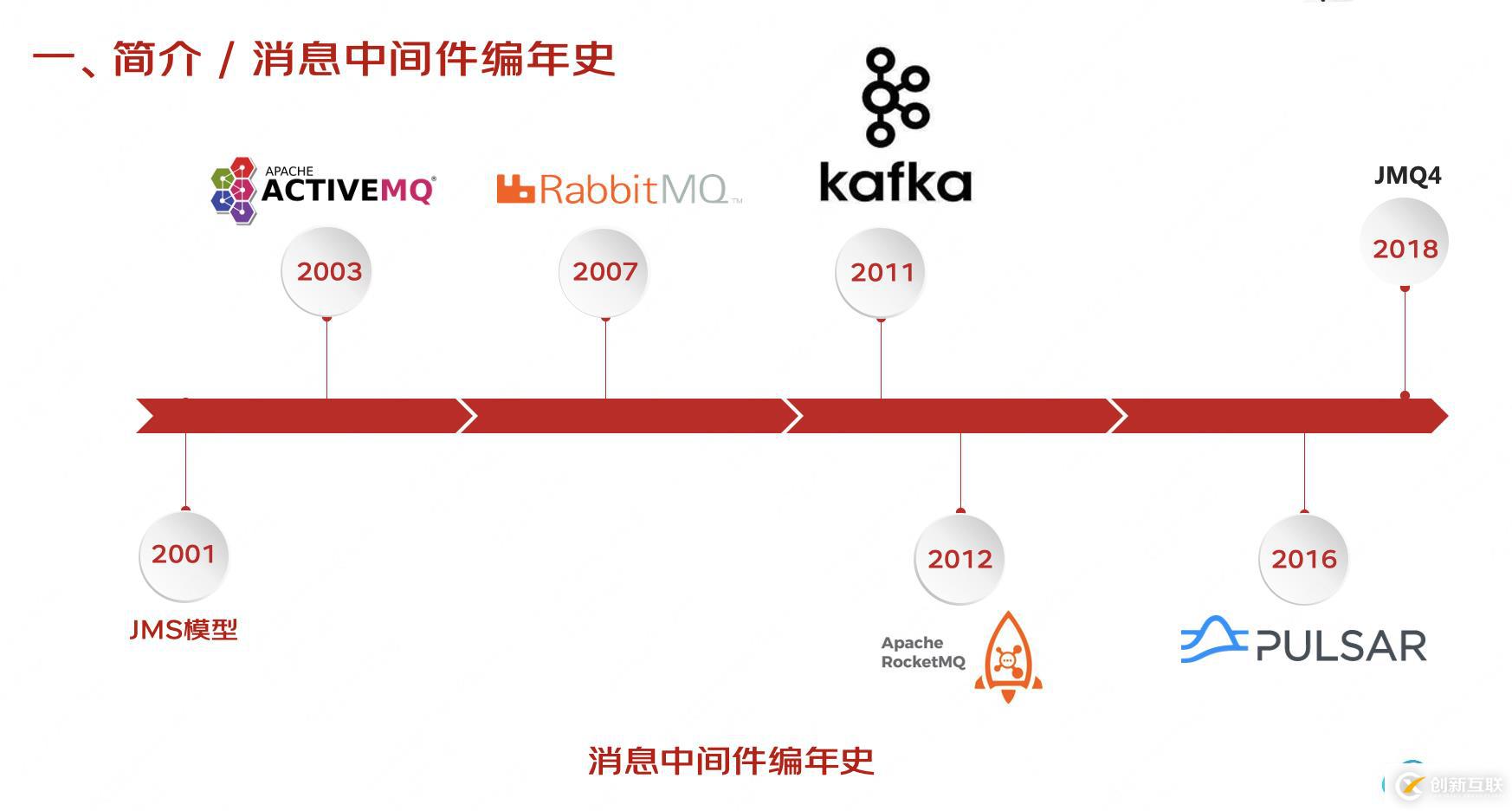
- 2001年提出JMS的消息模型和規(guī)范以來
- 2003年誕生了ActiveMQ,在今天它也還在不斷迭代;
- 2007年的RabbitMQ,它是第一個基于應用層協(xié)議的開放標準AMQP的協(xié)議實現(xiàn);
- 2011年kafka,也就是我們今天的主角。「給它的臺詞要多點」大家都知道它最初是LinkedIn研發(fā)的,在2011年初開源之后,2012年成為Apache 項目,直到今天 依然是Apache 頂級項目。一開始用ACtiveMQ 來解決業(yè)務問題,但擴展性不足,還經(jīng)常導致阻塞,所以開始自研了Kafka。
- 2012年阿里的RocketMQ開源。它也參照Kafka的設(shè)計理念,并主要對消息的可靠傳輸及事務性做了優(yōu)化。
- 2016年Yahoo開發(fā)的Pulsar,這是基于云原生的消息系統(tǒng),在多租戶上可以做徹底的隔離,處理速度也更快,但是相對來說落地實踐的場景還不夠豐富,并且缺少一個里程碑的穩(wěn)定版本。
- 2018年,我們的JMQ完成第四次大版本的迭代,性能也有了極大的提升。也就是我們現(xiàn)在在用的JMQ4
大家看kafka后邊幾個的設(shè)計架構(gòu),也會多多少少能從其中看出一些kafka設(shè)計的影子。
一簡介 kafka 設(shè)計規(guī)劃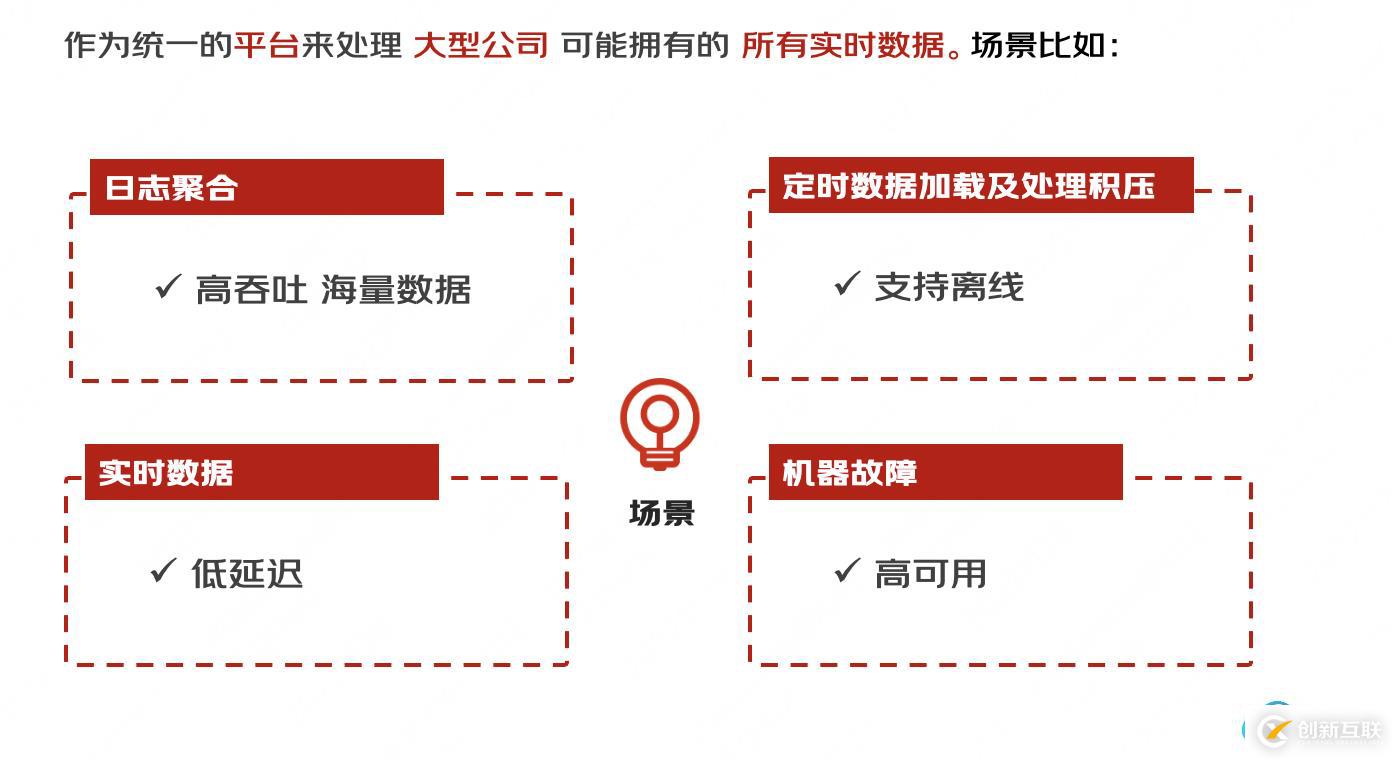
總所周知,kafka最初是美國一家LinkedIn 的工程師研發(fā),當時主要解決數(shù)據(jù)管道(data pipeline)的問題。
當時這家公司內(nèi)部有很多子系統(tǒng)用于收集和分析,比如用戶行為操作,他們會定期把數(shù)據(jù)以xml的格式發(fā)送到統(tǒng)一的地方進行離線處理。既然現(xiàn)有解決方案
reps便開始組織團隊進行消息傳遞系統(tǒng)的研發(fā); 定位:作為統(tǒng)一的平臺來處理大公司可能擁有的所有實時數(shù)據(jù)源。定位很宏觀,所以要想的場景就比較多。
" 它必須具有高吞吐量才能支持高容量事件流,例如實時日志聚合。
“
- 它必須具有高吞吐量才能支持高容量事件流,例如實時日志聚合。據(jù)加載。
- 它需要優(yōu)雅地處理大量數(shù)據(jù)積壓,以便能夠支持來自離線系統(tǒng)的定期數(shù)據(jù)加載。
- 這也意味著系統(tǒng)必須處理低延遲交付,以處理更傳統(tǒng)的消息傳遞用例。在存在機器故障的情況下保證容錯能力。"
- 在將流饋送到其他數(shù)據(jù)系統(tǒng)進行服務的情況下,我們知道系統(tǒng)必須能夠在存在機器故障的情況下保證容錯能力。
”
也就是用我們常說的:高吞吐,低延時,支持離線,高可用
那么kafka是怎么做的?這里面
有很多設(shè)計師自己的思考,篇幅原因,我們重點說幾個核心內(nèi)容。
開始之前就問一個問題,實現(xiàn)這些很難么?🌚
別急,那我們先看一下kafka出現(xiàn)之前的當時的消息系統(tǒng)架構(gòu)。
rabbitMQ 高可用模式:

這是rabbitMq的高可用模式。每個節(jié)點都有一個隊列,生產(chǎn)者生產(chǎn)的數(shù)據(jù)投遞到指定的服務器的隊列上,然后隊列再進行同步。每個節(jié)點都有一個完整的鏡像,包含全部的數(shù)據(jù)。任何一個節(jié)點宕機之后,其他節(jié)點都還有一個完整數(shù)據(jù),別的consumer 可以到其他節(jié)點上去消費數(shù)據(jù)。
但是當我們數(shù)據(jù)量再大的時候,是沒辦法水平擴展的。

水平擴展:
我們看kafka的這個圖里,生產(chǎn)者ProducerA 生產(chǎn)的2條消息分別發(fā)送到了分區(qū)0 和分區(qū)1,然后消費者從對應的分區(qū)上進行消費。
如果topic的數(shù)據(jù)量更大的話,那還是可以增加新的分區(qū)來水平擴展。也就是可以增加新的分片數(shù)量。
高可用:
每個分區(qū)可以設(shè)置副本。Follower實時從 leader 中同步數(shù)據(jù),保持和 leader 數(shù)據(jù)的同步。leader 發(fā)生故障時,某個 follower 會成為新的 leader 。消費者會通過zk感知到變化,然后去從新的leader上消費數(shù)據(jù)。
那是誰來控制副本選舉的過程的呢?
整個集群會選舉一個Broker 作為Controller。他負責管理整個集群所有分區(qū)和副本的狀態(tài)調(diào)整。
在這里先有一個大體的印象,我們接下來具體看下主要模塊的工作流程是什么樣的。
二基本原理 1持久化 磁盤
有第一個問題要討論的就是磁盤。因為傳統(tǒng)觀念是磁盤總是很慢。kafka重視高吞吐,為什么要選用慢的磁盤存儲?
順序?qū)?p>實際上快慢完全取決于使用方式。這是09年發(fā)表的實驗結(jié)論:
看前兩條, 磁盤的順序?qū)懭肓渴请S機寫入量的100多倍。
!!值得注意的是,這個是對內(nèi)存的隨機寫,也就是說當我們順序?qū)懭氪疟P是,是可能比內(nèi)存效率還要高。假設(shè)是如果基于內(nèi)存的話,:對象內(nèi)存開銷非常高,并且也會隨著堆內(nèi)數(shù)據(jù)的增加,GC的速度越來越慢。
綜合對比:
硬盤相對于內(nèi)存來說,無論擴展還是成本穩(wěn)定性優(yōu)勢更明顯,可以保存更長,所以的存儲方式選用了磁盤進行順序?qū)憽?/p>存儲設(shè)計及查找過程
那么我們來看下,具體的存儲設(shè)計。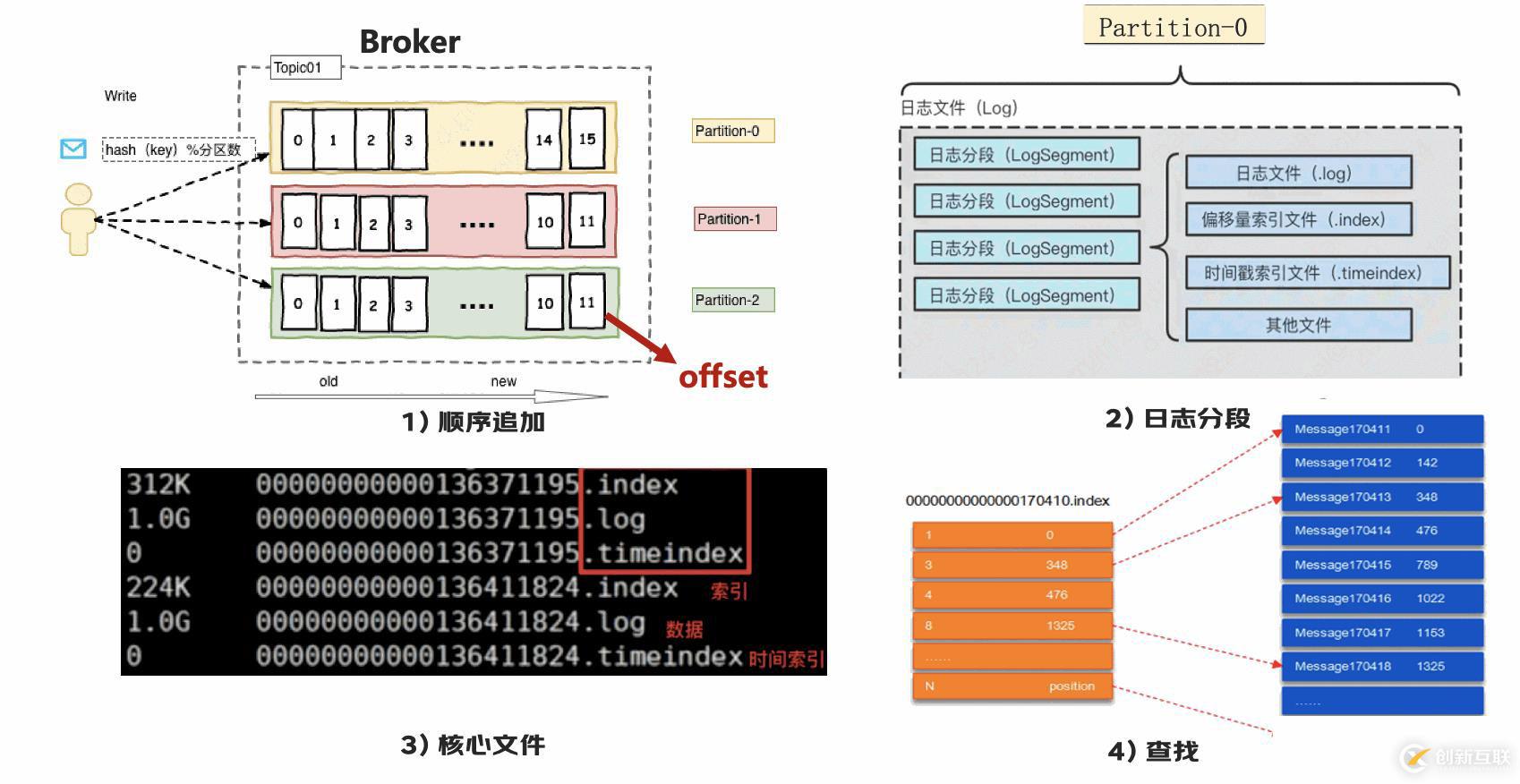
【圖1】生產(chǎn)者生產(chǎn)的消息落到這個分區(qū)之后,會順序的追加到這里,每條數(shù)據(jù)都有自己的 offset。
【圖2】每個分區(qū)對應于一個log 文件。為防止 log 文件過大導致數(shù)據(jù)定位效率低下,將每個 partition 分為多個 segment。每個 segment里對應這樣幾個文件。
【圖3】這幾個文件都以為當前 segment的第一條消息的 offset 命名
【圖4】通過索引可以定位到對應的文件位置。
【小優(yōu)化】這里有個優(yōu)化是,為了減少文件大小,index采用稀疏索引,大約每往log文件寫入4kb數(shù)據(jù),會往index文件寫入一條索引。那如果我想找圖4 里,offset為2的,我就先通過索引1找到對應的日志文件,然后再去進行遍歷。
從圖里看到的問題來了:
a 消息順序性(限單分區(qū)內(nèi) 局部順序):
從這樣的存儲結(jié)構(gòu)里,我們能看到消息在存儲過程是有順序的,但是只局限于這一個分區(qū)上。比如我發(fā)送了兩條消息。一條消息到分區(qū)0 ,一條消息到分區(qū)1 那有順序么,保證不了,因為不在一個隊列里排序。
b IO競爭:
另一點上,因為順序?qū)懀源疟P的效率非常高,但是如果單臺機器上的Partition 數(shù)量太多,會發(fā)生多個文件同時IO的情況,會引起IO競爭,性能大幅下降。所以單機Partatio數(shù)量需要適度(就是具體是多少,這也不好說)。
這里我們對比一下。這兩個在存儲上都有借鑒kafka,又都有不同的改造。
RocketMQ :
在同一個Broker上,所有的數(shù)據(jù)(包括不同topic的數(shù)據(jù))都記錄在同一個文件中(CommitLog)。這樣不就避免了IO的問題么?全部線性來寫。這樣效率高了,但是對比kafka來說,又靈活性低了。比如我想按照topic定制不同的存儲時間。它就做不到了。
Jmq4 :
比他們更晚,它在這一點取了兩者的平衡。在同一個Broker上,按topic分類,然后同一個topic下對應一組消息文件(Log Files),順序存放這個Topic的消息。然后收到的消息按照對應的Topic寫入依次追加寫入消息文件中,然后異步創(chuàng)建索引并寫入對應Partition的索引文件中。
各有優(yōu)劣,都是在靈活性和性能之間取一個平衡。
小結(jié)
接下來說生產(chǎn)者這部分。看看生產(chǎn)者這邊要考慮哪些事情:
首先消息發(fā)送到哪,這是生產(chǎn)者發(fā)送的時候就可以決定了。有這樣幾種方式。
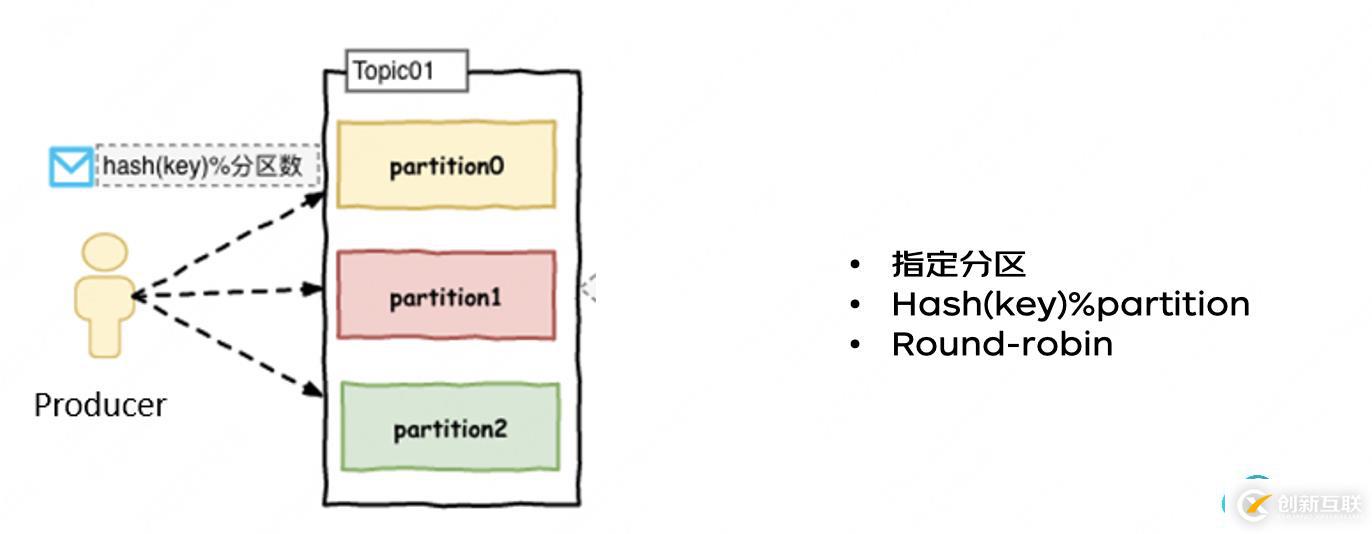
- 指定分區(qū)
- Hash(key)%partition
- Round-robin
比如想保持相對的順序性,可以按照一個維度去hash,保證比如同一個訂單落到同一個分區(qū)里,這樣大部分情況下就是有序的。
第二問 怎么知道發(fā)送成功了大家說這個問題很簡單。就發(fā)送之后有返回碼唄。 集群給個回應不就行了。
是的。那這個回應是什么時候給呢?

從最簡單的消息系統(tǒng)說起
等等,先心里想一個答案再接著看分析:
- A 發(fā)過去就完事了, 這樣吞吐率最高。但是萬一沒成功 消息就丟了
- B leader 收到之后 ,follower還沒來得及同步數(shù)據(jù) 。Leader 就掛掉了-》數(shù)據(jù)丟了
- C 半數(shù)以上。也就是這一半的機器沒都掛掉,就還有數(shù)據(jù)。容災能容這一半,這個看著很合理(實際上kafka沒有這個選項)
- D 全部follower 同步之后 ,好處是 只要有一臺機器沒掛,消息就不會丟。但是缺點是如果有一臺機器故障 一直沒有收到呢?(實際上kafka也沒有這個選項)
如果要保證可靠性,確保消息不丟失那答案是:

那什么是ISR列表:
ISR(In-sync-replicas):在同步中的副本,維護機制是:如果在replica.lag.time.max.ms時間內(nèi)系統(tǒng)沒有發(fā)送fetch請求,或者已經(jīng)在發(fā)送請求,但是在該限定時間內(nèi)沒有趕上Leader的數(shù)據(jù)就被剔除ISR列表。
(在Kafka-0.9.0版本剔除replica.lag.max.messages消息個數(shù)限定,因為這個會導致其他的Broker節(jié)點頻繁的加入和退出ISR。)
想想有了這樣的列表,是不是比固定的半數(shù)還是全部機器都要靈活和靠譜。實際上這個返回值什么時候返回,也是可配的,看場景:
好了,到這里,我們知道如果配置了 acks=all,那發(fā)送的消息就不會丟失了,
但是如果我這樣設(shè)置了,可是給返回的時候機器掛了,那生產(chǎn)者還要重新發(fā)送一個消息,這樣不就重復了么。那么消息可以避免重復么?
也就是語義上 正好一次。
嗯,kafka在這方面也是做了一些努力的!

這是什么意思呢?這個原理是什么呢?
我們首先來看下為什么會重復,

不重復的原理就是有一個唯一ID,然后這樣當?shù)诙温涞椒謪^(qū)的時候,發(fā)現(xiàn)一樣了,就不再重新寫入了
但是這樣也有一個問題:問題再這個唯一ID,是由PID 和 SequenceNumber組成的。而PID是在服務啟動的時候。也就是說重啟PID就變了。那重啟之后趕上消息重新發(fā)送,這時候消息就重復了。還有沒有辦法解決呢?
有。
kafka后續(xù)迭代的版本里增加了事務。當然事務不止是為了解決這個問題)
圖不用細看 ==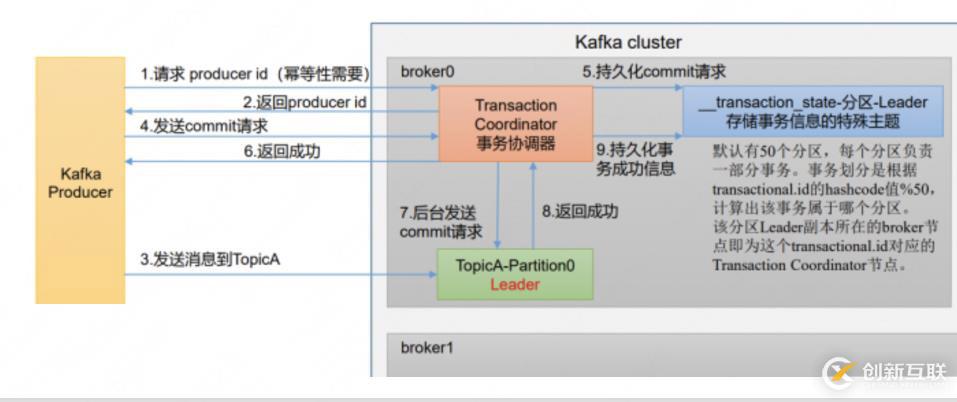
先給結(jié)論:
冪等+事務,實現(xiàn)生產(chǎn)者恰好一次語義
怎么做到的呢?
為了實現(xiàn)事務,應用程序必須提供全局唯一的transactionalId,這通過客戶端參數(shù)顯示設(shè)置。
有了這個ID,那如果發(fā)送返回結(jié)果失敗了,事務要么等恢復了繼續(xù)原來的事務,我們這個事務回滾。恢復的話,因為事務ID可以直接對應到原來的消息ID,這樣的話,我們就可以知道這個消息是重復的。 回滾的話,原來寫入消息就回滾了,重新發(fā)送就行,也不會重復。

第一問 Push or pull消費者這邊,要考慮哪些事情呢?

第一個問題是 消息模型里兩種經(jīng)典方式,Push or pull 。
kafka 選用哪種方式。分析一下:
Push :很難適應消費速率不同的消費者,因為消息發(fā)送速率是由 broker 決定的。它的目標是盡可能以最快速度傳遞消息,但是這樣很容易造成 consumer 來不及處理消息,拒絕服務。
pull :可以根據(jù) consumer 的消費能力以適當?shù)乃俾氏M消息。pull 模式不足之處是,如果 kafka 沒有數(shù)據(jù),消費者可能會陷入循環(huán)中,一直返回空數(shù)據(jù)。
【小優(yōu)化】👉🏻 針對這一點,Kafka 的消費者在消費數(shù)據(jù)時會傳入一個時長參數(shù) timeout,如果當前沒有數(shù)據(jù)可供消費,consumer 會等待一段時間之后再返回,這段時長即為 timeout。
第二問 消費哪個分區(qū)我知道消息是拉取了,那我有個消費者,這么多分區(qū),我該消費哪個呢?有什么規(guī)則么?有,這幾種分區(qū)策略: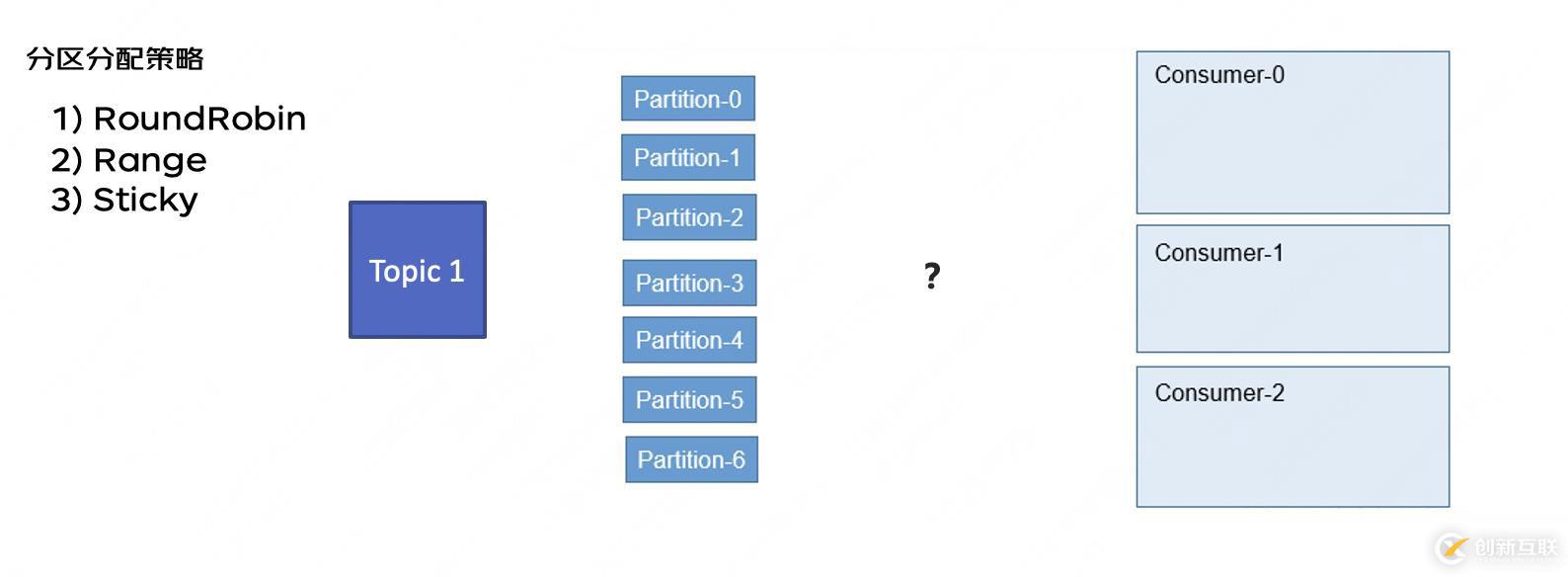
但是這里有一點需要注意并且很重要的是,因為kafka一個分區(qū)只能對應一組消費者里的一個。

【重要】所以單純增加消費者數(shù)量到一定程度后無法增加消費速度。
比如這種情況 不論是哪種分配策略,都一定是只有2個消費者在同時工作。
第三問 從哪條消息開始消費
我們知道每個消息有個offset ,通過offset就能知道從哪消費。那么這個offset 應該是誰來維護呢,消費者還是生產(chǎn)者 還是哪里?這肯定不能是消費端,因為一旦機器重啟,這消息就丟了。但是也需要消費者消費完之后說一聲。這樣服務端才知道你消費完了。
offset 提交機制有兩種:

這就是我們常遇到這個問題。就是消費者到底是要自動提交offset 還是手動提交?分析一下:
a : 設(shè)置自動提交之后,間隔一段時間就提交一次告訴服務端我消費到這里了。但是問題是,如果你消費的慢,可能這時候這消息還沒消費完。那機器故障消息就丟了。另外,我已經(jīng)消費完了,但是還沒到自動提交時間,機器宕機了。那服務端不知道你消費到這里了。那下次等重啟之后,又重新消費了,重了。
1 自動提交 offset ——》 可能丟失,重復
2手動提交 offset ——》 不丟失,可能重復

所以說,消費端這邊是可以做到不丟失,但是不保證不重復,還是需要業(yè)務冪等。
三特性及其具體保證1高可用及水平擴展第三部分是了解了基本原理之后,我們再來整體看下 kafka特性 以及對其都做了哪些設(shè)計

這部分內(nèi)容做個回顧,在上文架構(gòu)圖里有提。(略)
2高吞吐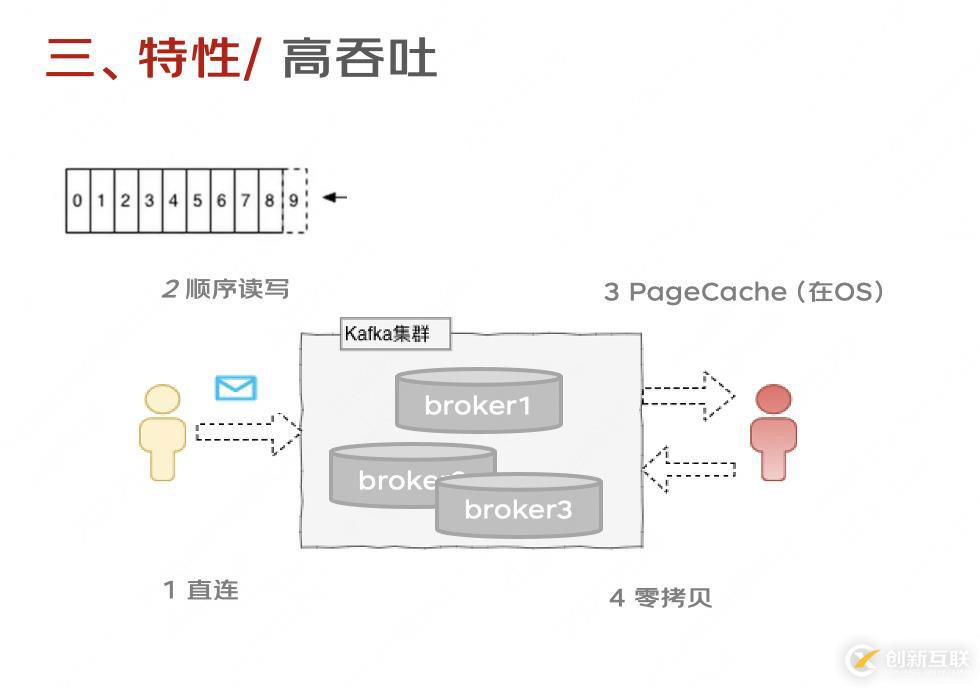
我們具體看下高吞吐的保證:
1-4 也可以理解為保證低延遲 , 就是生產(chǎn)到消費的時間盡可能的短:
5-7 是盡可能的多。這樣就比較好理解了。
這有什么特點?因為kafka是直接通過生產(chǎn)端來進行了負載均衡,沒有引入其他的負載均衡中間件。因為,確實是有其他MQ組件來單獨用的負載均衡中間件。身份證號就不報了。感興趣的可以去查查
2 順序?qū)?p>這點存儲里已經(jīng)提過啦。3 PageCache在 Kafka 中,大量使用了 PageCache, 當一個進程準備讀取磁盤上的文件內(nèi)容時,操作系統(tǒng)會先查看待讀取的數(shù)據(jù)頁是否在 PageCache 中,如果命中則直接返回數(shù)據(jù),從而避免了對磁盤的 I/O 操作;如果沒有命中,操作系統(tǒng)則會向磁盤發(fā)起讀取請求并將讀取的數(shù)據(jù)頁存入 PageCache 中,之后再將數(shù)據(jù)返回給進程。
4 零拷貝于Linux 系統(tǒng)調(diào)用機制,就是跳過“用戶緩沖區(qū)”的拷貝,建立一個磁盤空間和內(nèi)存的直接映射,數(shù)據(jù)不再復制到“用戶態(tài)緩沖區(qū)”系統(tǒng)上下文切換減少為2次,可以提升至少一倍的性能

在實際應用中,如果我們需要把磁盤中的某個文件內(nèi)容發(fā)送到遠程服務器上,那么它必須要經(jīng)過幾個拷貝的過程:見圖一
從磁盤中讀取目標文件內(nèi)容拷貝到內(nèi)核緩沖區(qū),CPU控制器再把內(nèi)核緩沖區(qū)的數(shù)據(jù)復制到用戶空間的緩沖區(qū)中;接著在應用程序中,把用戶空間緩沖區(qū)中的數(shù)據(jù)拷貝到內(nèi)核下的Socket Buffer中。
最后,把在內(nèi)核模式下的SocketBuffer中的數(shù)據(jù)賦值到網(wǎng)卡緩沖區(qū)(NIC Buffer);網(wǎng)卡緩沖區(qū)再把數(shù)據(jù)傳輸?shù)侥繕朔掌魃稀?/p>
在這個過程中我們可以發(fā)現(xiàn),數(shù)據(jù)從磁盤到最終發(fā)送出去,要經(jīng)歷4次拷貝,而在這四次拷貝過程中,有兩次拷貝是浪費的,而零拷貝,就是把這兩次多于的拷貝省略掉,應用程序可以直接把磁盤中的數(shù)據(jù)從內(nèi)核中直接傳輸給Socket,而不需要再經(jīng)過應用程序所在的用戶空間。
見上圖二所示。
壓縮也是為了減少文件的大小,注意是批量,一批進行統(tǒng)一的壓縮。
1)kafka的發(fā)送端將消息按照批量(如果批量設(shè)置一條或者很小,可能有相反的效果)的方式進行壓縮。
2)服務器端直接將壓縮消息保存(如果kafka的版本不同,也存在broker需要先解壓縮再壓縮的問題)
3)消費端自動解壓縮
kafka支持三種壓縮算法,lz4、snappy、gzip。
6 批量發(fā)送“避免過多的小 I/O 操作”
在很多情況下,系統(tǒng)的瓶頸不是CPU或磁盤,而是網(wǎng)絡IO,所以降低大量小的 I/O:使消息消息分批發(fā)送會使整個吞吐量得到明細的提升。
一臺機器的吞吐有限,我還可以用N臺。
總結(jié)今天主要寫了一些kafka基本的原理及其高吞吐的保障。希望能對看到這里的同學有一些幫助 🤦🏻?♀? 。如果有哪里不對的地方,歡迎大家提出來~
然后,點個贊再走啊!! 🌚
1 官方文檔 kafka design: https://kafka.apache.org/documentation/#design
2 部分圖引自網(wǎng)絡。
你是否還在尋找穩(wěn)定的海外服務器提供商?創(chuàng)新互聯(lián)www.cdcxhl.cn海外機房具備T級流量清洗系統(tǒng)配攻擊溯源,準確流量調(diào)度確保服務器高可用性,企業(yè)級服務器適合批量采購,新人活動首月15元起,快前往官網(wǎng)查看詳情吧
分享標題:再有人問你kafka把這篇扔給他(建議收藏)-創(chuàng)新互聯(lián)
標題URL:http://chinadenli.net/article26/hhccg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供品牌網(wǎng)站設(shè)計、標簽優(yōu)化、網(wǎng)站內(nèi)鏈、App開發(fā)、全網(wǎng)營銷推廣、網(wǎng)站改版
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 諷刺別人模仿自己的話模仿拍的照片算不算原創(chuàng)?-創(chuàng)新互聯(lián)
- Java添加、讀取、修改、刪除Word文檔屬性-創(chuàng)新互聯(lián)
- 怎么樣在云服務器上部署web項目-創(chuàng)新互聯(lián)
- Android版微信跳一跳小游戲如何使用技術(shù)手段達到高分-創(chuàng)新互聯(lián)
- C++教程DirectX11Frame屬性-創(chuàng)新互聯(lián)
- Linux系統(tǒng)怎么隱藏文件夾和文件-創(chuàng)新互聯(lián)
- 獲取進程號并賦值判斷進程狀態(tài)-創(chuàng)新互聯(lián)

- 品牌網(wǎng)站設(shè)計開發(fā)要點 2016-11-09
- 品牌網(wǎng)站設(shè)計的意義是什么,如何起到這種效果? 2022-09-30
- 怎樣做成都品牌網(wǎng)站設(shè)計才有效果? 2016-12-27
- 品牌網(wǎng)站設(shè)計優(yōu)越性提升企業(yè)建站水平 2021-04-18
- 創(chuàng)新互聯(lián)設(shè)計師談品牌網(wǎng)站設(shè)計中色彩如何運用 2023-02-18
- 品牌網(wǎng)站設(shè)計如何達到展示目的 2013-09-04
- 品牌網(wǎng)站設(shè)計有哪些問題要注意? 2020-12-26
- 品牌網(wǎng)站設(shè)計四大核心制作要素 2022-08-15
- 深圳福田網(wǎng)站設(shè)計與制作,品牌網(wǎng)站設(shè)計制作的步驟是什么? 2021-11-20
- 企業(yè)品牌網(wǎng)站設(shè)計思路介紹 2023-01-29
- 【網(wǎng)站設(shè)計】品牌網(wǎng)站設(shè)計的一般布局 2016-11-21
- 品牌網(wǎng)站設(shè)計的流程有哪些 2023-02-13